作者 | 韋瑋
來(lái)源 | Python愛(ài)好者社區(qū)
本文包含了五個(gè)知識(shí)點(diǎn):
1. 數(shù)據(jù)挖掘與機(jī)器學(xué)習(xí)技術(shù)簡(jiǎn)介
2. Python數(shù)據(jù)預(yù)處理實(shí)戰(zhàn)
3. 常見(jiàn)分類算法介紹
4. 對(duì)鳶尾花進(jìn)行分類案例實(shí)戰(zhàn)
5. 分類算法的選擇思路與技巧
一�、數(shù)據(jù)挖掘與機(jī)器學(xué)習(xí)技術(shù)簡(jiǎn)介
什么是數(shù)據(jù)挖掘���?數(shù)據(jù)挖掘指的是對(duì)現(xiàn)有的一些數(shù)據(jù)進(jìn)行相應(yīng)的處理和分析��,最終得到數(shù)據(jù)與數(shù)據(jù)之間深層次關(guān)系的一種技術(shù)。例如在對(duì)超市貨品進(jìn)行擺放時(shí)��,牛奶到底是和面包擺放在一起銷量更高��,還是和其他商品擺在一起銷量更高�。數(shù)據(jù)挖掘技術(shù)就可以用于解決這類問(wèn)題����。具體來(lái)說(shuō)�����,超市的貨品擺放問(wèn)題可以劃分為關(guān)聯(lián)分析類場(chǎng)景��。
在日常生活中����,數(shù)據(jù)挖掘技術(shù)應(yīng)用的非常廣泛。例如對(duì)于商戶而言�,常常需要對(duì)其客戶的等級(jí)(svip、vip��、普通客戶等)進(jìn)行劃分�,這時(shí)候可以將一部分客戶數(shù)據(jù)作為訓(xùn)練數(shù)據(jù),另一部分客戶數(shù)據(jù)作為測(cè)試數(shù)據(jù)���。然后將訓(xùn)練數(shù)據(jù)輸入到模型中進(jìn)行訓(xùn)練��,在訓(xùn)練完成后�,輸入另一部分?jǐn)?shù)據(jù)進(jìn)行測(cè)試����,最終實(shí)現(xiàn)客戶等級(jí)的自動(dòng)劃分��。其他類似的應(yīng)用例子還有驗(yàn)證碼識(shí)別�����、水果品質(zhì)自動(dòng)篩選等����。
那么機(jī)器學(xué)習(xí)技術(shù)又是什么呢�����?一言以蔽之���,凡是讓機(jī)器通過(guò)我們所建立的模型和算法對(duì)數(shù)據(jù)之間的關(guān)系或者規(guī)則進(jìn)行學(xué)習(xí)���,最后供我們利用的技術(shù)都是機(jī)器學(xué)習(xí)技術(shù)。其實(shí)機(jī)器學(xué)習(xí)技術(shù)是一個(gè)交叉的學(xué)科����,它可以大致分為兩類:傳統(tǒng)的機(jī)器學(xué)習(xí)技術(shù)與深度學(xué)習(xí)技術(shù)�,其中深度學(xué)習(xí)技術(shù)包含了神經(jīng)網(wǎng)絡(luò)相關(guān)技術(shù)��。在本次課程中�����,著重講解的是傳統(tǒng)的機(jī)器學(xué)習(xí)技術(shù)及各種算法����。
由于機(jī)器學(xué)習(xí)技術(shù)和數(shù)據(jù)挖掘技術(shù)都是對(duì)數(shù)據(jù)之間的規(guī)律進(jìn)行探索����,所以人們通常將兩者放在一起提及。而這兩種技術(shù)在現(xiàn)實(shí)生活中也有著非常廣闊的應(yīng)用場(chǎng)景���,其中經(jīng)典的幾類應(yīng)用場(chǎng)景如下圖所示:
1�、分類:對(duì)客戶等級(jí)進(jìn)行劃分���、驗(yàn)證碼識(shí)別����、水果品質(zhì)自動(dòng)篩選等
機(jī)器學(xué)習(xí)和數(shù)據(jù)挖掘技術(shù)可以用于解決分類問(wèn)題��,如對(duì)客戶等級(jí)進(jìn)行劃分、驗(yàn)證碼識(shí)別�����、水果品質(zhì)自動(dòng)篩選等���。
以驗(yàn)證碼識(shí)別為例�,現(xiàn)需要設(shè)計(jì)一種方案����,用以識(shí)別由0到9的手寫體數(shù)字組成的驗(yàn)證碼。有一種解決思路是�,先將一些出現(xiàn)的0到9的手寫體數(shù)字劃分為訓(xùn)練集,然后人工的對(duì)這個(gè)訓(xùn)練集進(jìn)行劃分��,即將各個(gè)手寫體映射到其對(duì)應(yīng)的數(shù)字類別下面���,在建立了這些映射關(guān)系之后�����,就可以通過(guò)分類算法建立相應(yīng)的模型�����。這時(shí)候如果出現(xiàn)了一個(gè)新的數(shù)字手寫體��,該模型可以對(duì)該手寫體代表的數(shù)字進(jìn)行預(yù)測(cè)����,即它到底屬于哪個(gè)數(shù)字類別����。例如該模型預(yù)測(cè)某手寫體屬于數(shù)字1的這個(gè)類別,就可以將該手寫體自動(dòng)識(shí)別為數(shù)字1�����。所以驗(yàn)證碼識(shí)別問(wèn)題實(shí)質(zhì)上就是一個(gè)分類問(wèn)題�。
水果品質(zhì)的自動(dòng)篩選問(wèn)題也是一個(gè)分類問(wèn)題。水果的大小��、顏色等特征也可以映射到對(duì)應(yīng)的甜度類別下面�,例如1這個(gè)類別可以代表甜,0這個(gè)類別代表不甜���。在獲得一些訓(xùn)練集的數(shù)據(jù)之后��,同樣可以通過(guò)分類算法建立模型�����,這時(shí)候如果出現(xiàn)一個(gè)新的水果�����,就可以通過(guò)它的大小����、顏色等特征來(lái)自動(dòng)的判斷它到底是甜的還是不甜的。這樣就實(shí)現(xiàn)了水果品質(zhì)的自動(dòng)篩選��。
2��、回歸:對(duì)連續(xù)型數(shù)據(jù)進(jìn)行預(yù)測(cè)���、趨勢(shì)預(yù)測(cè)等
除了分類之外�����,數(shù)據(jù)挖掘技術(shù)和機(jī)器學(xué)習(xí)技術(shù)還有一個(gè)非常經(jīng)典的場(chǎng)景——回歸��。在前文提到的分類的場(chǎng)景�����,其類別的數(shù)量都有一定的限制����。比如數(shù)字驗(yàn)證碼識(shí)別場(chǎng)景中,包含了0到9的數(shù)字類別�;再比如字母驗(yàn)證碼識(shí)別場(chǎng)景中,包含了a到z的有限的類別�。無(wú)論是數(shù)字類別還是字母類別�,其類別數(shù)量都是有限的。
現(xiàn)在假設(shè)存在一些數(shù)據(jù)�,在對(duì)其進(jìn)行映射后,最好的結(jié)果沒(méi)有落在某個(gè)0�、1或者2的點(diǎn)上,而是連續(xù)的落在1.2�����、1.3��、1.4...上面�����。而分類算法就無(wú)法解決這類問(wèn)題���,這時(shí)候就可以采用回歸分析算法進(jìn)行解決�。在實(shí)際的應(yīng)用中,回歸分析算法可以實(shí)現(xiàn)對(duì)連續(xù)型數(shù)據(jù)進(jìn)行預(yù)測(cè)和趨勢(shì)預(yù)測(cè)等�。
3、聚類:客戶價(jià)值預(yù)測(cè)���、商圈預(yù)測(cè)等
什么是聚類����?在上文中提過(guò)��,要想解決分類問(wèn)題����,必須要有歷史數(shù)據(jù)(即人為建立的正確的訓(xùn)練數(shù)據(jù))。倘若沒(méi)有歷史數(shù)據(jù)��,而需要直接將某對(duì)象的特征劃分到其對(duì)應(yīng)的類別�,分類算法和回歸算法無(wú)法解決這個(gè)問(wèn)題。這種時(shí)候有一種解決辦法——聚類�����,聚類方法直接根據(jù)對(duì)象特征劃分出對(duì)應(yīng)的類別��,它是不需要經(jīng)過(guò)訓(xùn)練的,所以它是一種非監(jiān)督的學(xué)習(xí)方法����。
在什么時(shí)候能用到聚類?假如數(shù)據(jù)庫(kù)中有一群客戶的特征數(shù)據(jù)�,現(xiàn)在需要根據(jù)這些客戶的特征直接劃分出客戶的級(jí)別(如SVIP客戶、VIP客戶)���,這時(shí)候就可以使用聚類的模型去解決�����。另外在預(yù)測(cè)商圈的時(shí)候,也可以使用聚類的算法�。
4、關(guān)聯(lián)分析:超市貨品擺放��、個(gè)性化推薦等
關(guān)聯(lián)分析是指對(duì)物品之間的關(guān)聯(lián)性進(jìn)行分析��。例如�����,某超市內(nèi)存放有大量的貨品�,現(xiàn)在需要分析出這些貨品之間的關(guān)聯(lián)性����,如面包商品與牛奶商品之間的關(guān)聯(lián)性的強(qiáng)弱程度��,這時(shí)候可以采用關(guān)聯(lián)分析算法��,借助于用戶的購(gòu)買記錄等信息�����,直接分析出這些商品之間的關(guān)聯(lián)性��。在了解了這些商品的關(guān)聯(lián)性之后����,就可以將之應(yīng)用于超市的商品擺放,通過(guò)將關(guān)聯(lián)性強(qiáng)的商品放在相近的位置上�,可以有效提升該超市的商品銷量。
此外����,關(guān)聯(lián)分析還可以用于個(gè)性化推薦技術(shù)。比如�,借助于用戶的瀏覽記錄,分析各個(gè)網(wǎng)頁(yè)之間存在的關(guān)聯(lián)性����,在用戶瀏覽網(wǎng)頁(yè)時(shí)�,可以向其推送強(qiáng)關(guān)聯(lián)的網(wǎng)頁(yè)�����。例如�����,在分析了瀏覽記錄數(shù)據(jù)后�,發(fā)現(xiàn)網(wǎng)頁(yè)A與網(wǎng)頁(yè)C之間有很強(qiáng)的關(guān)聯(lián)關(guān)系,那么在某個(gè)用戶瀏覽網(wǎng)頁(yè)A時(shí)��,可以向他推送網(wǎng)頁(yè)C�����,這樣就實(shí)現(xiàn)了個(gè)性化推薦�。
5�����、自然語(yǔ)言處理:文本相似度技術(shù)����、聊天機(jī)器人等
除了上述的應(yīng)用場(chǎng)景之外����,數(shù)據(jù)挖掘和機(jī)器學(xué)習(xí)技術(shù)也可以用于自然語(yǔ)言處理和語(yǔ)音處理等等�����。例如對(duì)文本相似度的計(jì)算和聊天機(jī)器人��。
二���、Python數(shù)據(jù)預(yù)處理實(shí)戰(zhàn)
在進(jìn)行數(shù)據(jù)挖掘與機(jī)器學(xué)習(xí)之前�,首先要做的一步是對(duì)已有數(shù)據(jù)進(jìn)行預(yù)處理��。倘若連初始數(shù)據(jù)都是不正確的����,那么就無(wú)法保證最后的結(jié)果的正確性。只有對(duì)數(shù)據(jù)進(jìn)行預(yù)處理�,保證其準(zhǔn)確性,才能保證最后結(jié)果的正確性��。
數(shù)據(jù)預(yù)處理指的是對(duì)數(shù)據(jù)進(jìn)行初步處理,把臟數(shù)據(jù)(即影響結(jié)果準(zhǔn)確率的數(shù)據(jù))處理掉���,否則很容易影響最終的結(jié)果�。常見(jiàn)的數(shù)據(jù)預(yù)處理方法如下圖所示:
1����、缺失值處理
缺失值是指在一組數(shù)據(jù)中,某行數(shù)據(jù)缺失的某個(gè)特征值���。解決缺失值有兩種方法�,一是將該缺失值所在的這行數(shù)據(jù)刪除掉����,二是將這個(gè)缺失值補(bǔ)充一個(gè)正確的值。
2����、異常值處理
異常值產(chǎn)生的原因往往是數(shù)據(jù)在采集時(shí)發(fā)生了錯(cuò)誤,如在采集數(shù)字68時(shí)發(fā)生了錯(cuò)誤����,誤將其采集成680���。在處理異常值之前���,自然需要先發(fā)現(xiàn)這些異常值數(shù)據(jù)����,往往可以借助畫圖的方法來(lái)發(fā)現(xiàn)這些異常值數(shù)據(jù)����。在對(duì)異常值數(shù)據(jù)處理完成之后,原始數(shù)據(jù)才會(huì)趨于正確��,才能保證最終結(jié)果的準(zhǔn)確性��。
3���、數(shù)據(jù)集成
相較于上文的缺失值處理和異常值處理����,數(shù)據(jù)集成是一種較為簡(jiǎn)單的數(shù)據(jù)預(yù)處理方式���。那么數(shù)據(jù)集成是什么��?假設(shè)存在兩組結(jié)構(gòu)一樣的數(shù)據(jù)A和數(shù)據(jù)B��,且兩組數(shù)據(jù)都已加載進(jìn)入內(nèi)存�,這時(shí)候如果用戶想將這兩組數(shù)據(jù)合并為一組數(shù)據(jù),可以直接使用Pandas對(duì)其進(jìn)行合并���,而這個(gè)合并的過(guò)程實(shí)際上就是數(shù)據(jù)的集成�����。
接下來(lái)以淘寶商品數(shù)據(jù)為例����,介紹一下上文預(yù)處理的實(shí)戰(zhàn)��。
在進(jìn)行數(shù)據(jù)預(yù)處理之前��,首先需要從MySQL數(shù)據(jù)庫(kù)中導(dǎo)入淘寶商品數(shù)據(jù)��。在開啟MySQL數(shù)據(jù)庫(kù)之后�,對(duì)其中的taob表進(jìn)行查詢,得到了如下的輸出:
可以看到����,taob表中有四個(gè)字段。其中title字段用于存儲(chǔ)淘寶商品的名稱����;link字段存儲(chǔ)淘寶商品的鏈接;price存儲(chǔ)淘寶商品的價(jià)格�;comment存儲(chǔ)淘寶商品的評(píng)論數(shù)(一定程度上代表商品的銷量)。
那么接下來(lái)如何將這些數(shù)據(jù)導(dǎo)入進(jìn)來(lái)�����?首先通過(guò)pymysql連接數(shù)據(jù)庫(kù)(如果出現(xiàn)亂碼����,則對(duì)pymysql的源碼進(jìn)行修改),連接成功后��,將taob中的數(shù)據(jù)全部檢索出來(lái)�����,然后借助pandas中的read_sql()方法便可以將數(shù)據(jù)導(dǎo)入到內(nèi)存中�。
read_sql()方法有兩個(gè)參數(shù),第一個(gè)參數(shù)是sql語(yǔ)句�,第二個(gè)參數(shù)是MySQL數(shù)據(jù)庫(kù)的連接信息。具體代碼如下圖:
1����、缺失值處理實(shí)戰(zhàn)
對(duì)缺失值進(jìn)行處理可以采用數(shù)據(jù)清洗的方式�。以上面的淘寶商品數(shù)據(jù)為例�,某件商品的評(píng)論數(shù)可能為0,但是它的價(jià)格卻不可能為0�。然而實(shí)際上在數(shù)據(jù)庫(kù)內(nèi)存在一些price值為0的數(shù)據(jù),之所以會(huì)出現(xiàn)這種情況����,是因?yàn)閷?duì)部分?jǐn)?shù)據(jù)的價(jià)格屬性沒(méi)有爬到。
那么如何才能判斷出這些數(shù)據(jù)出現(xiàn)了缺失值呢�?可以通過(guò)以下的方法來(lái)進(jìn)行判別:
首先對(duì)于之前的taob表調(diào)用data.describe()方法,會(huì)出現(xiàn)如下圖所示的結(jié)果:
如何看懂這個(gè)統(tǒng)計(jì)結(jié)果�����?第一步要注意觀察price和comment字段的count數(shù)據(jù)��,如果兩者不相等��,說(shuō)明一定有信息缺失�;如果兩者相等,則暫時(shí)無(wú)法看出是否有缺失情況�。例如price的count為9616.0000,而comment的count為9615.0000���,說(shuō)明評(píng)論數(shù)據(jù)至少缺失了一條��。
其他各個(gè)字段的含義分別為:mean代表平均數(shù)�����;std代表標(biāo)準(zhǔn)差��;min代表最小值���;max代表最大值。
那么如何對(duì)這些缺失數(shù)據(jù)進(jìn)行處理���?一種方法是刪掉這些數(shù)據(jù)���,還有一種方法是在缺失值處插入一個(gè)新值。第二種方法中的值可以是平均數(shù)或者中位數(shù)�����,而具體使用平均數(shù)還是中位數(shù)需要根據(jù)實(shí)際情況來(lái)決定���。例如年齡這個(gè)數(shù)據(jù)(1到100歲)��,這類平穩(wěn)�����、變化的級(jí)差不大的數(shù)據(jù)��,一般插入平均數(shù)���,而變化的間隔比較大的數(shù)據(jù)����,一般插入中位數(shù)�。
處理價(jià)格的缺失值的具體操作如下:
2、異常值處理實(shí)戰(zhàn)
跟缺失值的處理過(guò)程類似���,想要處理異常值���,首先要發(fā)現(xiàn)異常值。而異常值的發(fā)現(xiàn)往往是通過(guò)畫散點(diǎn)圖的方法��,因?yàn)橄嗨频臄?shù)據(jù)會(huì)在散點(diǎn)圖中集中分布到一塊區(qū)域��,而異常的數(shù)據(jù)會(huì)分布到遠(yuǎn)離這塊區(qū)域的地方���。根據(jù)這個(gè)性質(zhì)����,可以很方便的找到數(shù)據(jù)中的異常值。具體操作如下圖:
首先需要從數(shù)據(jù)中抽出價(jià)格數(shù)據(jù)和評(píng)論數(shù)據(jù)�����。通常的做法可以借助循環(huán)去抽取����,但是這種方法太復(fù)雜�,有一種簡(jiǎn)單的方法是這個(gè)數(shù)據(jù)框進(jìn)行轉(zhuǎn)置,這時(shí)候原先的列數(shù)據(jù)就變成了現(xiàn)在的行數(shù)據(jù)����,可以很方便的獲取價(jià)格數(shù)據(jù)和評(píng)論數(shù)據(jù)。接下來(lái)通過(guò)plot()方法繪制散點(diǎn)圖��,plot()方法第一個(gè)參數(shù)代表橫坐標(biāo)����,第二個(gè)參數(shù)代表縱坐標(biāo),第三個(gè)參數(shù)代表圖的類型��,”o”代表散點(diǎn)圖�。最后通過(guò)show()方法將其展現(xiàn)出來(lái)���,這樣就可以直觀的觀測(cè)到離群點(diǎn)。這些離群點(diǎn)對(duì)數(shù)據(jù)的分析沒(méi)有幫助�����,在實(shí)際操作中往往需要將這些離群點(diǎn)代表的數(shù)據(jù)刪除或者轉(zhuǎn)成正常的值����。下圖是繪制的散點(diǎn)圖:
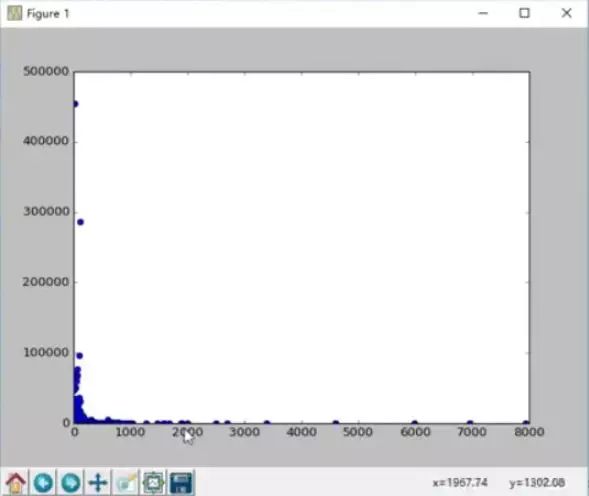
根據(jù)上圖所示,將評(píng)論大于100000�,價(jià)格大于1000的數(shù)據(jù)都處理掉,就可以達(dá)到處理異常值的效果����。而具體的兩種處理方法的實(shí)現(xiàn)過(guò)程如下:
第一種是改值法,將其改為中位數(shù)�、平均數(shù)或者其他的值。具體操作如下圖所示:
第二種是刪除處理法����,即直接刪除這些異常數(shù)據(jù),也是推薦使用的一種方法�。具體操作如下圖所示:
3、分布分析
分布分析是指對(duì)數(shù)據(jù)的分布狀態(tài)進(jìn)行分析,即觀察其是線性分布還是正態(tài)分布�����。一般采用畫直方圖的方式來(lái)進(jìn)行分布分析�����。直方圖的繪制有以下幾個(gè)步驟:計(jì)算極差��、計(jì)算組距和繪制直方圖���。具體的操作如下圖所示:
其中��,借助arrange()方法來(lái)制定樣式,arrange()方法第一個(gè)參數(shù)代表最小值���,第二個(gè)參數(shù)代表最大值���,第三個(gè)參數(shù)代表組距,接下來(lái)使用hist()方法來(lái)繪制直方圖�����。
taob表中的淘寶商品價(jià)格直方圖如下圖所示,大致上符合正態(tài)分布:
taob表中的淘寶商品評(píng)論直方圖如下圖所示��,大致上是遞減的曲線:
4�����、詞云圖的繪制
有的時(shí)候常常需要根據(jù)一段文本信息來(lái)進(jìn)行詞云圖的繪制���,繪制的具體操作如下圖:
實(shí)現(xiàn)的大致流程是:先使用cut()對(duì)文檔進(jìn)行切詞��,在切詞完成之后�����,將這些詞語(yǔ)整理為固定格式����,然后根據(jù)所需的詞云圖的展現(xiàn)形式讀取相應(yīng)的圖片(下圖中的詞云圖是貓的形狀)����,接著使用wc.WordCloud()進(jìn)行詞云圖的轉(zhuǎn)換,最后通過(guò)imshow()展現(xiàn)出相應(yīng)的詞云圖���。例如根據(jù)老九門.txt文檔繪制的詞云圖效果如下圖所示:
三��、常見(jiàn)分類算法介紹
常見(jiàn)的分類算法有很多,如下圖所示:
其中KNN算法和貝葉斯算法都是較為重要的算法,除此之外還有其他的一些算法���,如決策樹算法�、邏輯回歸算法和SVM算法。Adaboost算法主要是用于弱分類算法改造成強(qiáng)分類算法��。
四�、對(duì)鳶尾花進(jìn)行分類案例實(shí)戰(zhàn)
假如現(xiàn)有一些鳶尾花的數(shù)據(jù),這些數(shù)據(jù)包含了鳶尾花的一些特征���,如花瓣長(zhǎng)度����、花瓣寬度�����、花萼長(zhǎng)度和花萼寬度這四個(gè)特征�。有了這些歷史數(shù)據(jù)之后�����,可以利用這些數(shù)據(jù)進(jìn)行分類模型的訓(xùn)練,在模型訓(xùn)練完成后����,當(dāng)新出現(xiàn)一朵不知類型的鳶尾花時(shí),便可以借助已訓(xùn)練的模型判斷出這朵鳶尾花的類型�。這個(gè)案例有著不同的實(shí)現(xiàn)方法,但是借助哪種分類算法進(jìn)行實(shí)現(xiàn)會(huì)更好呢�����?
1����、KNN算法
(1)、KNN算法簡(jiǎn)介
首先考慮這樣一個(gè)問(wèn)題�,在上文的淘寶商品中,有三類商品��,分別是零食�����、名牌包包和電器��,它們都有兩個(gè)特征:price和comment��。按照價(jià)格來(lái)排序,名牌包包最貴��,電器次之�,零食最便宜;按照評(píng)論數(shù)來(lái)排序����,零食評(píng)論數(shù)最多,電器次之����,名牌包包最少。然后以price為x軸����、comment為y軸建立直角坐標(biāo)系,將這三類商品的分布繪制在坐標(biāo)系中�,如下圖所示:
顯然可以發(fā)現(xiàn),這三類商品都集中分布在不同的區(qū)域�����。如果現(xiàn)在出現(xiàn)了一個(gè)已知其特征的新商品��,用��?表示這個(gè)新商品�。根據(jù)其特征,該商品在坐標(biāo)系映射的位置如圖所示�,問(wèn)該商品最有可能是這三類商品中的哪種?
這類問(wèn)題可以采用KNN算法進(jìn)行解決����,該算法的實(shí)現(xiàn)思路是,分別計(jì)算未知商品到其他各個(gè)商品的歐幾里得距離之和�,然后進(jìn)行排序,距離之和越小����,說(shuō)明該未知商品與這類商品越相似。例如在經(jīng)過(guò)計(jì)算之后���,得出該未知商品與電器類的商品的歐幾里得距離之和最小��,那么就可以認(rèn)為該商品屬于電器類商品���。
(2)、實(shí)現(xiàn)方式
上述過(guò)程的具體實(shí)現(xiàn)如下:
當(dāng)然也可以直接調(diào)包����,這樣更加簡(jiǎn)潔和方便�����,缺點(diǎn)在于使用的人無(wú)法理解它的原理:
(3)����、使用KNN算法解決鳶尾花的分類問(wèn)題
首先加載鳶尾花數(shù)據(jù)��。具體有兩種加載方案�����,一種是直接從鳶尾花數(shù)據(jù)集中讀取�����,在設(shè)置好路徑之后��,通過(guò)read_csv()方法進(jìn)行讀取���,分離數(shù)據(jù)集的特征和結(jié)果��,具體操作如下:
還有一種加載方法是借助sklearn來(lái)實(shí)現(xiàn)加載���。sklearn的datasets中自帶有鳶尾花的數(shù)據(jù)集����,通過(guò)使用datasets的load_iris()方法就可以將數(shù)據(jù)加載出來(lái)����,隨后同樣獲取特征和類別���,然后進(jìn)行訓(xùn)練數(shù)據(jù)和測(cè)試數(shù)據(jù)的分離(一般做交叉驗(yàn)證)��,具體是使用train_test_split()方法進(jìn)行分離�����,該方法第三個(gè)參數(shù)代表測(cè)試比例����,第四個(gè)參數(shù)是隨機(jī)種子�,具體操作如下:
在加載完成之后,就可以調(diào)用上文中提到的KNN算法進(jìn)行分類了�����。
2、貝葉斯算法
(1)�����、貝葉斯算法的介紹
首先介紹樸素貝葉斯公式:P(B|A)=P(A|B)P(B)/P(A)�。假如現(xiàn)在有一些課程的數(shù)據(jù),如下表所示���,價(jià)格和課時(shí)數(shù)是課程的特征�����,銷量是課程的結(jié)果�����,若出現(xiàn)了一門新課���,其價(jià)格高且課時(shí)多,根據(jù)已有的數(shù)據(jù)預(yù)測(cè)新課的銷量�����。
顯然這個(gè)問(wèn)題屬于分類問(wèn)題���。先對(duì)表格進(jìn)行處理��,將特征一與特征二轉(zhuǎn)化成數(shù)字�,即0代表低,1代表中��,2代表高�����。在進(jìn)行數(shù)字化之后�,[[t1,t2],[t1,t2],[t1,t2]]------[[0,2],[2,1],[0,0]]���,然后對(duì)這個(gè)二維列表進(jìn)行轉(zhuǎn)置(便于后續(xù)統(tǒng)計(jì))��,得到[[t1,t1,t1],[t2,t2,t2]]-------[[0,2,0],[2,1,0]]��。其中[0,2,0]代表著各個(gè)課程價(jià)格�����,[2,1,0]代表各個(gè)課程的課時(shí)數(shù)�。
而原問(wèn)題可以等價(jià)于求在價(jià)格高����、課時(shí)多的情況下��,新課程銷量分別為高����、中��、低的概率���。即P(C|AB)=P(AB|C)P(C)/P(AB)=P(A|C)P(B|C)P(C)/P(AB)=》P(A|C)P(B|C)P(C)�����,其中C有三種情況:c0=高����,c1=中��,c2=低�。而最終需要比較P(c0|AB)、P(c1|AB)和P(c2|AB)這三者的大小�����,又
P(c0|AB)=P(A|C0)P(B|C0)P(C0)=2/4*2/4*4/7=1/7
P(c1|AB)=P(A|C1)P(B|C1)P(C1)=0=0
P(c2|AB)=P(A|C2)P(B|C2)P(C2)=0=0
顯然P(c0|AB)最大,即可預(yù)測(cè)這門新課的銷量為高��。
(2)��、實(shí)現(xiàn)方式
跟KNN算法一樣�,貝葉斯算法也有兩種實(shí)現(xiàn)方式,一種是詳細(xì)的實(shí)現(xiàn):
另一種是集成的實(shí)現(xiàn)方式:
3�����、決策樹算法
決策樹算法是基于信息熵的理論去實(shí)現(xiàn)的�,該算法的計(jì)算流程分為以下幾個(gè)步驟:
(1)先計(jì)算總信息熵
(2)計(jì)算各個(gè)特征的信息熵
(3)計(jì)算E以及信息增益��,E=總信息熵-信息增益���,信息增益=總信息熵-E
(4)E如果越小���,信息增益越大,不確定因素越小
決策樹是指對(duì)于多特征的數(shù)據(jù)��,對(duì)于第一個(gè)特征���,是否考慮這個(gè)特征(0代表不考慮����,1代表考慮)會(huì)形成一顆二叉樹,然后對(duì)第二個(gè)特征也這么考慮...直到所有特征都考慮完�,最終形成一顆決策樹。如下圖就是一顆決策樹:
決策樹算法實(shí)現(xiàn)過(guò)程為:首先取出數(shù)據(jù)的類別�,然后對(duì)數(shù)據(jù)轉(zhuǎn)化描述的方式(例如將“是”轉(zhuǎn)化成1,“否”轉(zhuǎn)化成0)�,借助于sklearn中的DecisionTreeClassifier建立決策樹,使用fit()方法進(jìn)行數(shù)據(jù)訓(xùn)練�����,訓(xùn)練完成后直接使用predict()即可得到預(yù)測(cè)結(jié)果�,最后使用export_graphviz進(jìn)行決策樹的可視化。具體實(shí)現(xiàn)過(guò)程如下圖所示:
4�、邏輯回歸算法
邏輯回歸算法是借助于線性回歸的原理來(lái)實(shí)現(xiàn)的。假如存在一個(gè)線性回歸函數(shù):y=a1x1+a2x2+a3x3+…+anxn+b���,其中x1到xn代表的是各個(gè)特征����,雖然可以用這條直線去擬合它���,但是由于y范圍太大���,導(dǎo)致其魯棒性太差����。若想實(shí)現(xiàn)分類��,需要縮小y的范圍到一定的空間內(nèi)�,如[0,1]。這時(shí)候通過(guò)換元法可以實(shí)現(xiàn)y范圍的縮?����。?/span>
令y=ln(p/(1-p))
那么:e^y=e^(ln(p/(1-p)))
=> e^y=p/(1-p)
=>e^y*(1-p)=p => e^y-p*e^y=p
=> e^y=p(1+e^y)
=> p=e^y/(1+e^y)
=> p屬于[0,1]
這樣y就降低了范圍�����,從而實(shí)現(xiàn)了精準(zhǔn)分類�,進(jìn)而實(shí)現(xiàn)邏輯回歸����。
邏輯回歸算法對(duì)應(yīng)的實(shí)現(xiàn)過(guò)程如下圖所示:
5、SVM算法
SVM算法是一種精準(zhǔn)分類的算法��,但是其可解釋性并不強(qiáng)��。它可以將低維空間線性不可分的問(wèn)題,變?yōu)楦呶豢臻g上的線性可分���。SVM算法的使用十分簡(jiǎn)單���,直接導(dǎo)入SVC,然后訓(xùn)練模型��,并進(jìn)行預(yù)測(cè)��。具體操作如下:
盡管實(shí)現(xiàn)非常簡(jiǎn)單�����,然而該算法的關(guān)鍵卻在于如何選擇核函數(shù)��。核函數(shù)可分為以下幾類���,各個(gè)核函數(shù)也適用于不同的情況:
(1)��、線性核函數(shù)
(2)��、多項(xiàng)式核函數(shù)
(3)�����、徑向基核函數(shù)
(4)��、Sigmoid核函數(shù)
對(duì)于不是特別復(fù)雜的數(shù)據(jù)�,可以采用線性核函數(shù)或者多項(xiàng)式核函數(shù)。對(duì)于復(fù)雜的數(shù)據(jù)�����,則采用徑向基核函數(shù)����。采用各個(gè)核函數(shù)繪制的圖像如下圖所示:
5、Adaboost算法
假如有一個(gè)單層決策樹的算法�,它是一種弱分類算法(準(zhǔn)確率很低的算法)。如果想對(duì)這個(gè)弱分類器進(jìn)行加強(qiáng)�,可以使用boost的思想去實(shí)現(xiàn),比如使用Adaboost算法��,即進(jìn)行多次的迭代����,每次都賦予不同的權(quán)重��,同時(shí)進(jìn)行錯(cuò)誤率的計(jì)算并調(diào)整權(quán)重�����,最終形成一個(gè)綜合的結(jié)果。
Adaboost算法一般不單獨(dú)使用�����,而是組合使用�����,來(lái)加強(qiáng)那些弱分類的算法���。
五�����、分類算法的選擇思路與技巧
首先看是二分類還是多分類問(wèn)題����,如果是二分類問(wèn)題����,一般這些算法都可以使用;如果是多分類問(wèn)題,則可以使用KNN和貝葉斯算法�����。其次看是否要求高可解釋性�,如果要求高可解釋性,則不能使用SVM算法��。再看訓(xùn)練樣本數(shù)量�、再看訓(xùn)練樣本數(shù)量,如果訓(xùn)練樣本的數(shù)量太大��,則不適合使用KNN算法���。最后看是否需要進(jìn)行弱-強(qiáng)算法改造��,如果需要?jiǎng)t使用Adaboost算法����,否則不使用Adaboost算法�����。如果不確定��,可以選擇部分?jǐn)?shù)據(jù)進(jìn)行驗(yàn)證���,并進(jìn)行模型評(píng)價(jià)(耗時(shí)和準(zhǔn)確率)�。
綜上所述�,可以總結(jié)出各個(gè)分類算法的優(yōu)缺點(diǎn)為:
KNN:多分類,惰性調(diào)用�,不宜訓(xùn)練數(shù)據(jù)過(guò)大
貝葉斯:多分類,計(jì)算量較大�,特征間不能相關(guān)
決策樹算法:二分類,可解釋性非常好
邏輯回歸算法:二分類���,特征之間是否具有關(guān)聯(lián)無(wú)所謂
SVM算法:二分類�����,效果比較不錯(cuò)����,但可解釋性欠缺
Adaboost算法:適用于對(duì)弱分類算法進(jìn)行加強(qiáng)
CDA數(shù)據(jù)分析師考試相關(guān)入口一覽(建議收藏):
? 想報(bào)名CDA認(rèn)證考試����,點(diǎn)擊>>>
“CDA報(bào)名”
了解CDA考試詳情;
? 想學(xué)習(xí)CDA考試教材���,點(diǎn)擊>>> “CDA教材” 了解CDA考試詳情��;
? 想加入CDA考試題庫(kù)���,點(diǎn)擊>>> “CDA題庫(kù)” 了解CDA考試詳情��;
? 想了解CDA考試含金量����,點(diǎn)擊>>> “CDA含金量” 了解CDA考試詳情����;











 京公網(wǎng)安備 11010802034615號(hào)
經(jīng)營(yíng)許可證編號(hào):京B2-20210330
京公網(wǎng)安備 11010802034615號(hào)
經(jīng)營(yíng)許可證編號(hào):京B2-20210330