BP神經(jīng)網(wǎng)絡算法與實踐
神經(jīng)網(wǎng)絡曾經(jīng)很火,有過一段低迷期����,現(xiàn)在因為深度學習的原因繼續(xù)火起來了。神經(jīng)網(wǎng)絡有很多種:前向傳輸網(wǎng)絡��、反向傳輸網(wǎng)絡��、遞歸神經(jīng)網(wǎng)絡�、卷積神經(jīng)網(wǎng)絡等。本文介紹基本的反向傳輸神經(jīng)網(wǎng)絡(Backpropagation
簡稱BP)�����,主要講述算法的基本流程和自己在訓練BP神經(jīng)網(wǎng)絡的一些經(jīng)驗����。
BP神經(jīng)網(wǎng)絡的結構
神經(jīng)網(wǎng)絡就是模擬人的大腦的神經(jīng)單元的工作方式����,但進行了很大的簡化���,神經(jīng)網(wǎng)絡由很多神經(jīng)網(wǎng)絡層構成����,而每一層又由許多單元組成��,第一層叫輸入層�,最后一層叫輸出層,中間的各層叫隱藏層�����,在BP神經(jīng)網(wǎng)絡中�,只有相鄰的神經(jīng)層的各個單元之間有聯(lián)系����,除了輸出層外,每一層都有一個偏置結點:
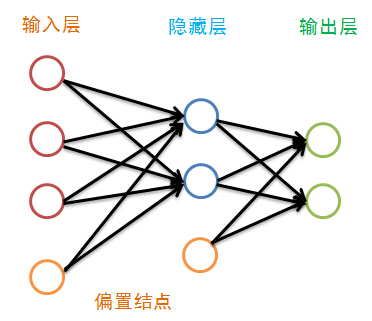
雖然圖中隱藏層只畫了一層�����,但其層數(shù)并沒有限制,傳統(tǒng)的神經(jīng)網(wǎng)絡學習經(jīng)驗認為一層就足夠好����,而最近的深度學習不這么認為。偏置結點是為了描述訓練數(shù)據(jù)中沒有的特征���,偏置結點對于下一層的每一個結點的權重的不同而生產(chǎn)不同的偏置����,于是可以認為偏置是每一個結點(除輸入層外)的屬性�����。我們偏置結點在圖中省略掉:
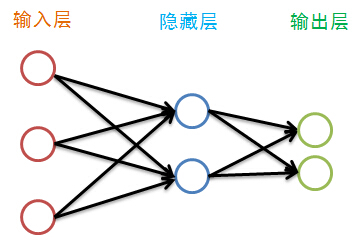
在描述BP神經(jīng)網(wǎng)絡的訓練之前�����,我們先來看看神經(jīng)網(wǎng)絡各層都有哪些屬性:
-
每一個神經(jīng)單元都有一定量的能量�����,我們定義其能量值為該結點j的輸出值Oj����;
-
相鄰層之間結點的連接有一個權重Wij����,其值在[-1,1]之間�;
-
除輸入層外,每一層的各個結點都有一個輸入值��,其值為上一層所有結點按權重傳遞過來的能量之和加上偏置��;
-
除輸入層外�,每一層都有一個偏置值,其值在[0,1]之間��;
-
除輸入層外�,每個結點的輸出值等該結點的輸入值作非線性變換;
-
我們認為輸入層沒有輸入值�����,其輸出值即為訓練數(shù)據(jù)的屬性�,比如一條記錄X=<(1,2,3),類別1>���,那么輸入層的三個結點的輸出值分別為1,2,3. 因此輸入層的結點個數(shù)一般等于訓練數(shù)據(jù)的屬性個數(shù)���。
訓練一個BP神經(jīng)網(wǎng)絡�,實際上就是調(diào)整網(wǎng)絡的權重和偏置這兩個參數(shù)��,BP神經(jīng)網(wǎng)絡的訓練過程分兩部分:
-
前向傳輸�����,逐層波浪式的傳遞輸出值����;
-
逆向反饋,反向逐層調(diào)整權重和偏置�����;
我們先來看前向傳輸����。
前向傳輸(Feed-Forward前向反饋)
在訓練網(wǎng)絡之前,我們需要隨機初始化權重和偏置�����,對每一個權重取[-1,1]的一個隨機實數(shù),每一個偏置取[0,1]的一個隨機實數(shù)����,之后就開始進行前向傳輸。
神經(jīng)網(wǎng)絡的訓練是由多趟迭代完成的����,每一趟迭代都使用訓練集的所有記錄,而每一次訓練網(wǎng)絡只使用一條記錄�����,抽象的描述如下:
首先設置輸入層的輸出值��,假設屬性的個數(shù)為100�����,那我們就設置輸入層的神經(jīng)單元個數(shù)為100�����,輸入層的結點Ni為記錄第i維上的屬性值xi���。對輸入層的操作就這么簡單����,之后的每層就要復雜一些了����,除輸入層外,其他各層的輸入值是上一層輸入值按權重累加的結果值加上偏置�����,每個結點的輸出值等該結點的輸入值作變換
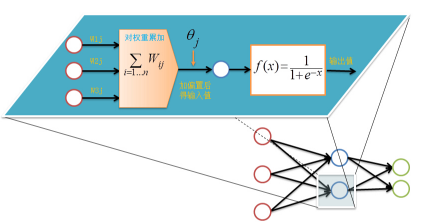
前向傳輸?shù)妮敵鰧拥挠嬎氵^程公式如下:
Ij=∑iWijOi+θj
Oj=11+e?Il
對隱藏層和輸出層的每一個結點都按照如上圖的方式計算輸出值����,就完成前向傳播的過程,緊接著是進行逆向反饋����。
逆向反饋(Backpropagation)
逆向反饋從最后一層即輸出層開始,我們訓練神經(jīng)網(wǎng)絡作分類的目的往往是希望最后一層的輸出能夠描述數(shù)據(jù)記錄的類別���,比如對于一個二分類的問題�����,我們常常用兩個神經(jīng)單元作為輸出層����,如果輸出層的第一個神經(jīng)單元的輸出值比第二個神經(jīng)單元大,我們認為這個數(shù)據(jù)記錄屬于第一類��,否則屬于第二類��。
還記得我們第一次前向反饋時�����,整個網(wǎng)絡的權重和偏置都是我們隨機取�����,因此網(wǎng)絡的輸出肯定還不能描述記錄的類別�,因此需要調(diào)整網(wǎng)絡的參數(shù),即權重值和偏置值��,而調(diào)整的依據(jù)就是網(wǎng)絡的輸出層的輸出值與類別之間的差異���,通過調(diào)整參數(shù)來縮小這個差異����,這就是神經(jīng)網(wǎng)絡的優(yōu)化目標�����。對于輸出層:
Ej=Oj(1?Oj)(Tj?Oj)
其中Ej表示第j個結點的誤差值,Oj表示第j個結點的輸出值����,Tj記錄輸出值�����,比如對于2分類問題����,我們用01表示類標1,10表示類別2,如果一個記錄屬于類別1�����,那么其T1=0�����,T2=1��。
中間的隱藏層并不直接與數(shù)據(jù)記錄的類別打交道���,而是通過下一層的所有結點誤差按權重累加���,計算公式如下:
Ej=Oj(1?Oj)∑kEkWjk
其中Wjk表示當前層的結點j到下一層的結點k的權重值���,Ek下一層的結點k的誤差率。
計算完誤差率后���,就可以利用誤差率對權重和偏置進行更新���,首先看權重的更新:
ΔWij=λEjOi
Wij=Wij+ΔWij
其中λ表示表示學習速率,取值為0到1�,學習速率設置得大,訓練收斂更快�,但容易陷入局部最優(yōu)解,學習速率設置得比較小的話��,收斂速度較慢�����,但能一步步逼近全局最優(yōu)解��。
更新完權重后�����,還有最后一項參數(shù)需要更新,即偏置:
Δθj=λEj
θj=θj+Δθj
至此���,我們完成了一次神經(jīng)網(wǎng)絡的訓練過程�����,通過不斷的使用所有數(shù)據(jù)記錄進行訓練,從而得到一個分類模型����。不斷地迭代,不可能無休止的下去���,總歸有個終止條件
訓練終止條件
每一輪訓練都使用數(shù)據(jù)集的所有記錄�����,但什么時候停止�,停止條件有下面兩種:
-
設置最大迭代次數(shù)��,比如使用數(shù)據(jù)集迭代100次后停止訓練
-
計算訓練集在網(wǎng)絡上的預測準確率����,達到一定門限值后停止訓練
使用BP神經(jīng)網(wǎng)絡分類
我自己寫了一個BP神經(jīng)網(wǎng)絡���,在數(shù)字手寫體識別數(shù)據(jù)集MINIST上測試了一下,MINIST數(shù)據(jù)集中訓練圖片有12000個����,測試圖片20000個,每張圖片是28*28的灰度圖像��,我對圖像進行了二值化處理�,神經(jīng)網(wǎng)絡的參數(shù)設置如下:
-
輸入層設置28*28=784個輸入單元;
-
輸出層設置10個����,對應10個數(shù)字的類別;
-
學習速率設置為0.05�;
訓練經(jīng)過約50次左右迭代,在訓練集上已經(jīng)能達到99%的正確率�,在測試集上的正確率為90.03%,單純的BP神經(jīng)網(wǎng)絡能夠提升的空間不大了�,但kaggle上已經(jīng)有人有卷積神經(jīng)網(wǎng)絡在測試集達到了99.3%的準確率。代碼是去年用C++寫的��,濃濃的JAVA的味道�����,代碼價值不大,但注釋比較詳細��,可以查看這里�,最近寫了一個Java多線程的BP神經(jīng)網(wǎng)絡,但現(xiàn)在還不方便拿出來�����,如果項目黃了���,再放上來吧����。
訓練BP神經(jīng)網(wǎng)絡的一些經(jīng)驗
講一下自己訓練神經(jīng)網(wǎng)絡的一點經(jīng)驗:
-
學習速率不宜設置過大���,一般小于0.1,開始我設置了0.85����,準確率一直提不上去,很明顯是陷入了局部最優(yōu)解����;
-
輸入數(shù)據(jù)應該歸一化���,開始使用0-255的灰度值測試,效果不好��,轉成01二值后�����,效果提升顯著��;
-
盡量是數(shù)據(jù)記錄隨機分布����,不要將數(shù)據(jù)集按記錄排序,假設數(shù)據(jù)集有10個類別���,我們把數(shù)據(jù)集按類別排序���,一條一條記錄地訓練神經(jīng)網(wǎng)絡,訓練到后面���,模型將只記得最近訓練的類別而忘記了之前訓練的類別��;
-
對于多分類問題���,比如漢字識別問題�����,常用漢字就有7000多個�,也就是說有7000個類別����,如果我們將輸出層設置為7000個結點,那計算量將非常大��,并且參數(shù)過多而不容易收斂��,這時候我們應該對類別進行編碼��,7000個漢字只需要13個二進制位即可表示����,因此我們的輸出成只需要設置13個結點即可���。
CDA數(shù)據(jù)分析師考試相關入口一覽(建議收藏):
? 想報名CDA認證考試��,點擊>>>
“CDA報名”
了解CDA考試詳情���;
? 想學習CDA考試教材��,點擊>>> “CDA教材” 了解CDA考試詳情�;
? 想加入CDA考試題庫�����,點擊>>> “CDA題庫” 了解CDA考試詳情���;
? 想了解CDA考試含金量��,點擊>>> “CDA含金量” 了解CDA考試詳情��;











 京公網(wǎng)安備 11010802034615號
經(jīng)營許可證編號:京B2-20210330
京公網(wǎng)安備 11010802034615號
經(jīng)營許可證編號:京B2-20210330