作者 | Jason Brownlee
編譯 | CDA數(shù)據(jù)分析師
特征選擇是在開發(fā)預(yù)測模型時(shí)減少輸入變量數(shù)量的過程���。
希望減少輸入變量的數(shù)量����,以減少建模的計(jì)算成本���,并且在某些情況下���,還需要改善模型的性能��。
基于特征的特征選擇方法包括使用統(tǒng)計(jì)信息評(píng)估每個(gè)輸入變量和目標(biāo)變量之間的關(guān)系����,并選擇與目標(biāo)變量關(guān)系最密切的那些輸入變量�����。盡管統(tǒng)計(jì)方法的選擇取決于輸入和輸出變量的數(shù)據(jù)類型����,但是這些方法可以快速有效。
這樣����,當(dāng)執(zhí)行基于過濾器的特征選擇時(shí),對于機(jī)器學(xué)習(xí)從業(yè)者來說�����,為數(shù)據(jù)集選擇適當(dāng)?shù)慕y(tǒng)計(jì)量度可能是具有挑戰(zhàn)性的��。
在本文中�,您將發(fā)現(xiàn)如何為統(tǒng)計(jì)數(shù)據(jù)和分類數(shù)據(jù)選擇統(tǒng)計(jì)度量,以進(jìn)行基于過濾器的特征選擇����。
閱讀這篇文章后,您將知道:
-
特征選擇技術(shù)主要有兩種類型:包裝器和過濾器方法���。
-
基于過濾器的特征選擇方法使用統(tǒng)計(jì)量度對可以過濾以選擇最相關(guān)特征的輸入變量之間的相關(guān)性或依賴性進(jìn)行評(píng)分�����。
-
必須根據(jù)輸入變量和輸出或響應(yīng)變量的數(shù)據(jù)類型仔細(xì)選擇用于特征選擇的統(tǒng)計(jì)量度��。
總覽
本教程分為三個(gè)部分:他們是:
-
特征選擇方法
-
篩選器特征選擇方法的統(tǒng)計(jì)信息
-
功能選擇提示和技巧
特征選擇方法旨在將輸入變量的數(shù)量減少到被認(rèn)為對模型最有用的那些變量����,以預(yù)測目標(biāo)變量����。
一些預(yù)測性建模問題包含大量變量,這些變量可能會(huì)減慢模型的開發(fā)和訓(xùn)練速度����,并需要大量的系統(tǒng)內(nèi)存。此外����,當(dāng)包含與目標(biāo)變量無關(guān)的輸入變量時(shí)�,某些模型的性能可能會(huì)降低���。
特征選擇算法有兩種主要類型:包裝器方法和過濾器方法�����。
包裝器特征選擇方法會(huì)創(chuàng)建許多具有不同輸入特征子集的模型�,并根據(jù)性能指標(biāo)選擇那些導(dǎo)致最佳性能模型的特征。這些方法與變量類型無關(guān)��,盡管它們在計(jì)算上可能很昂貴���。RFE是包裝功能選擇方法的一個(gè)很好的例子��。
包裝器方法使用添加和/或刪除預(yù)測變量的過程來評(píng)估多個(gè)模型�����,以找到使模型性能最大化的最佳組合����。
—第490頁,應(yīng)用預(yù)測建模��,2013年�。
過濾器特征選擇方法使用統(tǒng)計(jì)技術(shù)來評(píng)估每個(gè)輸入變量和目標(biāo)變量之間的關(guān)系,這些分?jǐn)?shù)將用作選擇(過濾)將在模型中使用的那些輸入變量的基礎(chǔ)����。
過濾器方法在預(yù)測模型之外評(píng)估預(yù)測變量的相關(guān)性��,然后僅對通過某些標(biāo)準(zhǔn)的預(yù)測變量進(jìn)行建模��。
—第490頁�����,應(yīng)用預(yù)測建模�,2013年。
通常在輸入和輸出變量之間使用相關(guān)類型統(tǒng)計(jì)量度作為過濾器特征選擇的基礎(chǔ)����。這樣,統(tǒng)計(jì)量度的選擇高度依賴于可變數(shù)據(jù)類型�。
常見的數(shù)據(jù)類型包括數(shù)字(例如高度)和類別(例如標(biāo)簽)���,但是每種數(shù)據(jù)類型都可以進(jìn)一步細(xì)分���,例如數(shù)字變量的整數(shù)和浮點(diǎn)數(shù)��,類別變量的布爾值���,有序數(shù)或標(biāo)稱值。
常見的輸入變量數(shù)據(jù)類型:
-
數(shù)值變量
-
整數(shù)變量�����。
-
浮點(diǎn)變量���。
-
分類變量
-
布爾變量(二分法)�����。
-
序數(shù)變量����。
-
標(biāo)稱變量�����。
對變量的數(shù)據(jù)類型了解得越多,就越容易為基于過濾器的特征選擇方法選擇適當(dāng)?shù)慕y(tǒng)計(jì)量度�。
在下一部分中����,我們將回顧一些統(tǒng)計(jì)量度,這些統(tǒng)計(jì)量度可用于具有不同輸入和輸出變量數(shù)據(jù)類型的基于過濾器的特征選擇�����。
基于過濾器的特征選擇方法的統(tǒng)計(jì)信息
在本節(jié)中�,我們將考慮兩大類變量類型:數(shù)字和類別��;同樣����,要考慮的兩個(gè)主要變量組:輸入和輸出�。
輸入變量是作為模型輸入提供的變量����。在特征選擇中��,我們希望減小這些變量的大小����。輸出變量是模型要預(yù)測的變量�����,通常稱為響應(yīng)變量��。
響應(yīng)變量的類型通常指示正在執(zhí)行的預(yù)測建模問題的類型���。例如�����,數(shù)字輸出變量指示回歸預(yù)測建模問題,而分類輸出變量指示分類預(yù)測建模問題���。
-
數(shù)值輸出:回歸預(yù)測建模問題��。
-
分類輸出:分類預(yù)測建模問題��。
通常在基于過濾器的特征選擇中使用的統(tǒng)計(jì)量度是與目標(biāo)變量一次計(jì)算一個(gè)輸入變量����。因此,它們被稱為單變量統(tǒng)計(jì)量度�����。這可能意味著在過濾過程中不會(huì)考慮輸入變量之間的任何交互�����。
這些技術(shù)大多數(shù)都是單變量的���,這意味著它們獨(dú)立地評(píng)估每個(gè)預(yù)測變量。在這種情況下���,相關(guān)預(yù)測變量的存在使選擇重要但多余的預(yù)測變量成為可能�。此問題的明顯后果是選擇了太多的預(yù)測變量�����,結(jié)果出現(xiàn)了共線性問題�����。
—第499頁,應(yīng)用預(yù)測建模��,2013年����。
使用此框架,讓我們回顧一些可用于基于過濾器的特征選擇的單變量統(tǒng)計(jì)量度�。
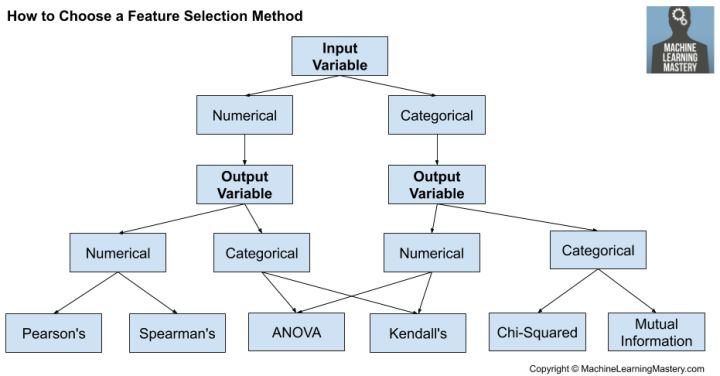
如何選擇機(jī)器學(xué)習(xí)的特征選擇方法
數(shù)值輸入,數(shù)值輸出
這是帶有數(shù)字輸入變量的回歸預(yù)測建模問題����。
最常見的技術(shù)是使用相關(guān)系數(shù),例如使用Pearson進(jìn)行線性相關(guān)��,或使用基于秩的方法進(jìn)行非線性相關(guān)���。
-
皮爾遜相關(guān)系數(shù)(線性)��。
-
Spearman的秩系數(shù)(非線性)
數(shù)值輸入�����,分類輸出
這是帶有數(shù)字輸入變量的分類預(yù)測建模問題�。
這可能是最常見的分類問題示例,
同樣��,最常見的技術(shù)是基于相關(guān)的�����,盡管在這種情況下���,它們必須考慮分類目標(biāo)���。
-
方差分析相關(guān)系數(shù)(線性)。
-
肯德爾的秩系數(shù)(非線性)�����。
Kendall確實(shí)假定類別變量為序數(shù)�����。
分類輸入�����,數(shù)值輸出
這是帶有分類輸入變量的回歸預(yù)測建模問題�����。
這是回歸問題的一個(gè)奇怪示例(例如�����,您不會(huì)經(jīng)常遇到它)����。
不過,您可以使用相同的“ 數(shù)值輸入���,分類輸出 ”方法(如上所述)����,但要相反���。
分類輸入����,分類輸出
這是帶有分類輸入變量的分類預(yù)測建模問題�。
分類數(shù)據(jù)最常見的相關(guān)度量是卡方檢驗(yàn)����。您還可以使用信息論領(lǐng)域的互信息(信息獲?��。?/span>
-
卡方檢驗(yàn)(列聯(lián)表)。
-
相互信息�����。
實(shí)際上�����,互信息是一種強(qiáng)大的方法,可能對分類數(shù)據(jù)和數(shù)字?jǐn)?shù)據(jù)都有用����,例如�,與數(shù)據(jù)類型無關(guān)�。
功能選擇提示和技巧
使用基于過濾器的功能選擇時(shí)�����,本節(jié)提供了一些其他注意事項(xiàng)。
相關(guān)統(tǒng)計(jì)
scikit-learn庫提供了大多數(shù)有用的統(tǒng)計(jì)度量的實(shí)現(xiàn)。
例如:
-
皮爾遜相關(guān)系數(shù):f_regression()
-
方差分析:f_classif()
-
Chi-Squared:chi2()
-
共同信息:Mutual_info_classif()和Mutual_info_regression()
此外�,SciPy庫提供了更多統(tǒng)計(jì)信息的實(shí)現(xiàn)���,例如Kendall的tau(kendalltau)和Spearman的排名相關(guān)性(spearmanr)����。
選擇方式
一旦針對具有目標(biāo)的每個(gè)輸入變量計(jì)算出統(tǒng)計(jì)信息���,scikit-learn庫還將提供許多不同的過濾方法�。
兩種比較流行的方法包括:
-
選擇前k個(gè)變量:SelectKBest
-
選擇頂部的百分位數(shù)變量:SelectPercentile
我經(jīng)常自己使用SelectKBest�����。
轉(zhuǎn)換變量
考慮轉(zhuǎn)換變量以訪問不同的統(tǒng)計(jì)方法。
例如��,您可以將分類變量轉(zhuǎn)換為序數(shù)(即使不是序數(shù)),然后查看是否有任何有趣的結(jié)果��。
您還可以使數(shù)值變量離散(例如�,箱)����;嘗試基于分類的度量。
一些統(tǒng)計(jì)度量假設(shè)變量的屬性,例如Pearson假設(shè)假定觀測值具有高斯概率分布并具有線性關(guān)系���。您可以轉(zhuǎn)換數(shù)據(jù)以滿足測試的期望�����,然后不管期望如何都可以嘗試測試并比較結(jié)果�����。
最好的方法是什么?
沒有最佳功能選擇方法。
就像沒有最佳的輸入變量集或最佳的機(jī)器學(xué)習(xí)算法一樣��。至少不是普遍的。
相反�����,您必須使用認(rèn)真的系統(tǒng)實(shí)驗(yàn)來發(fā)現(xiàn)最適合您的特定問題的方法���。
嘗試通過不同的統(tǒng)計(jì)量度來選擇適合不同特征子集的各種不同模型,并找出最適合您的特定問題的模型���。
CDA數(shù)據(jù)分析師考試相關(guān)入口一覽(建議收藏):
? 想報(bào)名CDA認(rèn)證考試,點(diǎn)擊>>>
“CDA報(bào)名”
了解CDA考試詳情�;
? 想學(xué)習(xí)CDA考試教材����,點(diǎn)擊>>> “CDA教材” 了解CDA考試詳情�;
? 想加入CDA考試題庫,點(diǎn)擊>>> “CDA題庫” 了解CDA考試詳情��;
? 想了解CDA考試含金量,點(diǎn)擊>>> “CDA含金量” 了解CDA考試詳情����;















 京公網(wǎng)安備 11010802034615號(hào)
經(jīng)營許可證編號(hào):京B2-20210330
京公網(wǎng)安備 11010802034615號(hào)
經(jīng)營許可證編號(hào):京B2-20210330