作者 | 我的智慧生活
來源 | 咪付
在人工智能領(lǐng)域���,機(jī)器學(xué)習(xí)的效果需要用各種指標(biāo)來評價。本文將闡述機(jī)器學(xué)習(xí)中的常用性能評價指標(biāo)����,矢量卷積與神經(jīng)網(wǎng)格的評價指標(biāo)不包括在內(nèi)。
訓(xùn)練與識別
當(dāng)一個機(jī)器學(xué)習(xí)模型建立好了之后��,即模型訓(xùn)練已經(jīng)完成��,我們就可以利用這個模型進(jìn)行分類識別���。
比如�����,給模型輸入一張電動車的照片���,模型能夠識別出這是一輛電動車;輸入一輛摩托車的照片����,模型能夠識別出這是一輛摩托車��。前提是:在模型訓(xùn)練過程中�,進(jìn)行了大量電動車照片�����、摩托車照片的反復(fù)識別訓(xùn)練����。
但即便模型具備了識別電動車、摩托車的能力��,并不代表每次都能百分百正確識別��。當(dāng)然�,我們肯定希望識別正確率越高越好��。識別正確率越高�,代表模型性能越良好。
具體有哪些指標(biāo)可以評價模型性能的優(yōu)良呢��?我們從下面的例子來詳細(xì)了解���。
例如�����,一個測試樣本集S總共有100張照片�,其中,電動車的照片有60張����,摩托車的照片是40張。給模型(二分類模型)輸入這100張照片進(jìn)行分類識別����,我們的目標(biāo)是:要模型找出這100張照片中的所有電動車。這里所說的目標(biāo)即為正例(Positives)����,非目標(biāo)即為負(fù)例(Negatives)。
假設(shè)模型給出的識別結(jié)果如下圖:
從上表結(jié)果可以看出���,在100張照片中�����,模型識別給出了50個電動車目標(biāo)�����,剩下50個則是摩托車�����。這與實際的情況有出入(實際是:電動車60個���,摩托車40個)�,因而有些識別是錯誤的���。正確的識別數(shù)據(jù)體現(xiàn)在TP和TN(T代表True)��,錯誤的識別數(shù)據(jù)則體現(xiàn)在FP和FN(F代表False)���。
在識別給出的50個電動車目標(biāo)中�����,其中只有40個是對的(TP:真的電動車)����,另外10個則識別錯了(FP:假的電動車,實際是摩托車)。
以上四個識別結(jié)果數(shù)值(TP��、FP ���、TN�、FN)就是常用的評估模型性能優(yōu)良的基礎(chǔ)參數(shù)�。在進(jìn)一步詳細(xì)說明TP、FP ����、TN、FN各符號的含義之前����,我們先來了解正例(正樣本)、負(fù)例(負(fù)樣本)的概念����。
正例與負(fù)例
正例(Positives):你所關(guān)注的識別目標(biāo)就是正例。
負(fù)例(Negatives):正例以外的就是負(fù)例�����。
例如����,在上面的例子中���,我們關(guān)注的目標(biāo)是電動車,那么電動車就是正例�����,剩下摩托車則是負(fù)例�。
再如,假設(shè)在一個森林里�����,有羚羊�、馴鹿、考拉三種動物����,我們的目標(biāo)是識別出羚羊,那么羚羊就是正例�����,馴鹿和考拉則是負(fù)例���。
又如��,有一堆數(shù)字卡片��,我們的目標(biāo)是要找出含有數(shù)字8的卡片����,那么含有數(shù)字8的卡片就是正例��,剩于其他的都是負(fù)例�����。
混淆矩陣
了解了正例(Positives)和負(fù)例(Negatives)的概念�,我們就可以很好地理解TP、FN�、TN、FP的各自含義(其中T代表True����,F(xiàn)代表False,P即Positives���,N即Negatives):
在以上四個基礎(chǔ)參數(shù)中�����,真正例與真負(fù)例就是模型給出的正確的識別結(jié)果���,比如電動車識別成電動車(真正例)�����,摩托車識別成摩托車(真負(fù)例)�����;偽正例與偽負(fù)例則是模型給出的錯誤的識別結(jié)果���,比如摩托車識別成電動車(偽正例),電動車識別成摩托車(偽負(fù)例)���。其中�����,真正例(TP)是評價模型性能非常關(guān)鍵的參數(shù)�,因為這是我們所關(guān)注的目標(biāo)的有用結(jié)果,該值越高越好����。
可以看出��,在一個數(shù)據(jù)集里����,模型給出的判斷結(jié)果關(guān)系如下:
接下來,我們就來了解模型性能的各類評價指標(biāo)��。
模型性能指標(biāo)
1 正確率(Accuracy)
正確率(Accuracy):也即準(zhǔn)確率�,識別對了的正例(TP)與負(fù)例(TN)占總識別樣本的比例。
即:
A=(TP+ TN)/S
在上述電動車的例子中��,從上表可知��,TP+ TN =70����,S= 100,則正確率為:
A=70/100=0.7
通常來說��,正確率越高�,模型性能越好。
2 錯誤率(Error-rate)
錯誤率(Error-rate):識別錯了的正例(FP)與負(fù)例(FN)占總識別樣本的比例��。
即:
E=( FP+FN)/S
在上述電動車的例子中,從上表可知�,F(xiàn)P+ FN =30,S= 100�����,則錯誤率為:
E=30/100=0.3
可見����,正確率與錯誤率是分別從正反兩方面進(jìn)行評價的指標(biāo),兩者數(shù)值相加剛好等于1�。正確率高,錯誤率就低����;正確率低,錯誤率就高�����。
3 精度(Precision)
精度(Precision):識別對了的正例(TP)占識別出的正例的比例����。其中,識別出的正例等于識別對了的正例加上識別錯了的正例。
即:
P=TP/(TP+ FP)
在上述電動車的例子中�,TP=40,TP+ FP=50�����。也就是說���,在100張照片識別結(jié)果中,模型總共給出了50個電動車的目標(biāo)���,但這50個目標(biāo)當(dāng)中只有40個是識別正確的���,則精度為:
P=40/50=0.8
因此,精度即為識別目標(biāo)正確的比例�����。精度也即查準(zhǔn)率�,好比電動車的例子來說,模型查出了50個目標(biāo)�����,但這50個目標(biāo)中準(zhǔn)確的比率有多少。
4 召回率(Recall)
召回率(Recall):識別對了的正例(TP)占實際總正例的比例����。其中,實際總正例等于識別對了的正例加上識別錯了的負(fù)例(真正例+偽負(fù)例)���。
即:
R=TP/(TP+ FN)
同樣��,在上述電動車的例子中�����,TP=40��,TP+FN =60��。則召回率為:
R=40/60=0.67
在一定意義上來說���,召回率也可以說是“找回率”,也就是在實際的60個目標(biāo)中�,找回了40個,找回的比例即為:40/60���。同時����,召回率也即查全率,即在實際的60個目標(biāo)中����,有沒有查找完全,查找到的比率是多少�。
從公式可以看出,精度與召回率都與TP值緊密相關(guān)��,TP值越大�����,精度��、召回率就越高�����。理想情況下����,我們希望精度����、召回率越高越好�。但單獨(dú)的高精度或高召回率��,都不足以體現(xiàn)模型的高性能���。
例如下面的例子:
高精度模型
從上表可以看出����,該模型識別結(jié)果給出正例50個�,負(fù)例200個。在識別給出的50個正例當(dāng)中全部都正確(都是真正例���,沒有偽正例)����,因而精度P為100%����,非常高。但是識別給出的200個負(fù)例全部都錯誤(都是偽負(fù)例)����,錯誤率非常高�,這樣的模型性能其實非常低�。
高召回率模型
上表可以看出,該模型識別結(jié)果給出正例110個��,負(fù)例0個���。在110個正例當(dāng)中��,其中10個是真正例(識別正確)�,100個卻是偽正例(識別錯誤)�����。在這個測試數(shù)據(jù)集中��,計算的召回率R為100%���,非常好,也就是說��,在這個數(shù)據(jù)集里總共有10個目標(biāo)���,已全部找到(召回)��。但同時�����,計算得出模型識別結(jié)果的錯誤率E也很高����,高達(dá)91%,所以這個模型性能也很低����,基本不可靠。
5 精度-召回率曲線(PR曲線)
實際中�����,精度與召回率是相互影響的���。通常����,精度高時���,召回率就往往偏低�,而召回率高時,精度則會偏低���。這其實也很好理解�����,前面我們說了���,精度即查準(zhǔn)率,召回率即查全率��,要想查得精準(zhǔn)(一查一個準(zhǔn))��,即模型給出的目標(biāo)都正確����,那就得提高閾值門檻����,閾值一提高,符合要求的目標(biāo)就會減少�,那必然會導(dǎo)致漏網(wǎng)之魚增多,召回率降低�����。
相反,若想召回率高���,沒有漏網(wǎng)之魚(目標(biāo)都找到)���,就要降低閾值門檻,才能把所有目標(biāo)收入囊中����,與此同時會攬入一些偽目標(biāo),從而導(dǎo)致精度降低�����。
例如����,在不同的閾值下(分別為0.6和0.5),模型給出15張圖片的識別結(jié)果如下:
上表中1��、0分別代表正例和負(fù)例�。通過設(shè)定一個閾值(T),當(dāng)置信度分?jǐn)?shù)大于閾值則識別為正例,小于閾值則識別為負(fù)例����。上表識別結(jié)果中當(dāng)閾值T=0.6,模型給出的正例有8個�����,當(dāng)閾值T=0.5�����,模型給出的正例則有10個����。
通過與真實屬性值核對,我們可以得出這兩個閾值下的各個參數(shù)(TP��、FP���、FN)以及計算得出召回率(R)和精度(P)如下:
可以看出����,設(shè)定的閾值不同�,得出的召回率(R)和精度(P)也不相同。因此�,對于每一個閾值可得到對應(yīng)的一組(R,P)��,例如�,上述的兩個閾值可得出兩組(R,P)�,分別為:(0.86,0.75)和(1����,0.7)。如果取多個不同的閾值�,就可以得到多組(R,P)�����。將這些坐標(biāo)點(R��,P)繪制在坐標(biāo)上���,然后將各坐標(biāo)點用曲線連起來����,即可得到PR曲線。
因此�,PR曲線即是以召回率R為橫軸,精度P為縱軸畫出的曲線����,如下圖:
6 AP(Average Precision)值
PR曲線下的面積稱為AP(Average Precision),表示召回率從0-1的平均精度值�。如何計算AP呢?很顯然�����,根據(jù)數(shù)學(xué)知識�,可用積分進(jìn)行計算,公式如下:
顯然�����,這個面積的數(shù)值不會大于1�。PR曲線下的面積越大,模型性能則越好���。性能優(yōu)的模型應(yīng)是在召回率(R)增長的同時保持精度(P)值都在一個較高的水平���,而性能較低的模型往往需要犧牲很多P值才能換來R值的提高�。如下圖所示���,有兩條PR曲線,可以看出���,PR1曲線為性能較優(yōu)的模型表現(xiàn)形式�����,PR1曲線下的面積明顯大于PR2曲線下的面積�����。對于PR1曲線���,隨著R值的增長,P值仍能保持在一個較高的水平�;而對于PR2曲線,隨著R值的增長���,P值則不斷下降���,因此是通過犧牲P值才能換得R值的提高����。
除了使用積分方法計算AP值�,實際應(yīng)用中,還常使用插值方法進(jìn)行計算��。常見的一種插值方法是:選取11個精度點值���,然后計算出這11個點的平均值即為AP值�。
怎樣選取11個精度點值呢��?通常先設(shè)定一組閾值,例如[0,0.1,0.2…,1], 對于R大于每一個閾值(R>0, R>0.1,…, R>1)�,會得到一個對應(yīng)的最大精度值Pmax,這樣就會得到11個最大精度值(Pmax1, Pmax2,…, Pmax11)。
則:
AP=(Pmax1+ Pmax2+…+ Pmax11)/11
7 mAP(Mean Average Precision)值
AP是衡量模型在單個類別上平均精度的好壞���,mAP則是衡量模型在所有類別上平均精度的好壞��,每一個類別對應(yīng)有一個AP���,假設(shè)有n個類別,則有n個AP���,分別為:AP1���,AP2�,…���,APn, mAP就是取所有類別 AP 的平均值,即:
mAP= (AP1+ AP2+…+ APn)/n
8 綜合評價指標(biāo)F-Measure
F-Measure又稱F-Score�����,是召回率R和精度P的加權(quán)調(diào)和平均����,顧名思義即是為了調(diào)和召回率R和精度P之間增減反向的矛盾,該綜合評價指標(biāo)F引入了系數(shù)α對R和P進(jìn)行加權(quán)調(diào)和�����,表達(dá)式如下:
而我們最常用的F1指標(biāo)���,就是上式中系數(shù)α取值為1的情形�,即:
F1=2P.R/(P+R)
F1的最大值為1��,最小值為0��。
9 ROC曲線與AUC
ROC(Receiver Operating Characteristic)曲線與AUC(Area Under the Curver)
ROC曲線,也稱受試者工作特征��。ROC曲線與真正率(TPR�����,True Positive Rate)和假正率(FPR, False Positive Rate)密切相關(guān)��。
真正率(TPR): 識別對了的正例(TP)占實際總正例的比例���,實際計算值跟召回率相同���。即:
TPR =TP/(TP+ FN)
假正率(FPR): 識別錯了的正例(FP)占實際總負(fù)例的比例。也可以說���,誤判的負(fù)例(實際是負(fù)例�����,沒有判對)占實際總負(fù)例的比例��。計算式如下:
FPR =FP/(FP+ TN)
以FPR為橫軸����,TPR為縱軸,繪制得到的曲線就是ROC曲線��,繪制方法與PR曲線類似�。繪制得到的ROC曲線示例如下:
一般來說,ROC曲線越靠近左上方越好��。
ROC曲線下的面積即為AUC�����。面積越大代表模型的分類性能越好�����。如上圖所示�,綠線分類模型AUC=0.83大于紅線分類模型AUC=0.65�����,因此�����,綠線分類模型的分類性能更優(yōu)����。并且�����,綠線較紅線更光滑�����。通常來說���,ROC曲線越光滑,過擬合程度越小���。綠線分類模型的整體性能要優(yōu)于紅線分類模型�。
10 IoU(Intersection-over-Union)指標(biāo)
IoU簡稱交并比�,顧名思義數(shù)學(xué)中交集與并集的比例。假設(shè)有兩個集合A與B, IoU即等于A與B的交集除以A與B的并集�����,表達(dá)式如下:
IoU=A∩B/A∪B
在目標(biāo)檢測中����,IoU為預(yù)測框(Prediction)和真實框(Ground truth)的交并比�����。如下圖所示��,在關(guān)于小貓的目標(biāo)檢測中���,紫線邊框為預(yù)測框(Prediction),紅線邊框為真實框(Ground truth)����。
將預(yù)測框與真實框提取如下圖,兩者的交集區(qū)域為左下圖斜線填充的部分���,兩者的并集區(qū)域為右下圖藍(lán)色填充的區(qū)域。IoU即為:
左邊斜線填充的面積/右邊藍(lán)色填充的總面積�。
在目標(biāo)檢測任務(wù)中,通常取IoU≥0.5��,認(rèn)為召回�����。如果IoU閾值設(shè)置更高,召回率將會降低�,但定位框則更加精確。
理想的情況�����,當(dāng)然是預(yù)測框與真實框重疊越多越好�����,如果兩者完全重疊��,則交集與并集面積相同�����,此時IoU等于1�。
11 Top1與TopK
Top1:對一張圖片,模型給出的識別概率中(即置信度分?jǐn)?shù))���,分?jǐn)?shù)最高的為正確目標(biāo)���,則認(rèn)為正確。這里的目標(biāo)也就是我們說的正例�����。
TopK: 對一張圖片,模型給出的識別概率中(即置信度分?jǐn)?shù))���,分?jǐn)?shù)排名前K位中包含有正確目標(biāo)(正確的正例)�,則認(rèn)為正確�����。
K的取值一般可在100以內(nèi)的量級�����,當(dāng)然越小越實用�。比如較常見的,K取值為5���,則表示為Top5���,代表置信度分?jǐn)?shù)排名前5當(dāng)中有一個是正確目標(biāo)即可���;如果K取值100���,則表示為Top100�����,代表置信度分?jǐn)?shù)排名前100當(dāng)中有一個是正確目標(biāo)(正確的正例)即可��?�?梢?��,隨著K增大,難度下降����。
例如,在一個數(shù)據(jù)集里��,我們對前5名的置信度分?jǐn)?shù)進(jìn)行排序���,結(jié)果如下:
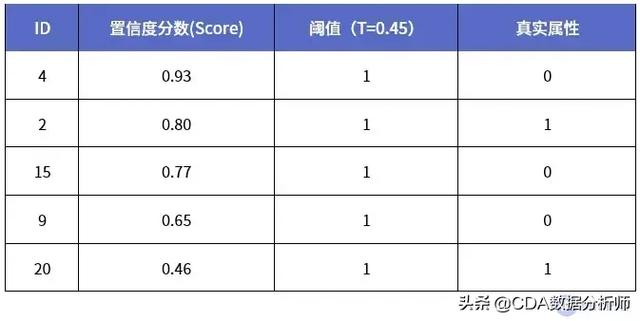
上表中���,取閾值T=0.45,排名前5的置信度分?jǐn)?shù)均大于閾值����,因此都識別為正例�。對于Top1來說���,即ID號為4的圖片��,實際屬性卻是負(fù)例��,因此目標(biāo)識別錯誤��。而對于Top5來說���,排名前5的置信度分?jǐn)?shù)中,有識別正確的目標(biāo)�����,即ID號為2���、20的圖片�,因此認(rèn)為正確��。
在常見的人臉識別算法模型中����,正確率是首當(dāng)其沖的應(yīng)用宣傳指標(biāo)。事實上�,對同一個模型來說,各個性能指標(biāo)也并非一個靜止不變的數(shù)字�����,會隨著應(yīng)用場景��、人臉庫數(shù)量等變化而變化��。因此�,實際應(yīng)用場景下的正確率跟實驗室環(huán)境下所得的正確率一定是存在差距的,某種程度上說�����,實際應(yīng)用場景下的正確率更具有評價意義���。
CDA數(shù)據(jù)分析師考試相關(guān)入口一覽(建議收藏):
? 想報名CDA認(rèn)證考試�����,點擊>>>
“CDA報名”
了解CDA考試詳情�����;
? 想學(xué)習(xí)CDA考試教材�,點擊>>> “CDA教材” 了解CDA考試詳情;
? 想加入CDA考試題庫����,點擊>>> “CDA題庫” 了解CDA考試詳情;
? 想了解CDA考試含金量����,點擊>>> “CDA含金量” 了解CDA考試詳情;











 京公網(wǎng)安備 11010802034615號
經(jīng)營許可證編號:京B2-20210330
京公網(wǎng)安備 11010802034615號
經(jīng)營許可證編號:京B2-20210330