決策樹也可以做特征分析啦
那么這個代碼是用于建模初期�����,你為了大概了解變量的一個基本特征寫的,不是最優(yōu)分組哈,因為這個代碼是將變量最多分為12組,分這么多組的原因也是為了更好的觀察特征而已啦���,你要是覺得太多組,你可以改下樹的深度這些調整一下,這里關于變量特征怎么看���,我就不說了.....
%macro
zhandapao(data,DVAR,id,dir);
proc datasets lib=work nodetails;
delete
varname_total;
run;
/*建立數值型數據集*/
%let lib=%upcase(%scan(&data.,1,'.'));
%letdname=%upcase(%scan(&data.,2,'.'));
%globalvar_list var_num;
proc sql noprint;
select name,count(*) into :var_list separated by' ',:var_num
from sashelp.VCOLUMN
where left(libname)="&lib."and
left(memname)="&dname."and
type="num"and
lowcase(name)^=lowcase("&DVAR.")
and lowcase(name)^="&id.";
quit;
%put
&var_list.;
/*把數值型變量定義為宏變量*/
%doi=1%to&var_num.;
%letnumvar_name_&i.=%scan(&var_list.,&i.);
%put&numvar_name_1.;
proc split data=&data.splitsize=300
maxbranch=2
MAXDEPTH=5nsurrs=5
assess=lift criterion=gini;
input &&numvar_name_&i./level=interval;
target &DVAR./level=binary;
Score data=&data.out=d_&&numvar_name_&i.;
code file="&dir.treecode_tic_&&numvar_name_&i..sas";
describe file="&dir.treerule_tic_&&numvar_name_&i..txt";
run;
data n_D_&&numvar_name_&i.;
set d_&&numvar_name_&i.;
%include"&dir.treecode_tic_&&numvar_name_&i..sas";
rename p_&DVAR.1=p_&&numvar_name_&i.;
run;
proc sql noprint;
select
count(*),max(&&numvar_name_&i.),min(&&numvar_name_&i.)into:total,
:max ,:min from n_D_&&numvar_name_&i.;
quit;
data n_D_&&numvar_name_&i.;
set n_D_&&numvar_name_&i.;
if &min.<=&&numvar_name_&i.<=&max.
then flag="no_null";
else flag="null";
run;
proc sql;
select count(*) into:is_null from
n_D_&&numvar_name_&i.;
quit;
%if&is_null.>0%then%do;
proc sql noprint;
select count(*),max(&&numvar_name_&i.),min(&&numvar_name_&i.)into:total,:max ,:min from n_D_&&numvar_name_&i.;
create table total as
select"&&numvar_name_&i."as
varname,
min(&&numvar_name_&i.) as interval_1,
max(&&numvar_name_&i.) as interval_2,
compress(put(min(round(&&numvar_name_&i.,0.0001)),best32.))||'-'||compress(put(max(round(&&numvar_name_&i.,0.0001)),best32.)) as interval,
sum(&DVAR.) as bad_num,
count(*) as total_num,
count(*)/&total.as num_rate,
sum(&DVAR.)/count(*) as bad_rate
from n_D_&&numvar_name_&i.
group by p_&&numvar_name_&i.
union all
select"&&numvar_name_&i."as varname,
-9999as interval_1,
-9999as interval_2,
'null'as interval,
sum(&DVAR.) as bad_num,
count(*) as total_num,
count(*)/&total.as num_rate,
sum(&DVAR.)/count(*) as bad_rate
from n_D_&&numvar_name_&i.(where=(&&numvar_name_&i.=.))
group by p_&&numvar_name_&i.
order by interval_1;
quit;
%end;
%else%do;
proc sql noprint;
select count(*),max(&&numvar_name_&i.),min(&&numvar_name_&i.)into:total,:max ,:min from n_D_&&numvar_name_&i.;
create table total as
select"&&numvar_name_&i."as varname,
min(&&numvar_name_&i.) asninterval_1,
max(&&numvar_name_&i.) as interval_2,
compress(put(min(round(&&numvar_name_&i.,0.0001)),best32.))||'-'||compress(put(max(round(&&numvar_name_&i.,0.0001)),best32.)) as interval,
sum(&DVAR.) as bad_num,
count(*) as total_num,
count(*)/&total.as num_rate,
sum(&DVAR.)/count(*) as bad_rate
from n_D_&&numvar_name_&i.
group by p_&&numvar_name_&i.
order by interval_1;
quit;
%end;
data &&numvar_name_&i.;
set total;
group=_n_;
run;
proc append base=varname_total
data=&&numvar_name_&i.
force;run;
proc datasets lib=work nodetails;
delete total n_: d_:
&&numvar_name_&i.
_namedat;
quit;
%end;
%mend;
解釋一下這個代碼怎么用�,這個宏已經是封裝好了的,直接填入參數就可以用了:
zhandapao(data,DVAR,id,dir);
data:填入你的數據集
DVAR:填入你的因變量
id:填入你的數據集的主鍵
dir:這個你需要填一個路徑,是用來放決策樹的規(guī)則的文件下���,決策樹的規(guī)則文件你看不懂沒關系�����,你填個類似“F/DD”的路徑就可以了���。
例子:%zhandapao(DD.TEST_DATA,y,CUSTOMER_id,D:test_1);
結果圖就是這樣子:
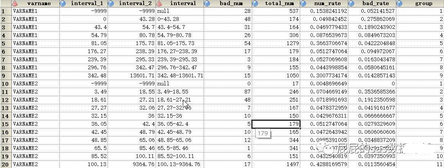
那么今天的更新就到這里啦
CDA數據分析師考試相關入口一覽(建議收藏):
? 想報名CDA認證考試,點擊>>>
“CDA報名”
了解CDA考試詳情�;
? 想學習CDA考試教材���,點擊>>> “CDA教材” 了解CDA考試詳情����;
? 想加入CDA考試題庫�����,點擊>>> “CDA題庫” 了解CDA考試詳情����;
? 想了解CDA考試含金量�����,點擊>>> “CDA含金量” 了解CDA考試詳情���;











 京公網安備 11010802034615號
經營許可證編號:京B2-20210330
京公網安備 11010802034615號
經營許可證編號:京B2-20210330