你知道SAS也可以實現(xiàn)神經(jīng)網(wǎng)絡(luò)嗎
神經(jīng)網(wǎng)絡(luò)的理論太長了�����,我就不寫上來了����,本次的代碼是根據(jù)這本書《數(shù)據(jù)挖掘與應(yīng)用》--張俊妮中神經(jīng)網(wǎng)絡(luò)這一章我做了思路的改動以及在原本代碼的基礎(chǔ)上�����,我把它封裝好變成一個完整的宏���。如果后面你們需要去了解sas神經(jīng)網(wǎng)絡(luò)這個proc
neural過程也可以去購買這本來讀��,這本書沒有配套的代碼���,所以代碼也是我一個一個照著書敲來之后更改的���。
說下這個代碼的思路。
1���、宏的第一步是采用神經(jīng)網(wǎng)絡(luò)建立廣義線性模型�,沒有隱藏層����,對數(shù)據(jù)做第一次的訓(xùn)練����。這里的數(shù)據(jù)宏里面已經(jīng)自動拆分成測試和訓(xùn)練了,你自己不用拆了���。
2����、算出神經(jīng)網(wǎng)絡(luò)建立廣義線性模型的結(jié)果算出原始數(shù)據(jù)(訓(xùn)練集以及測試集)中每一個�,客戶的違約概率�,之后算其ks值�。
3、接下來就是循環(huán)隱藏層���,從1循環(huán)到3���,當(dāng)然你要是覺得3層太少,你可以再設(shè)置�����,使用的是早停止(張俊妮的《數(shù)據(jù)挖掘與應(yīng)用》的114頁種有詳細(xì)解釋這個算法)法建立多層感知模型����,那么這里第一次當(dāng)然循環(huán)就是1層啦,那就是1層感知模型����。
4、在當(dāng)隱藏層為一層的時候���,我們會擬合兩次神經(jīng)網(wǎng)絡(luò)����,第一次不輸出結(jié)果,只是產(chǎn)出在隱藏層為一層的時候��,挑選出最優(yōu)的變量權(quán)重�����,擬合一個使用早停止法擬合出來的一個隱藏層為一層的神經(jīng)網(wǎng)絡(luò)模型�����,利用出來的變量規(guī)則�,算出客戶的概率之后算出模型的ks值。
5����、到這里并不是要循環(huán)隱藏層為兩層,還有呢�,別著急,這時候隱藏層為一層的前提下�����,再使用����,規(guī)則化法建模一層感知器模型,剛才的一層隱藏層使用的早停止法�����,現(xiàn)在使用的是規(guī)則化法�����,這時候規(guī)則化法去的權(quán)衰減常數(shù)的四種取值(規(guī)則化法也可以在書里的115頁看到����。)四種取值是:0.1
、0.01��、0.001��、0.0001然后循環(huán)之后算出����,每個模型的ks記錄。
6�、所以循環(huán)一次隱藏層的層數(shù),是得到4個模型的�����,早停止法一個,規(guī)則化法四個��。
7���、再一次循環(huán)隱藏層的2�、3層�。最終你可以在ks的匯總跑那個表中,選出訓(xùn)練數(shù)據(jù)以及測試數(shù)據(jù)ks都高的模型�����,作為你最終的模型�。
%macromlps(dir,data,list_varname,y_var);
proc datasets lib=work;
delete alltrainfit allvalidfit vaild_ks_total train_ks_total;
run;
data M_CALL_DAY_TOTAL4_t;
set &data.;
indic=_n_;
run;
Proc sort data=M_CALL_DAY_TOTAL4_t; by &y_var.;run;
proc surveyselect data =M_CALL_DAY_TOTAL4_t method = srs rate=0.8
out = traindata;
strata &y_var.;
run;
proc sql;
create table validdata as
select * from
M_CALL_DAY_TOTAL4_t where indic not in (select indic from traindata);
quit;
data traindata;
set traindata;
drop SelectionProb SamplingWeight indic;
run;
data validdata;
set validdata;
drop indic;
run;
proc dmdb data=traindata dmdbcat=dmcdata;
class &y_var.;
var &list_varname.;
run;
proc dmdb data=validdata dmdbcat=dmcdata;
class &y_var.;
var &list_varname.;
run;
data decisionmatrix;
&y_var.=1;
to_1=0;
to_2=1;
output;
&y_var.=0;
to_1=1;
to_2=0;
output;
run;
proc neural data=traindata validdata=validdata dmdbcat=dmcdata ranscale=0.1random=0;
input &list_varname./level=int;
target &y_var./level=nom;
decision decdata=decisionmatrix(type=loss) decvars=TO_1 TO_2;
archi glim;
nloptions maxiter=300;
train ;
code file="&dir.nncode_germancredit_glim.sas";
score data=traindata nodmdb out=traindata_GLIM outfit=trainfit_GLIM role=TRAIN;
score data=validdata nodmdb out=validdata_GLIM outfit=validfit_GLIM role=valid;
run;
data test_train(keep=appl_id &y_var.point);
set traindata;
%include"&dir.nncode_germancredit_glim.sas";
rename P_&y_var.0=point;
run;
proc npar1way data=test_train noprint;
class &y_var.;
var point;
output out=ks_t(keep=_d_ p_ksa rename=(_d_=KS p_ksa=P_value));
run;
data test_train_ks;
set ks_t;
length model$50.;
model="glim";
run;
proc append base=train_ks_total data=test_train_ks force;
run;
data vaild_train(keep=appl_id &y_var.point);
set validdata;
%include"&dir.nncode_germancredit_glim.sas";
rename P_&y_var.0=point;
run;
proc npar1way data=vaild_train noprint;
class &y_var.;
var point;
output out=ks_v(keep=_d_ p_ksa rename=(_d_=KS p_ksa=P_value));
run;
data test_vaild_ks;
set ks_v;
length model$50.;
model="glim";
run;
proc append base=vaild_ks_total data=test_vaild_ks force;
run;
%letnhidden=1;
%do%until(&nhidden.>3);
proc neural data=traindata validdata=validdata dmdbcat=dmcdata graph;
input &list_varname./level=int;
target &y_var./level=nom;
decision decdata=decisionmatrix(type=loss) decvars=TO_1 TO_2;
archi MLP hidden=&nhidden.;
nloptions maxiter=300;
train estiter=1outest=weights_MLP&nhidden._ES outfit=assessment_MLP&&nhidden._ES;
/*code file="&dir.nncode_germancredit_glim.sas";*/
/*score data=traindata nodmdb out=traindata_GLIM outfit=trainfit_GLIM role=TRAIN;*/
/*score data=validdata nodmdb out=validdata_GLIM outfit=validfit_GLIM role=valid;*/
run;
proc sort data=assessment_MLP&&nhidden._ES;
by _VALOSS_;
RUN;
DATA BESTITER;
SET assessment_MLP&&nhidden._ES;
IF _N_=1;
RUN;
proc sql;
select _iter_ into:BESTITER from BESTITER;
quit;
data bestweights;
set weights_MLP&nhidden._ES;
if _type_="PARMS"AND _iter_=&bestiter.;
drop _tech_ _type_ _name_ _decay_ _seed_ _nobj_ _obj_ _objerr_
_averr_ _vnobj_ _vobj_ _vobjerr_ _vaverr_ _p_num_ _iter_;
run;
proc neural data=traindata validdata=validdata dmdbcat=dmcdata graph;
input &list_varname./level=int;
target &y_var./level=nom;
decision decdata=decisionmatrix(type=loss) decvars=TO_1 TO_2;
archi MLP hidden=&nhidden.;
initial inest=bestweights;
train tech=none;
code file="&dir.nncode_germancredit_MLP&nhidden._ES.sas";
score data=traindata nodmdb out=traindata_MLP&Nhidden._ES outfit=trainfit_MLP&Nhidden._ES role=TRAIN;
score data=validdata nodmdb out=validdata_MLP&Nhidden._ES outfit=validfit_MLP&Nhidden._ES role=valid;
run;
data test_train(keep=appl_id &y_var.point);
set traindata;
%include"&dir.nncode_germancredit_MLP&nhidden._ES.sas";
rename P_&y_var.0=point;
run;
proc npar1way data=test_train noprint;
class &y_var.;
var point;
output out=ks_t(keep=_d_ p_ksa rename=(_d_=KS p_ksa=P_value));
run;
data test_train_ks;
set ks_t;
length model$50.;
model="ES";
run;
proc append base=train_ks_total data=test_train_ks force;
run;
data vaild_train(keep=appl_id &y_var.point);
set validdata;
%include"&dir.nncode_germancredit_MLP&nhidden._ES.sas";
rename P_&y_var.0=point;
run;
proc npar1way data=vaild_train noprint;
class &y_var.;
var point;
output out=ks_v(keep=_d_ p_ksa rename=(_d_=KS
p_ksa=P_value));
run;
data test_vaild_ks;
set ks_v;
length model$50.;
model="ES";
run;
proc append base=vaild_ks_total data=test_vaild_ks force;
run;
%letidecay=1;
%do%until(&idecay.>4);
%if&idecay.=1%then%letcedcay=0.1;
%else%if&idecay.=2%then%letcedcay=0.01;
%else%if&idecay.=3%then%letcedcay=0.001;
%else%if&idecay.=4%then%letcedcay=0.0001;
%put&cedcay.;
proc neural data=traindata validdata=validdata dmdbcat=dmcdata graph;
input &list_varname./level=int;
target &y_var./level=nom;
decision decdata=decisionmatrix(type=loss) decvars=TO_1 TO_2;
archi MLP hidden=&nhidden.;
netoptions decay=&cedcay.;
nloptions maxiter=300;
prelim5maxiter=10;
train ;
code file="&dir.nncode_germancredit_MLP&nhidden._WD&idecay..sas";
score
data=traindata nodmdb
out=traindata_MLP&Nhidden._WD&idecay.outfit=trainfit_MLP&Nhidden._WD&idecay.role=TRAIN;
score
data=validdata nodmdb
out=validdata__MLP&Nhidden._WD&idecay.outfit=validfit_MLP&Nhidden._WD&idecay.role=valid;
run;
data test_train(keep=appl_id &y_var.point);
set traindata;
%include"&dir.nncode_germancredit_MLP&nhidden._WD&idecay..sas";
rename P_&y_var.0=point;
run;
proc npar1way data=test_train noprint;
class &y_var.;
var point;
output out=ks_t(keep=_d_ p_ksa rename=(_d_=KS p_ksa=P_value));
run;
data test_train_ks;
set ks_t;
length model$50.;
model="&nhidden._WD&idecay.";
run;
proc append base=train_ks_total data=test_train_ks force;
run;
data vaild_train(keep=appl_id &y_var.point);
set validdata;
%include"&dir.nncode_germancredit_MLP&nhidden._WD&idecay..sas";
rename P_&y_var.0=point;
run;
proc npar1way data=vaild_train noprint;
class &y_var.;
var point;
output out=ks_v(keep=_d_ p_ksa rename=(_d_=KS
p_ksa=P_value));
run;
data test_vaild_ks;
set ks_v;
length model$50.;
model="&nhidden._WD&idecay.";
run;
proc append base=vaild_ks_total data=test_vaild_ks force;
run;
%letidecay=%eval(&idecay.+1);
%end;
%letnhidden=%eval(&nhidden.+1);
%end;
%mend;
/*%mlps();*/
%letlist_varname=%str(N_M5_T09_CONRT N_M6_T09_CINRT N_N5_T82_COC_RC N_M5_T03_CONRT N_M3_T10_CONRC N_M3_T83_COC_RC
N_M3_T09_CINRTN_M6_T83_COT_RC N_M3_T83_CIT_RC N_M2_T10_CONRC N_M5_T03_CINRM N_M5_T10_CONRC N_M4_T02_CONRC N_M1_T08_CONRM
N_M3_T06_CINRM N_M2_T09_CONRT N_M6_T03_CONRT N_M5_T07_CINR );
%mlps(dir=F:data_1,data=raw.CALL_HOUR2_total7_woe,list_varname=&list_varname.,y_var=y);
最終的宏里面的list_vaname就不用填了����,讓他引用上面的宏list_vaname就可以了��,list_vaname填的是你要去建立神經(jīng)網(wǎng)絡(luò)的變量��,這里提醒一句哈��,就是我嘗試了不分組��,分20組����,分10組,分5組的效果���,我建議是將變量分組好之后再丟進(jìn)去比較好��,但是我說不準(zhǔn)到底是幾組好��,畢竟我和你的數(shù)據(jù)不一樣��。
data填的原始數(shù)據(jù)集�����。dir�,填一個路徑�����,這個路徑存放的是最終的模型輸出的規(guī)則���,跟決策樹那個score一個道理的�。y_var填的是你的因變量。
最后看下你們最終要看的結(jié)果圖長什么樣子:
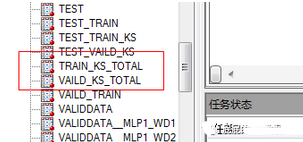
主要是要看這兩個數(shù)據(jù)集的����,這兩個數(shù)據(jù)集長這樣子:
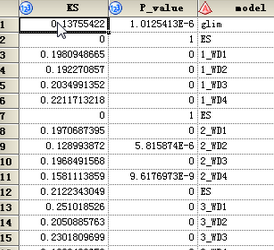
ks值每個模型的ks值,p值是ks的p值����,model對應(yīng)的是哪個模型,GLIM是哪個廣義線性模型�����,1_WD1代表的是隱藏層為1�,權(quán)衰減為0.1對應(yīng)的模型,在1_WD1�,代表的隱藏層為1的時候?qū)?yīng)的早停止發(fā)的模型,在2_WD1�,代表的隱藏層為2的時候?qū)?yīng)的早停止發(fā)的模型,找出你喜歡模型之后����,去路徑下面找規(guī)則代碼就可以了���。如果實在是這個代碼格式跟你的sas不符的�,可以在后臺跟我要下txt的格式的代碼。
CDA數(shù)據(jù)分析師考試相關(guān)入口一覽(建議收藏):
? 想報名CDA認(rèn)證考試�����,點(diǎn)擊>>>
“CDA報名”
了解CDA考試詳情��;
? 想學(xué)習(xí)CDA考試教材�,點(diǎn)擊>>> “CDA教材” 了解CDA考試詳情;
? 想加入CDA考試題庫��,點(diǎn)擊>>> “CDA題庫” 了解CDA考試詳情�����;
? 想了解CDA考試含金量���,點(diǎn)擊>>> “CDA含金量” 了解CDA考試詳情���;











 京公網(wǎng)安備 11010802034615號
經(jīng)營許可證編號:京B2-20210330
京公網(wǎng)安備 11010802034615號
經(jīng)營許可證編號:京B2-20210330