精準(zhǔn)營銷神器之客戶畫像����,你值得擁有
現(xiàn)如今越來越多的用戶偏愛線上交易,越來越少的人會選擇去銀行網(wǎng)點咨詢�����,銀行業(yè)要如何精準(zhǔn)營銷呢���?相比傳統(tǒng)的問卷調(diào)查,大數(shù)據(jù)金融科技可以更好地為銀行賦能��。
為進一步精準(zhǔn)、快速分析用戶行為習(xí)慣�、客戶畫像應(yīng)運而生,本文就為大家闡述客戶畫像是如何生成的�。
客戶信息千千萬,在生成客戶畫像前����,需要了解業(yè)務(wù)方向與重心,例如��,某行想知道零售客戶群的分布情況��,以及客戶標(biāo)簽�����。故本文就以客戶資產(chǎn)����、投資偏好����、風(fēng)險承受能力三方面收集了近千條數(shù)據(jù)。
采用經(jīng)典機器學(xué)習(xí)算法——聚類算法來生成客戶畫像�����,由于聚類算法是無監(jiān)督模型,數(shù)據(jù)質(zhì)量直接決定分群結(jié)果的好壞��,這里收集到的數(shù)據(jù)大部分經(jīng)過處理����。
目標(biāo)
1. 利用聚類算法,得到合理的分群客戶��。
2. 對聚類中心進行解釋���,生成客戶標(biāo)簽���。
3. 闡述測試樣本如何分群。
數(shù)據(jù)源
本文用到的數(shù)據(jù)已經(jīng)同步到kaggle數(shù)據(jù)集中�,并將字段說明與結(jié)果一同上傳了。
https://www.kaggle.com/yuzijuan/customer-clust
開始
環(huán)境與工具
Rstudio���、openxlsx��、fpc����、cluster、Nbclust
調(diào)庫及數(shù)據(jù)清洗
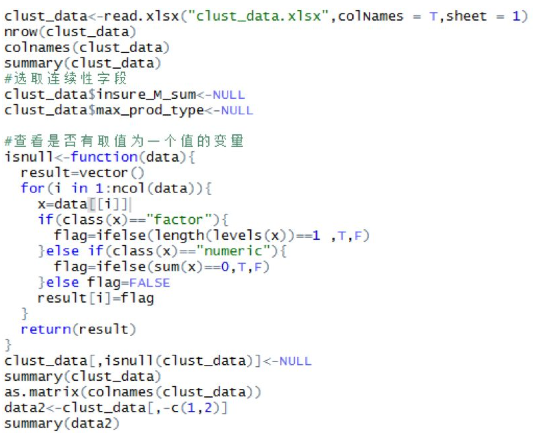
讀取數(shù)據(jù)��,由于數(shù)據(jù)類型大部分是連續(xù)性���,故選擇kmeans聚類算法��,選取連續(xù)性字段�,剔除掉僅有一個值的變量���、剔除掉ID�、年月等信息����,查詢數(shù)據(jù)分布,發(fā)現(xiàn)數(shù)據(jù)質(zhì)量較好��,可以用于建立數(shù)學(xué)模型。
建立聚類模型
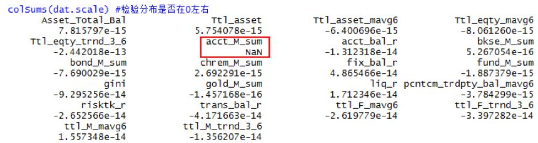
因為kmeans算法是根據(jù)距離求得相似性����,故要消除源數(shù)據(jù)的量綱,這里用scale()將源數(shù)據(jù)進行Z變化���,得到一系列均值為0����,方差為1的正態(tài)分布���。再對每一列數(shù)據(jù)求和�,驗證是否變化完畢�����。如果源數(shù)據(jù)有取值僅為一值或者嚴(yán)重偏態(tài)的數(shù)據(jù)�����,驗證便不會通過。

這種結(jié)果表示驗證通過,列求和的數(shù)據(jù)位于0左右�。如果出現(xiàn)下面的情況,則表明前面數(shù)據(jù)處理有僅有一值的數(shù)據(jù)�,需要處理這樣的數(shù)據(jù)��。
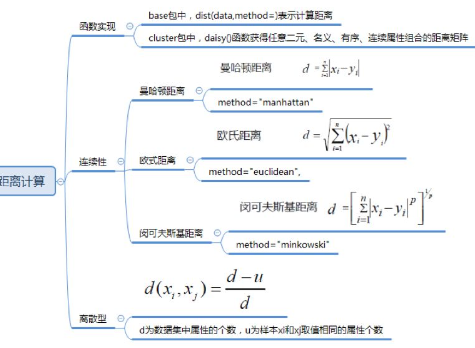
距離的計算公式有很多����,這里給出常見的幾種連續(xù)性和離散型計算方式����。本文全篇的計算方式均為歐式距離�����。
聚類的思想較為簡單����,難點在于要確定初始聚類中心和類別數(shù)。如果想自定義初始聚類中心�,可先通過采樣,用層次法對樣本聚類�,可以預(yù)估k-means的k值和簇中心�����,以這些k值和簇中心��,作為大樣本的初始點�。對于K值的選取�����,R中有一個很棒的包,叫NbClust���,提供了三十種評價評價指標(biāo),用于選擇K值��,包括聚合優(yōu)度�����、輪廓系數(shù)以及CCC檢驗���。執(zhí)行代碼如下�。

通過結(jié)果可以看出,在評價指標(biāo)中有6個選擇分為2類���,有5個選擇分為3類����,有6個選擇分為5類�。由于奧卡姆剃刀原理存在,系統(tǒng)推薦是分為2類�����,而基于業(yè)務(wù)角度思考��,分為5類最為可靠��。故后續(xù)我們將聚類類別分為5類�����。
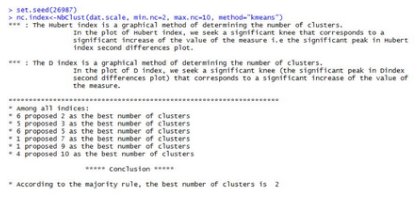
由分類分布可知���,2類和5類是一樣多的票數(shù)����。
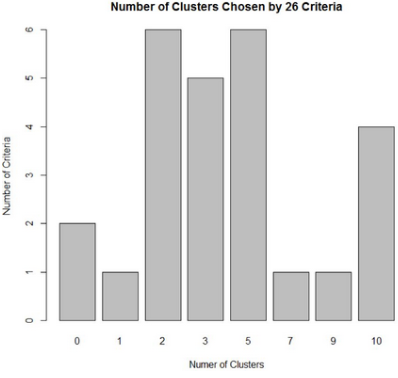
再由kmeans()進行聚類。給定聚類中心為5個����,最大迭代20次。算得聚類優(yōu)度為0.39�,給定聚類中心為2個時算得聚類優(yōu)度為0.13,再次證明選擇5類效果更好����。
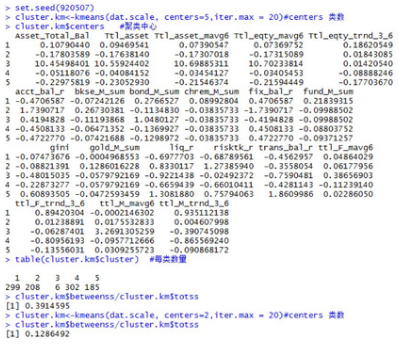
生成聚類結(jié)果
通過cluster.km$cluster可知各個樣本的類別,再求得各個類別的均值��,以及各類均值與總均值之比�����,可以看出各個類別的差異����,以便給客戶打標(biāo)簽�����。代碼如下最后將聚類得分保存為clus_profile2.csv文件中��。

通過clusplot()可以看前兩個成分下的二維聚類效果圖,從圖中可以看出����,聚類結(jié)果較好�。因為較為明顯地將客戶分開����。
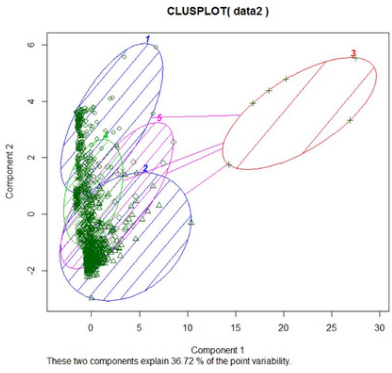
后續(xù)我又用kmedios中心聚類����,又將數(shù)據(jù)聚為5類����,效果不如kmeans,聚類圖如下�����。
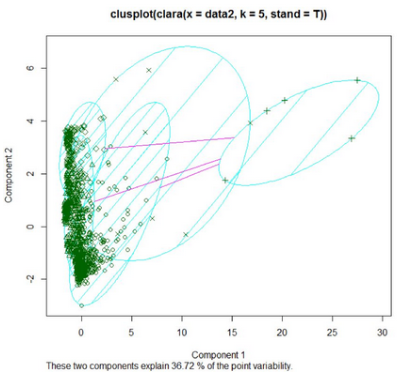
可以看出,中心聚類下�����,數(shù)據(jù)有大量重疊的����,而均值聚類�,較好區(qū)分各個類別�。
解讀聚類結(jié)果
聚類算法相比于其他機器學(xué)習(xí)算法���,其實還是很簡單的�����,而聚類的難點就是需要使結(jié)果具有可解讀性�����,也就是為客戶打標(biāo)簽的過程。本文借助了銀行對個人理財產(chǎn)品的風(fēng)險承受能力評估等級��,從低到高分別:A1(保守型)�、A2(穩(wěn)健型)���、A3(平衡型)、A4(進取型)����、A5(激進型);將得分超過100分(即比總體分布均值大)的標(biāo)為紅色���,將得分低于65(即不達總體分布均值的65%)的標(biāo)為綠色�。可以看出區(qū)分程度較好��。具體解讀結(jié)果如下。
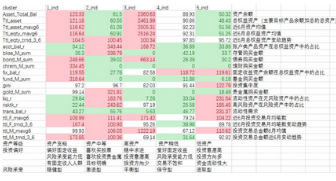
以第三類舉例,可以看出,第三類客戶在資產(chǎn)余額、總權(quán)益余額、近6月資產(chǎn)均值����、近6月總權(quán)益均值的比分上均遠遠大于均值���,并且客戶愛購買債券、沒有投資股票�、基金����、理財���、貴金屬�����、交易較為頻繁且金額較大�,基于這個特點���,我給這類客戶定義為高資產(chǎn)�����、穩(wěn)中求進����、投資意愿高而投資方向上�,很可能屬于年長多金愛存款的類別,風(fēng)險承受為平衡型�����。當(dāng)然���,打標(biāo)簽是一個很好玩的過程�,本文主要給大家介紹如何解讀�����,至于解讀得好不好����,就仁者見仁智者見智�。
測試新樣本
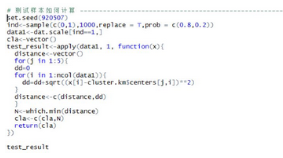
最后����,我簡單計算了一下�����,如果進來新樣本是如何計算類別的���,由于本文僅1000條數(shù)據(jù)��,沒有新樣本�,故我將訓(xùn)練樣本選擇了200條作為新樣本�,納入模型計算距離并得到類別數(shù)。代碼如下�����。
得到的測試結(jié)果展示如下����。

與原來的聚類結(jié)果相比發(fā)現(xiàn)并不是百分百聚類正確。不足5%的會聚類錯誤,在可允許范圍內(nèi)��。
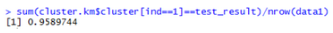
最后如果要給領(lǐng)導(dǎo)看�,那么就要學(xué)會在解讀結(jié)果方面下文章,給領(lǐng)導(dǎo)講講故事���,一個好的客戶畫像不僅需要使結(jié)果具有可解讀性�����,更要能夠清晰展現(xiàn)客戶特點���,以便后續(xù)精準(zhǔn)營銷。

結(jié)語
本案例不足之處在于:
1. 樣本量不算充裕��,可能導(dǎo)致在聚類結(jié)果上有一定的偏差�。
2. 本文未對離散型數(shù)據(jù)如何處理進行闡述。因為本案例中沒有離散型數(shù)據(jù)����。
CDA數(shù)據(jù)分析師考試相關(guān)入口一覽(建議收藏):
? 想報名CDA認(rèn)證考試,點擊>>>
“CDA報名”
了解CDA考試詳情����;
? 想學(xué)習(xí)CDA考試教材�����,點擊>>> “CDA教材” 了解CDA考試詳情�����;
? 想加入CDA考試題庫�����,點擊>>> “CDA題庫” 了解CDA考試詳情;
? 想了解CDA考試含金量���,點擊>>> “CDA含金量” 了解CDA考試詳情�����;











 京公網(wǎng)安備 11010802034615號
經(jīng)營許可證編號:京B2-20210330
京公網(wǎng)安備 11010802034615號
經(jīng)營許可證編號:京B2-20210330