
最近這部《隱秘的角落》徹底火了��,目前在豆瓣高達(dá)8.9分��,有45萬余人進(jìn)行了評論。
一時間劇中張東升那句「爬山」�����、「你說我還有機(jī)會嗎」 承包了6月份的梗���。各種表情包和段子齊飛��。


作為主演秦昊當(dāng)年的同學(xué)��,章子怡都出來打call。

刷完劇�����,那首「小白船」簡直成了新的恐怖童謠���,讓人在腦海中無限循環(huán)�����,太上頭了���。

那么這部制作精良的國產(chǎn)劇為何能收獲到觀眾的一致好評?大家在看劇時都在討論些什么��?今天我們就用數(shù)據(jù)來帶你看看���。
01拿拍電影的態(tài)度拍網(wǎng)劇 ,不好看才怪
該劇改編自紫金陳推理小說《壞小孩》 �����,講述了沿海小城的三個孩子在景區(qū)游玩時無意拍攝記錄了一次謀殺����,他們的冒險也由此展開。撲朔迷離的案情�,將幾個家庭裹挾其中�,帶向不可預(yù)知的未來......

劇剛開始的畫面就是,文質(zhì)彬彬的男青年帶著一對老人在山頂拍照,二老坐在石頭上,背后就是萬丈深淵��,男青年上前親自指導(dǎo)姿勢��,而就在一瞬間,他眼神一冷���,兩只手同時發(fā)力�,將二老從山頂推了下去�,甚至在推完還在佯作驚慌失措的樣子大喊:“爸!媽����!”而這一切卻被三個游玩的小孩無意拍了下來���。

這一開場就把觀眾嚇了一跳���,甚至都起了雞皮疙瘩。同時也讓人欲罷不能想看看接下來會發(fā)生什么故事。
劇情不拖沓�,演技全員在線
不同于國產(chǎn)劇一般動輒四五十集的篇幅�����,《隱秘的角落》只有短短的12集,故事緊湊,劇情毫不拖泥帶水。
而整部劇中,無論是從挑大梁的秦昊,到三位小演員�,還是王景春、張頌文等一眾演員都奉獻(xiàn)出了無可挑剔的演技。
令人印象深刻的配樂
配樂也是《隱秘的角落》中的亮點(diǎn)之一。配合影視劇的懸疑劇情�����,這些配樂聽起來確實(shí)分外驚悚恐怖���,也給大家留下了不可磨滅的陰影,被網(wǎng)友調(diào)侃:“能不能整點(diǎn)陽間的音樂����?”如果問為什么本劇配樂這么講究����,要知道《隱秘的角落》的導(dǎo)演辛爽可是樂隊(duì)音樂人出身的����。

02豆瓣8.9分 年度國劇之光���!
首先�,我們看到豆瓣的數(shù)據(jù)。這部劇一開播在豆瓣評分就沖上9.0分�,一度沖到9.2分,隨著劇集完結(jié)��,目前穩(wěn)定在8.9分��,已經(jīng)有45萬余人進(jìn)行了評分��。

總體評分
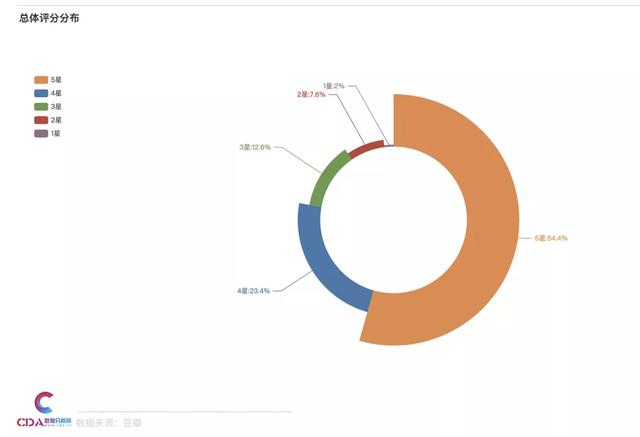
細(xì)看評分的分布可以發(fā)現(xiàn)����,有54.4%的人都給出了五星好評,其次23.4%的人給出四星���。這個成績還是很不錯的�。
評論熱度走勢圖
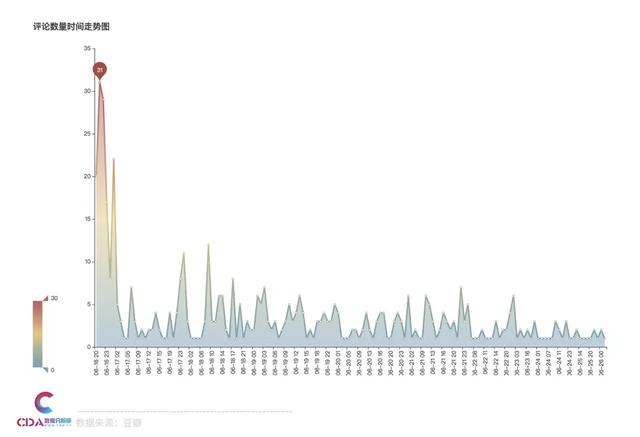
從評論走勢圖可以看到����,《隱秘的角落》在6月16日首播,評論熱度最高����。之后不同于其他劇,隨著播出時間評論數(shù)量趨于平緩�,這部劇再播出后也不時帶來熱度,引發(fā)觀眾的評論潮����。
評論中提及主演
大家在評論時都提到哪些角色了呢?
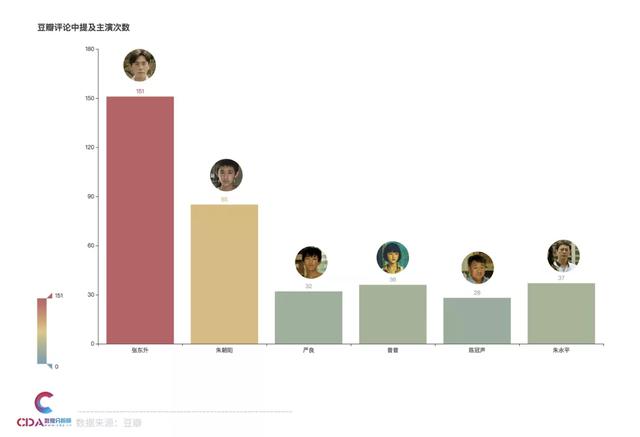
分析發(fā)現(xiàn)����,主演張東升的討論度果然是最高的,其次是三個小演員之一的朱朝陽��。演技派演員王景春和張頌文飾演的陳警官和朝陽爸爸討論度也很高����。
主演評價分布
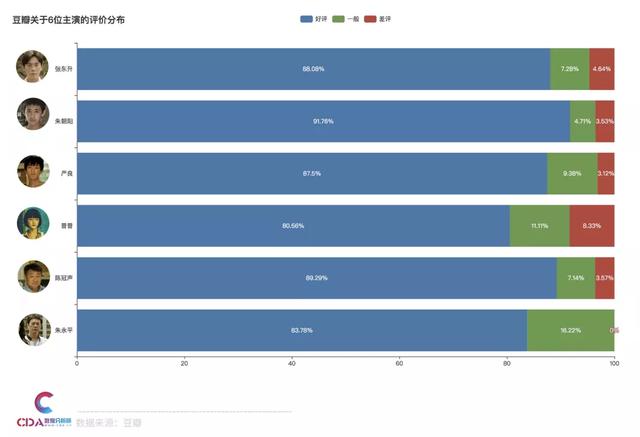
我們分析了豆瓣短評中用戶關(guān)于主演的好評/一般/差評分布占比。
細(xì)致到個人表演來看����,小演員們的表現(xiàn)相當(dāng)突出,比如朱朝陽的扮演者榮梓杉����,有超過9成的觀眾肯定了他的表現(xiàn)��。秦昊�����、王景春兩位的表現(xiàn)自然也是很厲害的�����。他們在劇中的表現(xiàn)�����,分別獲得了88.08%和89.29%的好評率�����。
0320萬條彈幕告訴你
追劇時大家都在說些什么��?
接下來我們分析一下《隱秘的角落》在愛奇藝的彈幕數(shù)據(jù)���,我們分析整理了全部12集的彈幕,共200672條��。下面看到分析結(jié)論:
用戶使用的彈幕角色
觀眾在愛奇藝追劇發(fā)彈幕時����,可以選擇自己喜歡的角色頭像�。那么觀眾都最喜歡用哪些用人物角色發(fā)彈幕呢���?
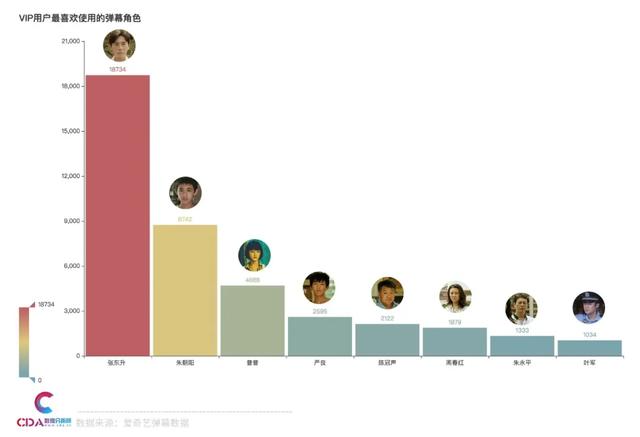
可以看到,這方面張東升在這方面是榜首����。其次是朱朝陽,然后可愛的小妹妹普普位居第三����。
彈幕字?jǐn)?shù)分布
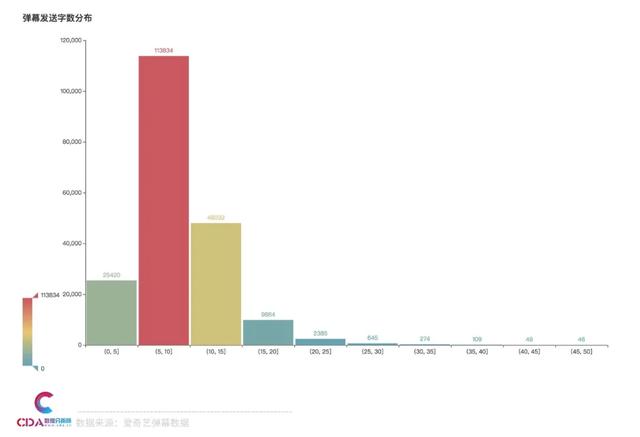
在彈幕的字?jǐn)?shù)上我們可以看到,5-10個字的是最多的�,共有11萬余條彈幕。其次是10-15個字��,48032條彈幕�����。0-5個字的彈幕也有不少��,共25420條��。可見在追劇發(fā)彈幕時��,大家還是傾向多說點(diǎn)��,表達(dá)自己的想法�����。
整體彈幕詞云

在整體彈幕詞云中����,「孩子」、「嚴(yán)良」���、「普普」被提到的頻率很高���。看到三位小主演的一舉一動還是牽動著觀眾的心的�����。
接下來�����,我們分別看到幾位主演的人物彈幕詞云吧。
張東升

首先就是張東升了�,不同于一般臉譜化的反派角色。在張東升的身上�����,大家既看到他的冷酷���,兇殘,也看到他的無奈和隱忍���。在彈幕中����,關(guān)于他����,提到「爬山」、「機(jī)會」的特別多�����,這幾句張東升的話實(shí)在太出圈了�。
有意思的是�����,張東升的「頭發(fā)」也被頻頻提及��,畢竟這個禿頭造型實(shí)在是太令人印象深刻了����。

朱朝陽

下面再看到三位小主演中最受關(guān)注的朱朝陽���。品學(xué)兼優(yōu)的他�����,因?yàn)楦改鸽x異性格有些內(nèi)向和孤僻��。在詞云中�����,他與「爸爸」�����、「媽媽」的感情也是大家討論最多的��。其次他與「張東升」間的對手戲�,以及后面他角色的「黑化」也是討論焦點(diǎn)。
普普

劇中的小妹妹普普也是很多人喜歡的角色了�,在詞云中可以看到觀眾對她的「喜歡」,以及對她「演技」的肯定����。此外,「善良」等詞也常被提到�����。
嚴(yán)良

劇中的另一位小演員角色——嚴(yán)良也是彈幕中關(guān)注度很高的�。關(guān)于他��,大家經(jīng)常會提到跟他形影不離的「普普」�,此外「演技不錯」「厲害」等詞也頻出。
04教你用Python分析愛奇藝彈幕數(shù)據(jù)
我們使用Python獲取并分析愛奇藝的彈幕數(shù)據(jù)�,整個數(shù)據(jù)分析的流程分為以下三個部分:
下面看到具體步驟:
首先導(dǎo)入所需包,其中pandas用于數(shù)據(jù)讀入和數(shù)據(jù)處理���,os用于文件操作��,jieba用于中文分詞��,pyecharts和stylecolud用于數(shù)據(jù)可視化��。
# 導(dǎo)入庫
import pandas as pd
import os
import jieba
from pyecharts.charts import Bar, Pie, Line, WordCloud, Page
from pyecharts import options as opts
from pyecharts.globals import SymbolType, WarningType
WarningType.ShowWarning = False
import stylecloud
from IPython.display import Image
我們將爬取的數(shù)據(jù)存放在data文件夾下�,使用os操作獲取需要讀取的csv文件列表。
# 文件列表
data_list = os.listdir('../data/')
data_list
['df_第一集.csv',
'df_第七集.csv',
'df_第三集.csv',
'df_第九集.csv',
'df_第二集.csv',
'df_第五集.csv',
'df_第八集.csv',
'df_第六集.csv',
'df_第十一集.csv',
'df_第十二集.csv',
'df_第十集.csv',
'df_第四集.csv']
然后使用pandas將csv文件讀入并循環(huán)追加到總表df_all中�����,打印以下數(shù)據(jù)集大小看一下�,一共有200672條。
# 存儲數(shù)據(jù)
df_all = pd.DataFrame()
# 循環(huán)寫入
for i in data_list:
df_one = pd.read_csv(f'../data/{i}', engine='python', encoding='utf-8', index_col=0)
df_all = df_all.append(df_one, ignore_index=False)
# 打印數(shù)據(jù)集大小
print(df_all.shape)
(200672, 6)
再預(yù)覽一下前五行數(shù)據(jù)�。
# 預(yù)覽數(shù)據(jù)
df_all.head()
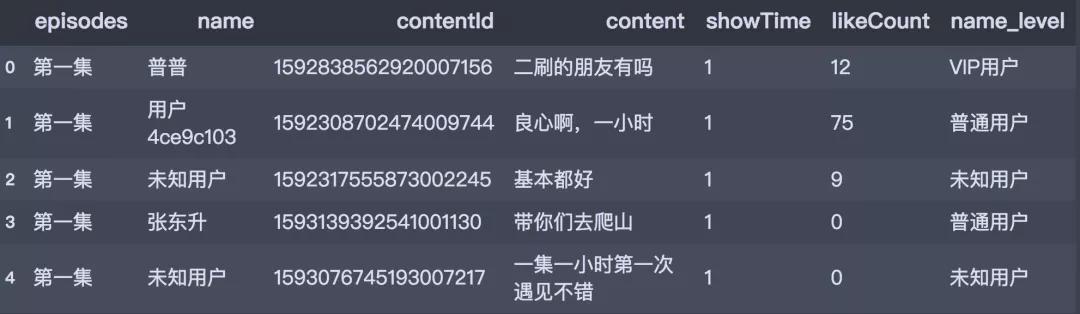
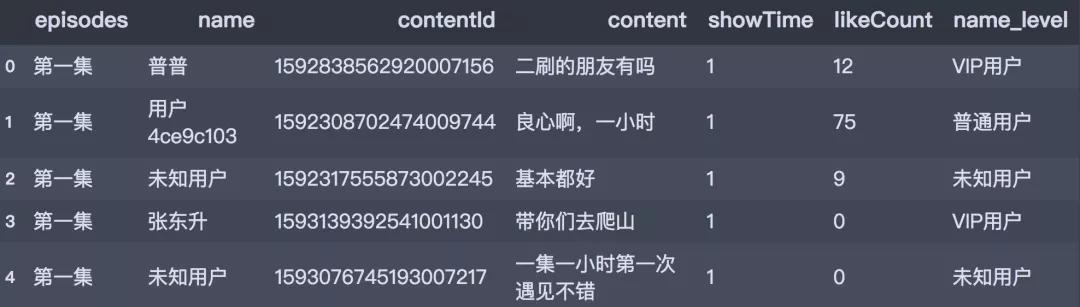
數(shù)據(jù)讀入之后,接下來簡單對數(shù)據(jù)集進(jìn)行預(yù)處理的工作�����,我們針對name字段進(jìn)行以下處理:使用strip操作去除字符串前后的空格���;定義一個轉(zhuǎn)換函數(shù)��,根據(jù)name字段新增name_level字段����,標(biāo)注用戶等級,效果如下:
# 字符串處理
df_all['name'] = df_all.name.str.strip()
def transform_name(x):
if x=='張東升' or x=='朱朝陽' or x=='普普' or x=='嚴(yán)良' or x=='陳冠聲' or x=='周春紅' or x=='朱永平' or x=='葉軍':
return 'VIP用戶'
elif x=='未知用戶':
return '未知用戶'
else:
return '普通用戶'
# 新增列
df_all['name_level'] = df_all.name.apply(transform_name)
df_all.head()
接下來使用pyecharts進(jìn)行數(shù)據(jù)可視化�。主要分析內(nèi)容包含:
-
用戶最喜歡使用的彈幕角色-條形圖
-
彈幕發(fā)送字?jǐn)?shù)分布-條形圖
-
彈幕角色-詞云圖
首先統(tǒng)計(jì)不同等級用戶的數(shù)量。
level_num = df_all.name_level.value_counts()
level_num
未知用戶 157722
VIP用戶 41127
普通用戶 1823
Name: name_level, dtype: int64
使用pyecharts中的Pie類繪制餅圖���,效果如下:
data_pair = [list(z) for z in zip(level_num.index.tolist(), level_num.values.tolist())]
# 繪制餅圖
pie1 = Pie(init_opts=opts.InitOpts(width='1350px', height='750px'))
pie1.add('', data_pair, radius=['35%', '60%'])
pie1.set_global_opts(title_opts=opts.TitleOpts(title='彈幕發(fā)送人群等級分布'),
legend_opts=opts.LegendOpts(orient='vertical', pos_top='15%', pos_left='2%'))
pie1.set_series_opts(label_opts=opts.LabelOpts(formatter="�:geybsqlxm7mc%"))
pie1.set_colors(['#3B7BA9', '#6FB27C', '#FFAF34'])
pie1.render()
name字段中標(biāo)注了用戶發(fā)送彈幕時候使用的彈幕角色����,統(tǒng)計(jì)并篩選不同彈幕角色的使用頻次。
role_num = df_all.name.value_counts()[1:9]
role_num
張東升 18734
朱朝陽 8742
普普 4688
嚴(yán)良 2595
陳冠聲 2122
周春紅 1879
朱永平 1333
葉軍 1034
Name: name, dtype: int64
然后使用pyecharts中的Bar類繪制一張餅圖����。
# 柱形圖
bar1 = Bar(init_opts=opts.InitOpts(width='1350px', height='750px'))
bar1.add_xaxis(role_num.index.tolist())
bar1.add_yaxis("", role_num.values.tolist(), category_gap='5%')
bar1.set_global_opts(title_opts=opts.TitleOpts(title="VIP用戶最喜歡使用的彈幕角色"),
visualmap_opts=opts.VisualMapOpts(max_=18734),
)
bar1.render()
content字段記錄了用戶評論的彈幕信息,此處根據(jù)這個字段計(jì)算字?jǐn)?shù)并按照步長5進(jìn)行分箱處理��,得到不同字?jǐn)?shù)段下的頻次分布��。
word_num = df_all.content.apply(lambda x:len(x))
# 分箱
bins = [0, 5, 10, 15, 20, 25, 30, 35, 40, 45, 50]
word_num_cut = pd.cut(word_num, bins, include_lowest=False).value_counts()
word_num_cut = word_num_cut.sort_index()
word_num_cut
(0, 5] 25420
(5, 10] 113834
(10, 15] 48032
(15, 20] 9864
(20, 25] 2385
(25, 30] 645
(30, 35] 274
(35, 40] 109
(40, 45] 49
(45, 50] 46
Name: content, dtype: int64
同樣使用Bar類繪制一張條形圖����。
# 柱形圖
bar2 = Bar(init_opts=opts.InitOpts(width='1350px', height='750px'))
bar2.add_xaxis(word_num_cut.index.astype('str').tolist())
bar2.add_yaxis("", word_num_cut.values.tolist(), category_gap='4%')
bar2.set_global_opts(title_opts=opts.TitleOpts(title="彈幕發(fā)送字?jǐn)?shù)分布"),
visualmap_opts=opts.VisualMapOpts(max_=113834),
)
bar2.render()
接下來我們定義一個分詞函數(shù)get_cut_words�,這個函數(shù)的功能是傳入一列數(shù)據(jù),得到使用jieba分詞之后的列表��。
# 定義分詞函數(shù)
def get_cut_words(content_series):
# 讀入停用詞表
stop_words = []
with open(r"C:\Users\wzd\Desktop\CDA\CDA_Python\Python文本分析\10.文本摘要\stop_words.txt", 'r', encoding='utf-8') as f:
lines = f.readlines()
for line in lines:
stop_words.append(line.strip())
# 添加關(guān)鍵詞
my_words = ['秦昊', '張東升', '王景春', '陳冠聲', '榮梓杉',
'朱朝陽', '史彭元', '嚴(yán)良', '王圣迪', '普普',
'岳普', '張頌文', '朱永平', '十二集', '十二萬',
'十二時辰']
for i in my_words:
jieba.add_word(i)
# 自定義停用詞
my_stop_words = ['真的', '這部', '這是', '一種', '那種',
'哈哈哈']
stop_words.extend(my_stop_words)
# 分詞
word_num = jieba.lcut(content_series.str.cat(sep='。'), cut_all=False)
# 條件篩選
word_num_selected = [i for i in word_num if i not in stop_words and len(i)>=2]
return word_num_selected
將角色張東升的彈幕數(shù)據(jù)傳入函數(shù)�,得到分詞之后的列表。
text1 = get_cut_words(content_series=df_all[df_all.name=='張東升']['content'])
text1[:5]
Building prefix dict from the default dictionary ...
Dumping model to file cache C:\Users\wzd\AppData\Local\Temp\jieba.cache
Loading model cost 1.280 seconds.
Prefix dict has been built successfully.
['爬山', '老弟', '十二集', '知足', '伊能靜']
然后使用stylecloud工具包繪制一張心形的詞云圖���,效果如下:

# 繪制詞云圖
stylecloud.gen_stylecloud(text=' '.join(text1), max_words=1000,
collocations=False,
font_path=r'?C:\Windows\Fonts\msyh.ttc',
icon_name='fas fa-heart',
size=653,
output_name='./詞云圖/彈幕角色-張東升詞云圖.png')
Image(filename='./詞云圖/彈幕角色-張東升詞云圖.png')
CDA數(shù)據(jù)分析師考試相關(guān)入口一覽(建議收藏):
? 想報(bào)名CDA認(rèn)證考試����,點(diǎn)擊>>>
“CDA報(bào)名”
了解CDA考試詳情��;
? 想學(xué)習(xí)CDA考試教材�����,點(diǎn)擊>>> “CDA教材” 了解CDA考試詳情�;
? 想加入CDA考試題庫,點(diǎn)擊>>> “CDA題庫” 了解CDA考試詳情��;
? 想了解CDA考試含金量���,點(diǎn)擊>>> “CDA含金量” 了解CDA考試詳情�;











 京公網(wǎng)安備 11010802034615號
經(jīng)營許可證編號:京B2-20210330
京公網(wǎng)安備 11010802034615號
經(jīng)營許可證編號:京B2-20210330