集成算法(Emseble Learning)是構建多個學習器�����,然后通過一定策略將這些學習器組合起來�,讓它們來完成學習任務的�,通?�?梢垣@得比單一學習顯著優(yōu)越的學習器���。
常見的集成算法模型有:Bagging、Boosting���、Stacking�。下面小編對這三種模型進行簡單的介紹�。
1.Bagging的原理首先是在自助采樣法(bootstrap sampling)的基礎上�����,隨機得到一些樣本集訓練���,分別對不同的基學習器進行訓練,然后對不同的基學習器得到的結果投票,從而得出最終的分類結果�����。自助采樣法得到的樣本大概會有63%的數(shù)據(jù)樣本被使用,剩下的可以用來做驗證集。
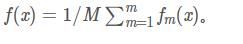

Bagging最典型代表是:隨機森林
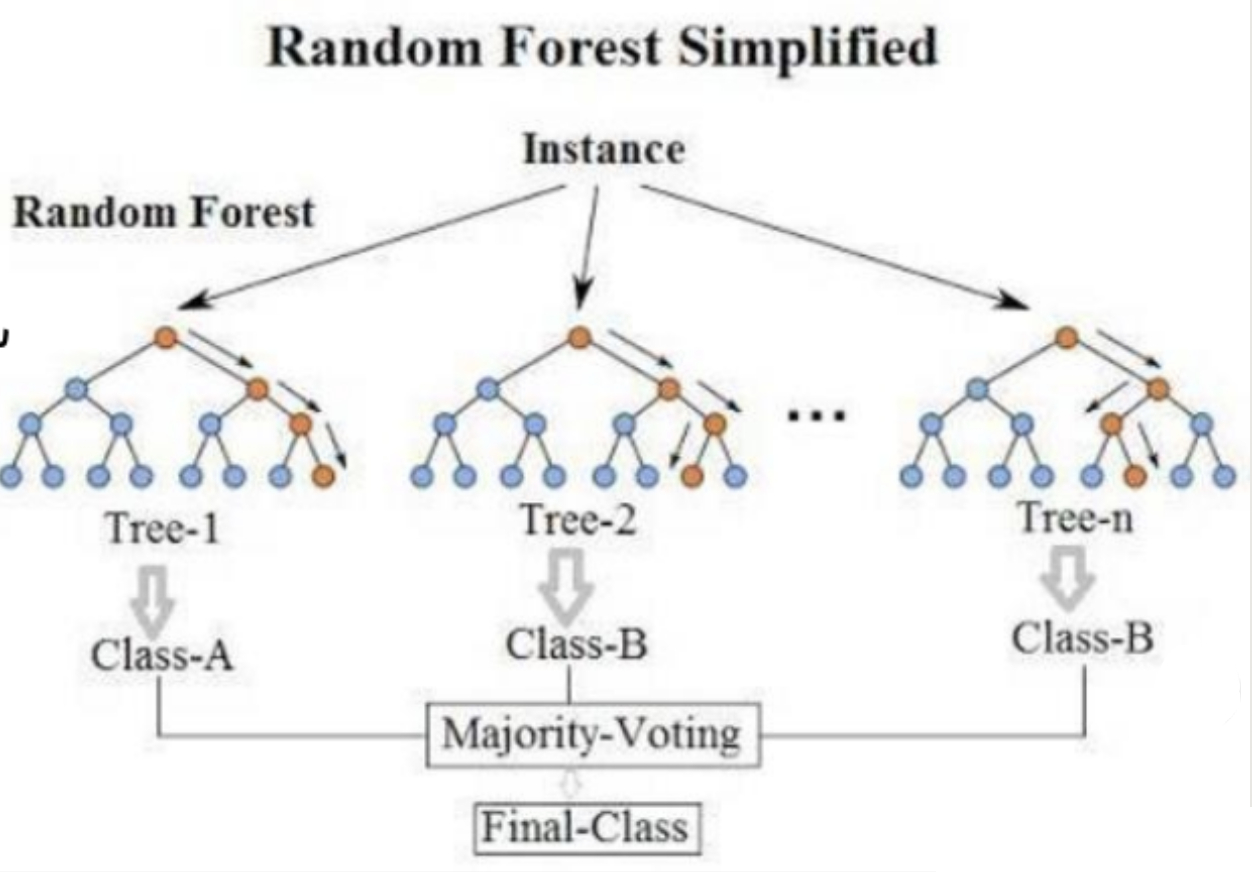
隨機森林,需要分為隨機和 森林來進行理解
隨機就是每個分類器的數(shù)據(jù)采樣和選擇特征都是隨機的,但是數(shù)量都是一樣的,而且都是有放回的選取
森林,就是決策樹,多個決策樹也就構成了森林�����。
2.Boosting 串行:以一個弱分類器開始,然后不斷增加分類器�,以權重參數(shù)表示其重要性
本思想是“逐步強化”����。計算過程為:
所有樣本權重相同��,訓練得到第一個弱分類器�。
根據(jù)上一輪的分類效果���,調整樣本的權重�,上一輪分錯的樣本權重提高�����,重新進行訓練。
重復以上步驟���,直到達到約定的輪數(shù)結束��。
由于處于分類邊界的點容易分錯����,因此會得到更高的權重���。
典型代表是AdaBoost�����、XgBoost算法���。
3.Stacking 堆疊:聚合使用多個分類器
計算過程:
使用多個分類器各自獨立進行第一輪的的訓練,然后測試得到第一輪的結果���,
緊接著將第一輪的訓練結果作為第二輪的訓練輸入���,得出結果
不斷迭代���,直到達到迭代的次數(shù)限制為止。
優(yōu)點:
Stacking綜合使用了多個分類器�,準確率很高,
第一輪中多個分類器獨立訓練�,較好地避免了過擬合的現(xiàn)象出現(xiàn)。
缺點:效率非常低
CDA數(shù)據(jù)分析師考試相關入口一覽(建議收藏):
? 想報名CDA認證考試����,點擊>>>
“CDA報名”
了解CDA考試詳情;
? 想學習CDA考試教材�,點擊>>> “CDA教材” 了解CDA考試詳情;
? 想加入CDA考試題庫����,點擊>>> “CDA題庫” 了解CDA考試詳情�����;
? 想了解CDA考試含金量�,點擊>>> “CDA含金量” 了解CDA考試詳情;











 京公網(wǎng)安備 11010802034615號
經(jīng)營許可證編號:京B2-20210330
京公網(wǎng)安備 11010802034615號
經(jīng)營許可證編號:京B2-20210330