作者 | CDA數(shù)據(jù)分析師
俗話說��,巧婦難為無米之炊���。不管你廚藝有多好,如果沒有食材���,也做不出香甜可口的飯菜來����,所以想要做出飯菜來���,首先要做的就是要買米買菜�����。而數(shù)據(jù)分析就好比是做飯���,首先也應(yīng)該是準(zhǔn)備食材��,也就是獲取數(shù)據(jù)源����。
一�、導(dǎo)入外部數(shù)據(jù)
導(dǎo)入數(shù)據(jù)主要用到的是Pandas里的read_x()方法,x表示待導(dǎo)入文件的格式���。
1、導(dǎo)入.xlsx文件
在Excel中導(dǎo)入.xlsx格式的文件時很簡單的��,雙擊打開就可以了���。在Python中導(dǎo)入.xlsx文件的是read_excel()這種方法���。
(1)基本導(dǎo)入
在導(dǎo)入文件的時候首先要指定文件的路徑,也就是這個文件在電腦中的哪個文件夾下存放著�。

電腦中的文件路徑默認(rèn)是使用\的,這個時候需要在路徑前面加一個r(轉(zhuǎn)義符)避免路徑里面的\被轉(zhuǎn)義��。也可以不加轉(zhuǎn)義符r�����,但是需要把路徑里面所有的\轉(zhuǎn)換成/,這個規(guī)則在導(dǎo)入其他格式文件的時候也是一樣的���,我們一般會選擇在路徑前面加轉(zhuǎn)義符r����。


(2)指定導(dǎo)入哪個Sheet
.xlsx格式的文件可以有很多個Sheet�����,你可以通過設(shè)定sheet_name參數(shù)來指定要導(dǎo)入哪個Sheet的文件���。

除了可以指定具體Sheet的名字���,還可以傳入Sheet的順序,從0開始計數(shù)��。

如果不指定sheet_name參數(shù)的時候����,那么默認(rèn)導(dǎo)入的都是第一個sheet的文件。
(3)指定行索引
將本地文件導(dǎo)入DataFrame的時候��,行索引使用的是從0 開始的默認(rèn)索引�����,可以通過設(shè)置index_col參數(shù)來設(shè)置。

index_col表示用.xlsx文件中的第幾列做行索引���,從0 開始計數(shù)�。
(4)指定列索引
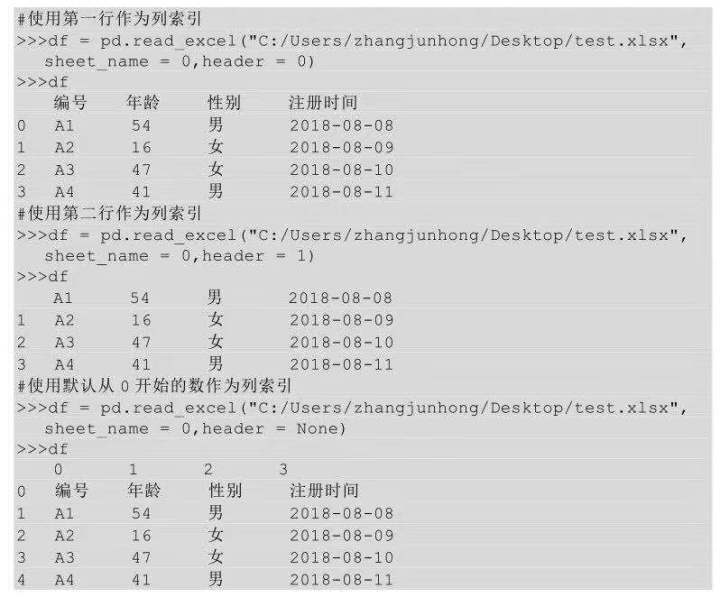
將本地文件導(dǎo)入DataFrame的時候����,默認(rèn)使用的是源數(shù)據(jù)表的第一行作為列索引,也可以通過設(shè)置header參數(shù)來設(shè)置列索引�。header參數(shù)值默認(rèn)為0,即用第一行作為列索引�����;也可以是其他行�����,只需要傳入具體的那一行即可�;也可以使用默認(rèn)從0開始的數(shù)作為列索引����。
(5)指定導(dǎo)入列
有的時候本地文件的列數(shù)太多��,而我們又不需要那么多列的時候�,我們就可以通過設(shè)定usecols參數(shù)來指定要導(dǎo)入的列���。

可以給usecols 參數(shù)具體的某個值��,表示要導(dǎo)入第幾列�,同樣是從0開始計數(shù)�����,也可以以列表的形式傳入多個值����,表示要傳入哪些列。

2��、導(dǎo)入.csv文件
在Excel中導(dǎo)入.csv格式的文件和打開.xlsx格式的問價是一樣的����,雙擊即可。而在Python中導(dǎo)入.csv問價用的方法是read_csv()��。
(1)直接導(dǎo)入
只需要指明文件路徑即可。

(2)指明分隔符號
在Excel和DataFrame中的數(shù)據(jù)都是很規(guī)整的排列的�,這都是工具在后臺根據(jù)某條規(guī)則進行切分的。read_csv()默認(rèn)文件中的數(shù)據(jù)都是以逗號分開的�����,但是有的文件不是用逗號分開的�,這個時候就需要人為指定分隔符號,否則就會報錯��。
新建一個以空格作為分隔符號的文件���,如下圖所示:

如果用默認(rèn)的逗號作為分隔符號�����,看看導(dǎo)入的數(shù)是什么樣的�����。


我們看到所有的數(shù)據(jù)還是一個整體,并沒有被分開���,把分隔符號換成空格以后再看看效果:
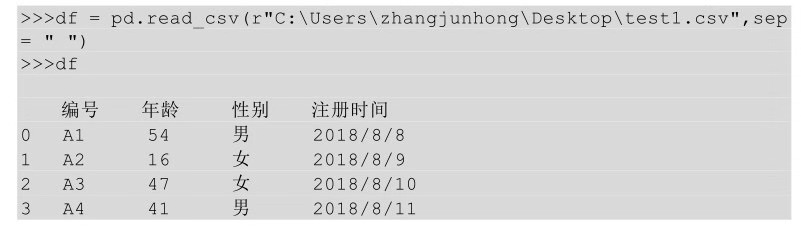
使用正確的分隔符號以后���,數(shù)據(jù)被規(guī)整的分好了�。常見的分隔符號除了逗號��、空格���,還有制表符(\t)����。
(3)指明讀取行數(shù)
假設(shè)現(xiàn)在有一個幾百兆的文件�����,你想了解一下這個文件里有哪些數(shù)據(jù)��,那么這個時候你就沒必要把全部數(shù)據(jù)都導(dǎo)入�,你只要看到前面幾行即可,因此只要設(shè)置nrows參數(shù)即可���。

(4)指定編碼格式
Python用得比較多的兩種編碼格式是UTF-8和gbk����,默認(rèn)編碼格式是UTF-8���。我們要根據(jù)導(dǎo)入文件本身的編碼格式進行設(shè)置����,通過設(shè)置參數(shù)encoding來設(shè)置導(dǎo)入的編碼格式。有的時候兩個文件看起來一樣���,它們的文件名一樣�����,格式一樣�,但是如果它們的編碼格式不一樣�����,也是不一樣的文件��,比如當(dāng)你把一個Excel文件另存為時會出現(xiàn)兩個選項�����,雖然都是.csv文件���,但是這兩種格式代表兩種不同的文件,如下圖所示:
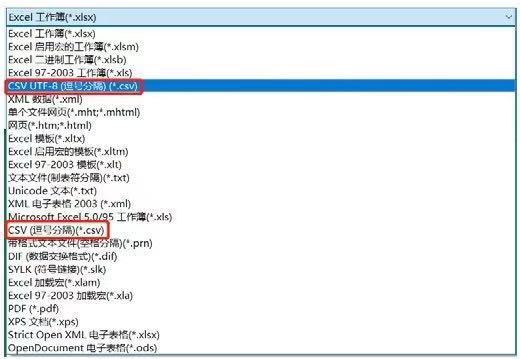
如果CSV UTF-8(逗號分隔)(*.csv)格式的文件,那么導(dǎo)入的時候就需要加encoding參數(shù)����。

你也可以不加encoding參數(shù),因為Python默認(rèn)的編碼格式就是UTF-8��。

如果CSV(逗號分隔)(*.csv)格式的文件����,那么在導(dǎo)入的時候就需要把編碼格式更改為gbk,如果使用UTF-8就會報錯���。

(5)engine指定
當(dāng)文件路徑或者文件名中包含中文時���,如果還用上面的導(dǎo)入方式就會報錯。

這個時候我們就可以通過設(shè)置engine參數(shù)來消除這個錯誤����。這個錯誤產(chǎn)生的原因是當(dāng)調(diào)用read_csv()方法時,默認(rèn)使用C語言作為解析語言�,我們只需要把默認(rèn)值C更改為Python就可以了,如果文件格式是CSV UTF-8(逗號分隔)(*.csv)�����,那么編碼格式也需要跟著變?yōu)閡tf-8-sig,如果文件格式是CSV(逗號分隔)(*.csv)格式����,對應(yīng)的編碼格式則為gbk。

(6)其他
.csv文件也涉及行���、列索引設(shè)置及指定導(dǎo)入某列或者某幾行���,設(shè)定方法與導(dǎo)入.xlsx文件一致。
3����、導(dǎo)入.txt文件
(1)Excel實現(xiàn)
在Excel中導(dǎo)入.txt文件時,我們需要通過依次單擊菜單欄中的數(shù)據(jù)>獲取外部數(shù)據(jù)>自文本����,然后選擇要導(dǎo)入的.txt文件所在的路徑,如下圖所示:

選完路徑以后會出現(xiàn)如下圖所示的界面�,預(yù)覽文件就是我們要導(dǎo)入的文件,確認(rèn)無誤后按下一步按鈕即可����。
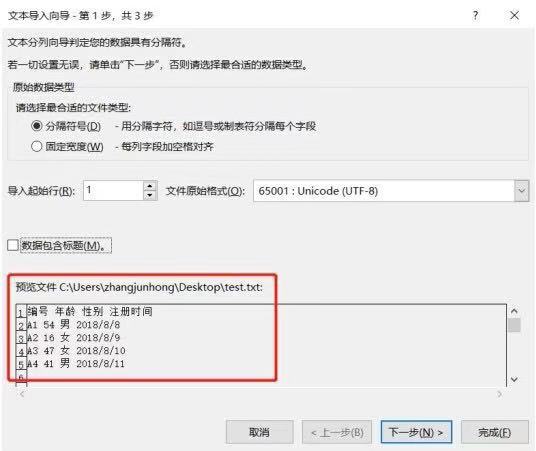
因為我們舉例.txt 文件用空格分開的,所以在分隔符號項勾選空格復(fù)選框�,如果待導(dǎo)入的.txt 文件是用其他分隔符號分隔的�,那么選擇對應(yīng)的分隔符號�,然后直接按完成按鈕即可�����,如下圖所示:

(2)Python實現(xiàn)
在Python中導(dǎo)入.txt文件用的方法是read_table()是將利用分隔符號分開的文件導(dǎo)入DataFrame的通用函數(shù)��。它不僅可以導(dǎo)入.txt文件�,還可以導(dǎo)入.csv文件。

從上面的代碼可以看出���,函數(shù)在導(dǎo)入.csv文件時�����,與read_csv()函數(shù)不同的是�,即使是逗號分隔開的問價也是需要用sep指明分隔符號的���,而不是像read_csv()函數(shù)那樣����,如果文件是逗號分隔的�,則可以不用寫���。
read_table()函數(shù)其他參數(shù)的用法與read_csv()函數(shù)的基本一致。
4�����、導(dǎo)入sql文件
(1)Excel實現(xiàn)
Excel可以直接連接數(shù)據(jù)庫�,通過依次單擊菜單欄中的數(shù)據(jù)>自其他來源導(dǎo)入sql文件。如果你的數(shù)據(jù)庫是SQL Server�����,那么直接選擇來自SQL Server即可�����;如果是MySQL數(shù)據(jù)庫�����,那么你需要選擇來自數(shù)據(jù)連接向?qū)?�,然后通過建立數(shù)據(jù)向?qū)砼cMySQL連接��,如下圖所示:
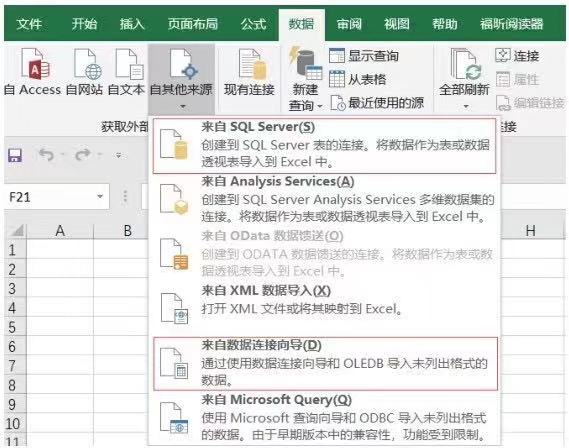
(2)Python實現(xiàn)
Python導(dǎo)入SQL文件主要分為兩步���,第一步將Python與數(shù)據(jù)庫進行連接�����,第二步是利用Python執(zhí)行SQL查詢語句�。
將python與數(shù)據(jù)庫連接時利用的是python模塊��,這個模塊Anaconda沒有��,需要我們手動安裝的�,打開Anaconda Promt,然后輸入pip install pymysql進行安裝即可��,安裝完成以后直接用import導(dǎo)入就可以使用了��,具體連接方法如下:

連接好數(shù)據(jù)庫以后�����,我們就可以執(zhí)行SQL查詢語句了����,利用的是read_sql()方法。


除了sql和con這兩個關(guān)鍵參數(shù)���,read_table()函數(shù)也有用來設(shè)置行索引的參數(shù)index_col�����,設(shè)置列索引的columns���,實例如下:

二��、新建數(shù)據(jù)
這里的新建數(shù)據(jù)主要指新建DataFrame數(shù)據(jù)���,我們在之前談到過,利用pd.Dataframe()方法進行新建�����。
三���、熟悉數(shù)據(jù)
當(dāng)我們有了數(shù)據(jù)源以后��,先別急著分析�,應(yīng)該先熟悉數(shù)據(jù)���,只有對數(shù)據(jù)充分熟悉了�,才能更好的進行分析。
1��、利用head預(yù)覽前幾行
當(dāng)數(shù)據(jù)表中包含數(shù)據(jù)行數(shù)過多時����,而我們又想看一下每一列數(shù)據(jù)都是什么樣的數(shù)據(jù)時,就可以只把數(shù)據(jù)表中前幾行數(shù)據(jù)顯示出來進行查看���。
(1)Excel實現(xiàn)
Excel其實沒有嚴(yán)格意義的顯示前幾行,當(dāng)你打開一個數(shù)據(jù)表時���,所有的數(shù)據(jù)就全部都展示出來了����,如果數(shù)據(jù)的行數(shù)過多��,則可以通過滾動條來控制�。
(2)Python實現(xiàn)
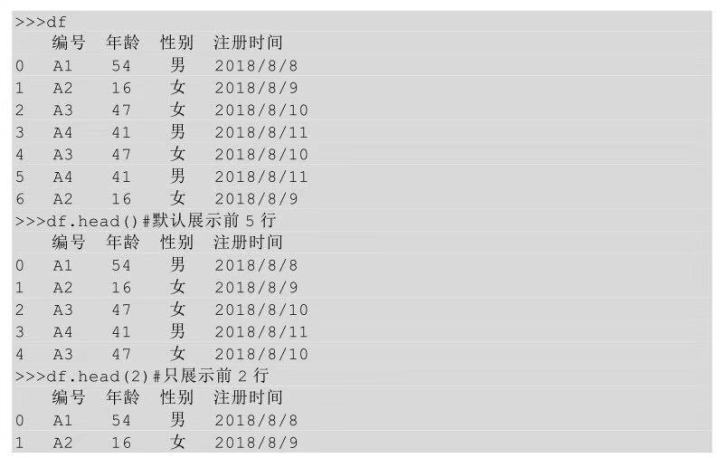
在Python中,當(dāng)一個文件導(dǎo)入后�����,可以用head()方法來控制要顯示哪些行。只需要在head后面的括號中輸入要展示的行數(shù)即可�����,默認(rèn)展示前5行�。
2、利用shape獲取數(shù)據(jù)表的大小
熟悉數(shù)據(jù)的第一點就是先看一下數(shù)據(jù)表的大小�����,即數(shù)據(jù)表有多少行���、多少列��。
(1)Excel實現(xiàn)
在Excel中查看數(shù)據(jù)表有多少行���,一般都是選中某一列,右下角就會出現(xiàn)該表的行數(shù)�����,如下圖所示:

在Excel中選中某一行���,右下角就會出現(xiàn)該表的列數(shù)�����,如下圖所示:

(2)Python實現(xiàn)
在Python中獲取數(shù)據(jù)表的行��、列數(shù)利用的是shape方法�����。

Shape方法會以元組的形式返回行����、列數(shù),上面代碼中的(4,4)表示df表有4行4列數(shù)據(jù)��。這里需要注意的是�����,Python中利用shape方法獲取行數(shù)和列數(shù)時不會把行索引和列索引計算在內(nèi)����,而Excel中是把行索引和列索引計算在內(nèi)的。
3、利用info獲取數(shù)據(jù)類型
熟悉數(shù)據(jù)的第二點就是看一下數(shù)據(jù)類型���,不同的數(shù)據(jù)類型的分析思路是不一樣的��,比如數(shù)值類型的數(shù)據(jù)可以求均值,但是字符串類型的數(shù)據(jù)就沒法求均值了�。
(1)Excel實現(xiàn)
在Excel中若想看某一列數(shù)據(jù)具體是什么類型的,只要把這一列選中�,然后再菜單欄中的數(shù)字那一欄就可以看到這一列的數(shù)據(jù)類型。
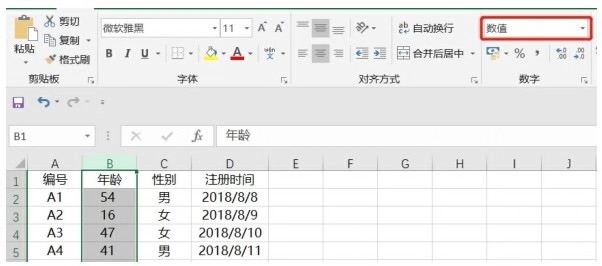
年齡為數(shù)值類型,如下圖所示:
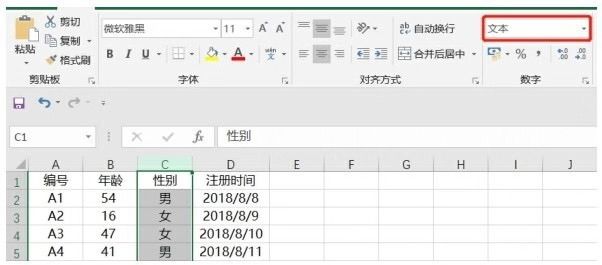
性別為文本類型�,如下圖所示:
(2)Python實現(xiàn)
在Python中我們可以利用info()方法查看數(shù)據(jù)表中的數(shù)據(jù)類型����,而且不需要一列一列查看,在調(diào)用info()方法以后就會輸出整個表中所有列的數(shù)據(jù)類型�����。
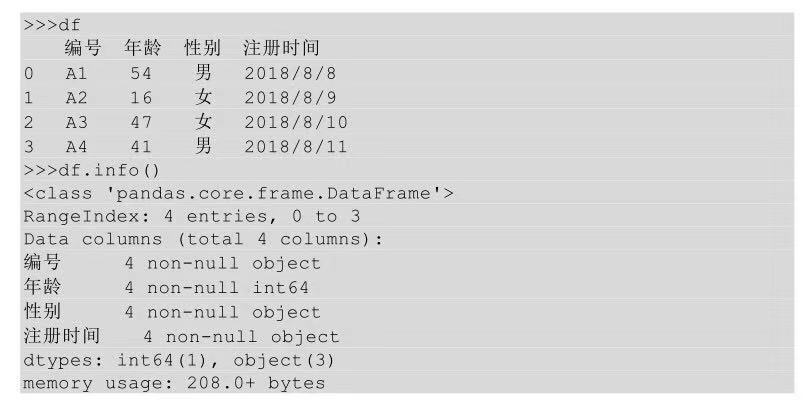
通過info()方法可以看出表df的行索引index是0到3,總共4columns���,分別是編號�、年齡��、性別以及注冊時間�����,且4columns中只有年齡是int類型�,其他columns都是object類型,共占用內(nèi)存208bytes�����。
4、利用describe獲取數(shù)值分布情況
熟悉數(shù)據(jù)的第三點就是掌握數(shù)值的分布情況,即均值是多少���,最值是多少�,方差及分位數(shù)分別又是多少��。
(1)Excel實現(xiàn)
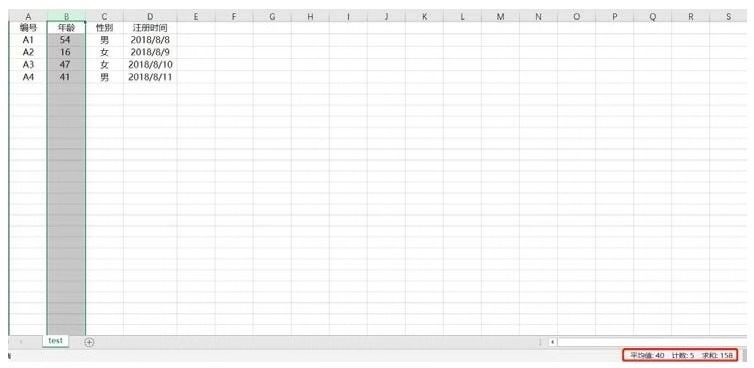
在Excel中如果想看某列的數(shù)值分布情況,那么手動選中這一列,在Excel的右下角就會顯示出這一列的平均值���、計數(shù)及求和��,且只顯示這三個指標(biāo),如下圖所示�。
(2)Python實現(xiàn)
在Python中只需要利用describe()方法就可以獲取所有數(shù)值類型字段的分布值��。


表df中只有年齡這一列是數(shù)值類型�,所以調(diào)用describe()方法時,只計算了年齡這一列的相關(guān)數(shù)值分布情況����。我們可以新建一個含有多列數(shù)值類型字段的DataFrame。

上面的表df中年齡���、收入��、家屬數(shù)都是數(shù)值類型���,所以在調(diào)用describe()方法的時候,會同時計算這三列的數(shù)值分布情況���。
CDA數(shù)據(jù)分析師考試相關(guān)入口一覽(建議收藏):
? 想報名CDA認(rèn)證考試���,點擊>>>
“CDA報名”
了解CDA考試詳情����;
? 想學(xué)習(xí)CDA考試教材��,點擊>>> “CDA教材” 了解CDA考試詳情�����;
? 想加入CDA考試題庫���,點擊>>> “CDA題庫” 了解CDA考試詳情;
? 想了解CDA考試含金量����,點擊>>> “CDA含金量” 了解CDA考試詳情;












 京公網(wǎng)安備 11010802034615號
經(jīng)營許可證編號:京B2-20210330
京公網(wǎng)安備 11010802034615號
經(jīng)營許可證編號:京B2-20210330