
CDA數(shù)據(jù)分析師 出品
作者:Mika、真達(dá)
數(shù)據(jù):真達(dá)
后期:澤龍
【導(dǎo)讀】今天我們用數(shù)據(jù)來聊一聊口味蝦�����。
Show me data��,用數(shù)據(jù)說話
今天我們聊一聊 口味蝦
說起湖南這個(gè)地方���,大家想到的肯定是各種吃的���,最常聽到的就是臭豆腐����,外焦里嫩,聞起來臭吃起來香��,一口下去讓人回味無窮�����。

還有香甜軟糯的糖油粑粑�����,炸至金黃的糯米,外面裹著糖漿����。

還有就是口味蝦了,口味蝦又叫麻辣小龍蝦����。在夏天的時(shí)候,邀上三五好友�,來上幾盤口味蝦,搭配上啤酒��,肥宅的生活就這么快樂的開始了����,味道麻辣爽口,一口下去就想吃下一口!在湖南��,沒有吃上口味蝦的夏天都是不完整的�。
那么湖南的吃貨們都喜歡吃哪家的口味蝦呢?今天我們就用數(shù)據(jù)來盤一盤。

我們使用Python獲取了大眾點(diǎn)評(píng)上長(zhǎng)沙口味蝦店鋪的相關(guān)信息����,進(jìn)行了數(shù)據(jù)分析,整體流程如下:
網(wǎng)絡(luò)數(shù)據(jù)獲取
數(shù)據(jù)讀入
數(shù)據(jù)探索與可視化
K-means聚類分析
01數(shù)據(jù)讀入
首先導(dǎo)入所需包,并讀入獲取的數(shù)據(jù)集���。
# 導(dǎo)入包
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
import jieba
from pyecharts.charts import Bar, Pie, Page
from pyecharts import options as opts
from pyecharts.globals import SymbolType, WarningType
WarningType.ShowWarning = False
import plotly.express as px
import plotly.graph_objects as go
此數(shù)據(jù)集包含50個(gè)搜索頁面共745條數(shù)據(jù)�,字段包含:餐廳名���、星級(jí)���、星級(jí)評(píng)分、評(píng)論數(shù)�����、人均消費(fèi)��、推薦菜�����、口味�、環(huán)境和服務(wù)得分��。
數(shù)據(jù)預(yù)覽如下:
# 讀入數(shù)據(jù)
df = pd.read_excel('../data/長(zhǎng)沙小龍蝦數(shù)據(jù).xlsx')
df.drop('detail_url', axis=1. inplace=True)
df.head()

02數(shù)據(jù)預(yù)處理
此處我們對(duì)數(shù)據(jù)進(jìn)行如下處理以便后的分析工作���。
title: 去除前后符號(hào)
star:提取星級(jí)
score: 提取數(shù)值����,轉(zhuǎn)換為類別型
comment_list:提取口味、環(huán)境����、服務(wù)得分
刪除多余的行和列
# 星級(jí)轉(zhuǎn)換
transform_star = {
20: '二星',
30: '三星',
35: '準(zhǔn)四星',
40: '四星',
45: '準(zhǔn)五星',
50: '五星'
}
# 處理title
df['title'] = df['title'].str.replace(r"\[\'|\'\]", "")
# star處理
df['star'] = df.star.str.extract(r'(\d+)')[0].astype('int')
df['star_label'] = df.star.map(transform_star)
# 處理score
df['score'] = df['score'].str.replace(r"\[\'|\'\]", "").replace("[]", np.nan)
df['score'] = df['score'].astype('float')
# 口味
df['taste'] = df.comment_list.str.split(',').str[0].str.extract(r'(\d+\.*\d+)').astype('float')
# 環(huán)境
df['environment'] = df.comment_list.str.split(',').str[1].str.extract(r'(\d+\.*\d+)').astype('float')
# 服務(wù)
df['service'] = df.comment_list.str.split(',').str[1].str.extract(r'(\d+\.*\d+)').astype('float')
# 刪除列
df.drop('comment_list', axis=1. inplace=True)
# 刪除行
df.dropna(subset=['taste'], axis=0. inplace=True)
# 刪除記錄少的
df = df[df.star!=20]
處理之后的數(shù)據(jù)如下,分析樣本為560條。
df.head()

03數(shù)據(jù)可視化
以下展示部分可視化代碼:
1不同星級(jí)店鋪數(shù)量分布
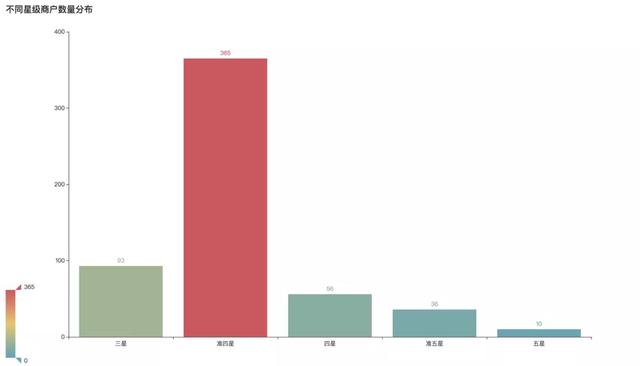
準(zhǔn)四星商戶最多�����,占比高達(dá)65%�,超過四星以上的商戶占比18%,其中五星商戶數(shù)量最少�����,僅有10家��。
# 產(chǎn)生數(shù)據(jù)
star_num = df.star.value_counts().sort_index(ascending=True)
x_data = star_num.index.map(transform_star).tolist()
y_data = star_num.values.tolist()
# 條形圖
bar1 = Bar(init_opts=opts.InitOpts(width='1350px', height='750px'))
bar1.add_xaxis(x_data)
bar1.add_yaxis('', y_data)
bar1.set_global_opts(title_opts=opts.TitleOpts(title='不同星級(jí)商戶數(shù)量分布'),
visualmap_opts=opts.VisualMapOpts(max_=365)
)
bar1.render()
2店鋪評(píng)論數(shù)分布
我們假設(shè)評(píng)論數(shù)目為店鋪的熱度��,也就是它越火��,消費(fèi)人數(shù)越多��,評(píng)論數(shù)目越多。
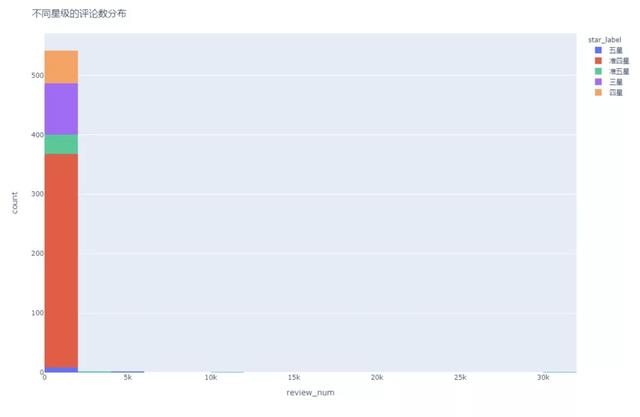
從直方圖中可以看出�,數(shù)據(jù)呈現(xiàn)比較嚴(yán)重的右偏分布,其中超過1萬評(píng)論的僅有兩家��,我們挑選出來看一下����,發(fā)現(xiàn)這兩家都是超級(jí)文和友,超級(jí)文和友是長(zhǎng)沙網(wǎng)紅打卡地��,國(guó)慶期間一天排16000+個(gè)號(hào)的超級(jí)網(wǎng)紅龍蝦館����,難怪熱度會(huì)這么高。
# 直方圖
px.histogram(data_frame=df , x='review_num', color='star_label', histfunc='sum',
title='不同星級(jí)的評(píng)論數(shù)分布',
nbins=20. width=1150. height=750)
3人均價(jià)格區(qū)間分布
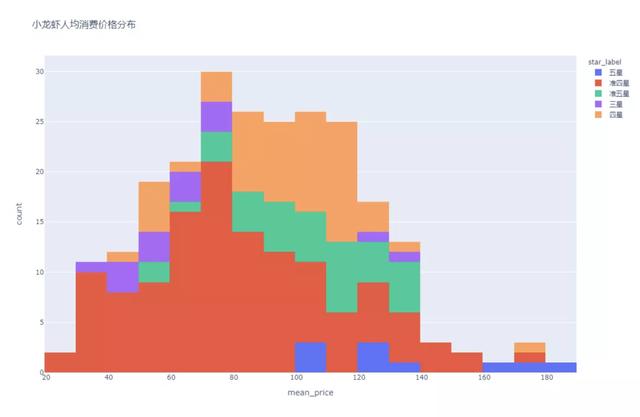
我們繪制了所有店鋪口味蝦人均消費(fèi)價(jià)格分布的直方圖�����,發(fā)現(xiàn)價(jià)格分布在20~180元之間�����,其中人均消費(fèi)大部分都在67-111元的區(qū)間內(nèi)�����。擴(kuò)展看��,人均消費(fèi)和商戶的星級(jí)有關(guān)系嗎?
# 直方圖
px.histogram(data_frame=df , x='mean_price', color='star_label', histfunc='sum',
title='小龍蝦人均消費(fèi)價(jià)格分布', nbins=20. width=1150. height=750)
4不同星級(jí)店鋪與價(jià)格等因素的關(guān)系
不同星級(jí)與價(jià)格的關(guān)系
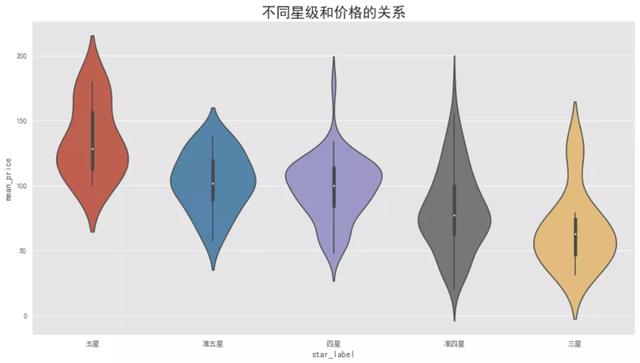
這里繪制了星級(jí)和價(jià)格分布的小提琴圖��,用來展示多組數(shù)據(jù)的分布狀態(tài)以及概率密度�����。從圖形可以看出��,不同星級(jí)和價(jià)格之間的分布有顯著差異�����,表現(xiàn)為星級(jí)越高����,平均消費(fèi)價(jià)格越高。
# 小提琴圖
plt.figure(figsize=(15. 8))
sns.violinplot(x='star_label', y='mean_price', data=df,
order=['五星', '準(zhǔn)五星', '四星', '準(zhǔn)四星', '三星']
);
plt.title('不同星級(jí)和價(jià)格的關(guān)系', fontsize=20)
plt.show()
不同星級(jí)和其他得分項(xiàng)的關(guān)系
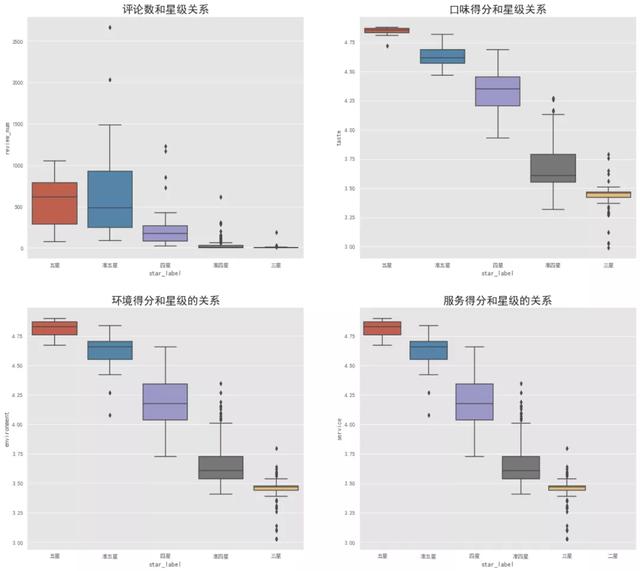
我們預(yù)想���,星級(jí)評(píng)價(jià)越好����,它在口味��、環(huán)境和服務(wù)的得分越高,熱度也就越高���,從繪制出來的箱線圖也可以驗(yàn)證我們的這一假設(shè)�。
那么店鋪得分與口味���、環(huán)境�、服務(wù)����、評(píng)論數(shù)量����、平均價(jià)格有關(guān)系嗎?接下來我們繪制一張多變量圖看一下。
4數(shù)值型變量關(guān)系
多變量圖用于探索數(shù)值型變量之間的關(guān)系�����,從多變量圖可以看出:
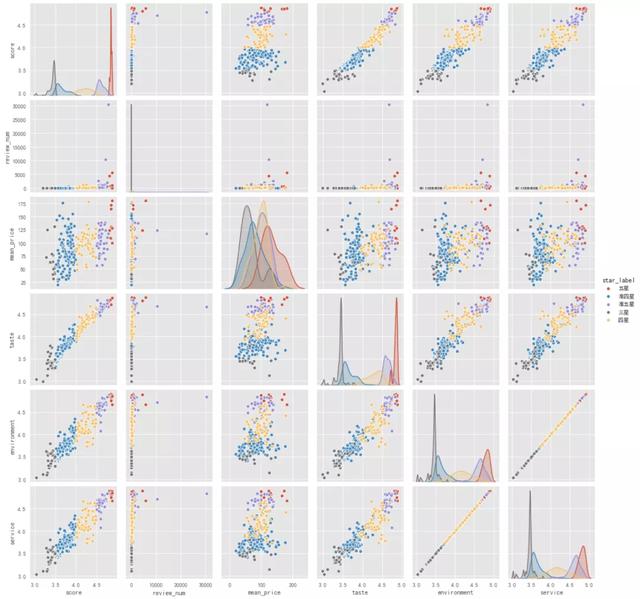
店鋪得分與口味���、環(huán)境��、服務(wù)得分呈現(xiàn)較為顯著的線性相關(guān)��,這也和之前的驗(yàn)證一致;
店鋪得分和人均消費(fèi)價(jià)格�����、評(píng)論數(shù)量關(guān)系不顯著;
口味���、環(huán)境、服務(wù)得分之間有顯著的正相關(guān)����,三者存在高則同高的情況。
# 多變量圖
sns.pairplot(data=df[['score', 'review_num', 'mean_price', 'taste', 'environment', 'service', 'star_label']]
, hue='star_label')
plt.show()
數(shù)值型變量之間的相關(guān)系數(shù)
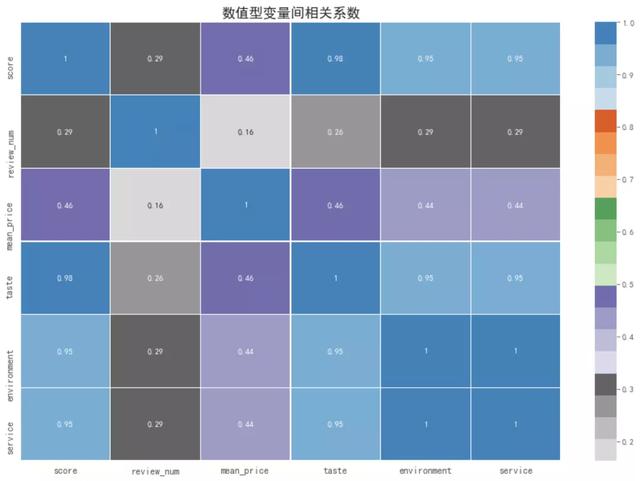
為了驗(yàn)證上述可視化的結(jié)果���,我們通過Python計(jì)算數(shù)值型變量之間的pearson相關(guān)系數(shù)�����,根據(jù)經(jīng)驗(yàn)�,|r|>=0.8時(shí)����,可視為高相關(guān)。從熱力圖中也可以得到上述結(jié)論�。
# 相關(guān)系數(shù)
data_corr = df[['score', 'review_num', 'mean_price', 'taste', 'environment', 'service']].corr()
# 熱力圖
plt.figure(figsize=(15. 10))
sns.heatmap(data_corr, linewidths=0.1. cmap='tab20c_r', annot=True)
plt.title('數(shù)值型變量間相關(guān)系數(shù)', fontdict={'fontsize': 'xx-large', 'fontweight':'heavy'})
plt.xticks(fontsize=12)
plt.yticks(fontsize=12)
plt.show()
5推薦菜詞云圖
假設(shè)店鋪的推薦菜就是不同店鋪的熱門菜�����,我們使用jieba對(duì)推薦菜進(jìn)行分詞并繪制詞云圖:

發(fā)現(xiàn)"鹵蝦"���、"口味蝦"、"油爆蝦"是大家愛點(diǎn)的熱門菜���。另外大家點(diǎn)口味蝦的同時(shí)也愛點(diǎn)"口味花甲"���、"鳳爪"、"牛油"之類的串兒等菜��。
6K-means聚類分析群集占比
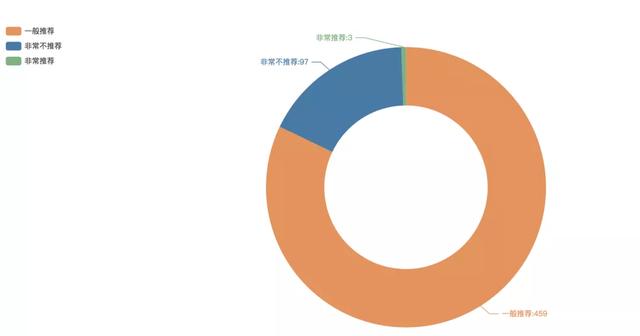
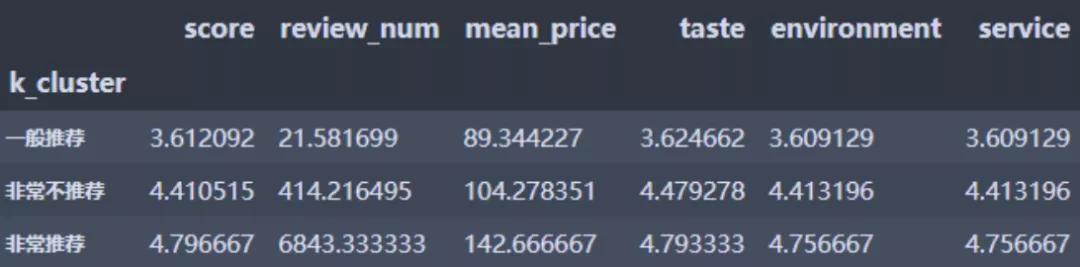
聚類分析用于將樣本做群集劃分�,同一集群內(nèi)成員的相似性要愈高愈好, 而不同集群間成員的相異性則要愈高愈好��。我們使用Python進(jìn)行了K-means聚類����,對(duì)數(shù)值型變量:得分、評(píng)論數(shù)�����、平均價(jià)格、口味���、環(huán)境、服務(wù)評(píng)論做群集劃分���,這里取K為3.得到以上三群�,其中非常推薦的數(shù)量有3家����,一般推薦的459家,非常不推薦的有97家�����。我們看一下這三群的描述性統(tǒng)計(jì):
K-means聚類分析分布
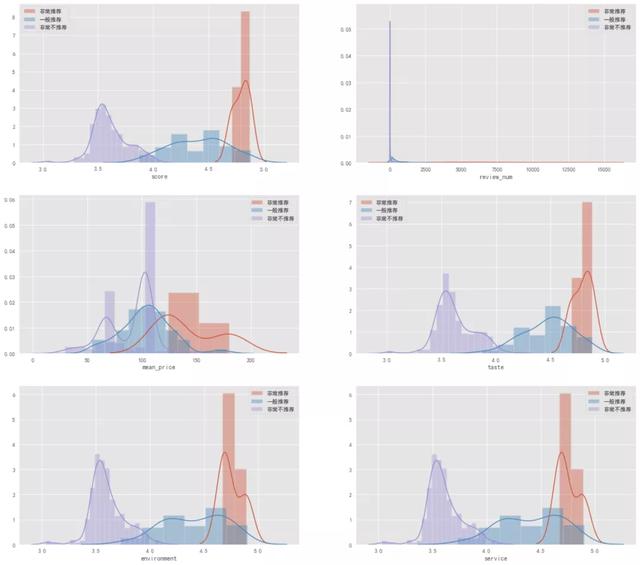
以上是不同群集的直方圖分布����,通過群集分布圖,可以總結(jié)如下:
非常推薦:各項(xiàng)得分最高��、評(píng)論數(shù)最多�����、價(jià)格最高
一般推薦:各項(xiàng)得分居中、評(píng)論數(shù)居中����、價(jià)格居中
非常不推薦:各項(xiàng)得分最低、評(píng)論數(shù)最低�����、價(jià)格最低
由于在做聚類分析時(shí)候去除了一個(gè)評(píng)論數(shù)為30509.0的異常樣本��。加上這條樣本���,得到最終推薦的四家店鋪:

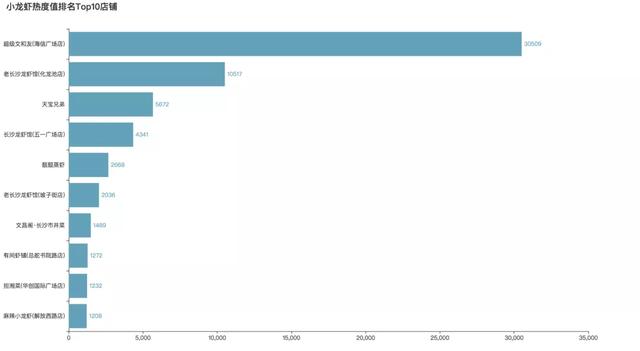
最后附上大眾點(diǎn)評(píng)上熱度值Top10的口味蝦店����,看看有沒有你種草的店吧~
想要獲取完整數(shù)據(jù)�,可以私信或者留言哦。
CDA數(shù)據(jù)分析師考試相關(guān)入口一覽(建議收藏):
? 想報(bào)名CDA認(rèn)證考試���,點(diǎn)擊>>>
“CDA報(bào)名”
了解CDA考試詳情�����;
? 想學(xué)習(xí)CDA考試教材�����,點(diǎn)擊>>> “CDA教材” 了解CDA考試詳情�;
? 想加入CDA考試題庫(kù),點(diǎn)擊>>> “CDA題庫(kù)” 了解CDA考試詳情����;
? 想了解CDA考試含金量����,點(diǎn)擊>>> “CDA含金量” 了解CDA考試詳情;











 京公網(wǎng)安備 11010802034615號(hào)
經(jīng)營(yíng)許可證編號(hào):京B2-20210330
京公網(wǎng)安備 11010802034615號(hào)
經(jīng)營(yíng)許可證編號(hào):京B2-20210330