手把手教你用Python分析豆瓣電影——以《我不是藥神》《邪不壓正》為例
《我不是藥神》是由文牧野執(zhí)導(dǎo),寧浩���、徐崢共同監(jiān)制的劇情片��,徐崢、周一圍����、王傳君��、譚卓���、章宇、楊新鳴等主演 �。影片講述了神油店老板程勇從一個(gè)交不起房租的男性保健品商販程勇,一躍成為印度仿制藥“格列寧”獨(dú)家代理商的故事�。
該片于2018年7月5日在中國(guó)上映。上映之后獲得一片好評(píng)���,不少觀眾甚至直呼“中國(guó)電影希望”�,“《熔爐》�����、《辯護(hù)人》之類寫實(shí)影片同水準(zhǔn)”��,誠(chéng)然相較于市面上一眾的摳圖貼臉影視作品����,《藥神》在影片質(zhì)量上確實(shí)好的多,不過我個(gè)人覺得《藥神》的火爆還有以下幾個(gè)原因:
-
影片題材稀少帶來(lái)的新鮮感,像這類”針砭時(shí)弊” 類影視作品���,國(guó)內(nèi)太少�����。
-
順應(yīng)潮流����,目前《手機(jī)》事件及其帶來(lái)的影響和國(guó)家層面文化自信的號(hào)召以及影視作品水平亟待提高的大環(huán)境下�,《藥神》的過審與上映本身也是對(duì)該類題材一定程度的鼓勵(lì)。
-
演員靠譜�、演技扎實(shí),這個(gè)沒的說�,特別是王傳君的表現(xiàn),讓人眼前一亮���。
本文通過爬取《我不是藥神》和《邪不壓正》豆瓣電影評(píng)論���,對(duì)影片進(jìn)行可視化分析。
截止7月13日:《我不是藥神》豆瓣評(píng)分:8.9 分����,貓眼:9.7 分��,時(shí)光網(wǎng):8.8 分 �。
截止7月13日: 《邪不壓正》 豆瓣評(píng)分:7.2 分����,貓眼:7.4 分�����,時(shí)光網(wǎng):7.3 分 ����。
豆瓣的評(píng)分質(zhì)量相對(duì)而言要靠譜點(diǎn),所以本文數(shù)據(jù)來(lái)源也是豆瓣�。
0. 需求分析
1. 前期準(zhǔn)備
1.1 網(wǎng)頁(yè)分析
豆瓣從2017.10月開始全面禁止爬取數(shù)據(jù)�����,僅僅開放500條數(shù)據(jù)����,白天1分鐘最多可以爬取40次,晚上一分鐘可爬取60次數(shù)����,超過此次數(shù)則會(huì)封禁IP地址
tips發(fā)現(xiàn)
實(shí)際操作發(fā)現(xiàn)��,點(diǎn)擊影片評(píng)論頁(yè)面的后頁(yè)時(shí)���,url中的一個(gè)參數(shù)start會(huì)加20,但是如果直接賦予’start’每次增加10�,網(wǎng)頁(yè)也是可以存在的!
1.2 頁(yè)面布局分析
本次使用xpath解析����,因?yàn)橹暗牟┛桶咐眠^正則,也用過beautifulsoup�����,這次嘗試不一樣的方法�。
如下圖所示��,本此數(shù)據(jù)爬取主要獲取的內(nèi)容有:
-
評(píng)論用戶ID
-
評(píng)論內(nèi)容
-
評(píng)分
-
評(píng)論日期
-
用戶所在城市
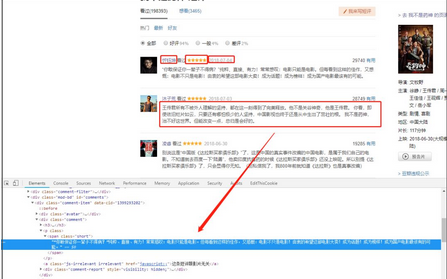
城市信息獲取
評(píng)論頁(yè)面沒有城市信息�,因此需要通過進(jìn)入評(píng)論用戶主頁(yè)去獲取城市信息元素。
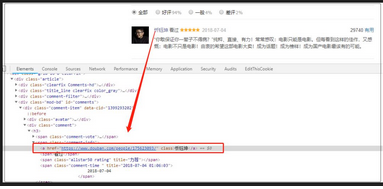
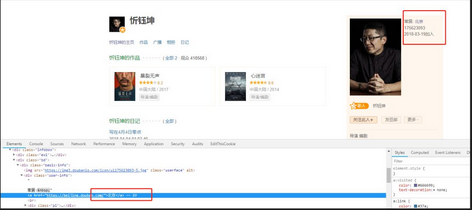
通過分析頁(yè)面發(fā)下�����,用戶ID名稱里隱藏著主頁(yè)鏈接��!所以我的思路就是request該鏈接�����,然后提取城市信息�。
2. 數(shù)據(jù)獲取-爬蟲
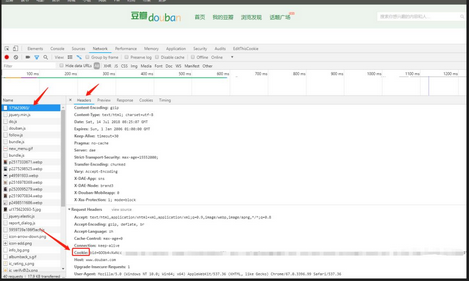
2.1 獲取cookies
因?yàn)槎拱甑呐老x限制,所以需要使用cookies作身份驗(yàn)證�����,通過chrome獲取cooikes位置如下圖:
2.2 加載cookies與headers
下面的cookie被修改了,諸君需要登錄后自己獲取專屬cookieo(∩_∩)o
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/67.0.3396.99 Safari/537.36'}
cookies = {'cookie': 'bid=GOOb4vXwNcc; douban-fav-remind=1; viewed="27611266_26886337"; ps=y; ue="citpys原創(chuàng)分享@163.com"; " \
"push_noty_num=0; push_doumail_num=0; ap=1; loc-last-index-location-id="108288"; ll="108288"; dbcl2="187285881:N/y1wyPpmA8"; ck=4wlL'}
url = "https://movie.douban.com/subject/" + str(id) + "/comments?start=" + str(page * 10) + "&limit=20&sort=new_score&status=P"
res = requests.get(url, headers=headers, cookies=cookies)
res.encoding = "utf-8"
if (res.status_code == 200):
print("\n第{}頁(yè)短評(píng)爬取成功���!".format(page + 1))
print(url)
else:
print("\n第{}頁(yè)爬取失??�!".format(page + 1))
一般刷新頁(yè)面后���,第一個(gè)請(qǐng)求里包含了cookies��。
2.3 延時(shí)反爬蟲
設(shè)置延時(shí)發(fā)出請(qǐng)求�����,并且延時(shí)的值還保留了2位小數(shù)(自我感覺模擬正常訪問請(qǐng)求會(huì)更加逼真…待證實(shí))���。
time.sleep(round(random.uniform(1, 2), 2))
2.4 解析需求數(shù)據(jù)
這里有個(gè)大bug,找了好久�����!
因?yàn)橛械挠脩綦m然給了評(píng)論��,但是沒有給評(píng)分�����,所以score和date這兩個(gè)的xpath位置是會(huì)變動(dòng)的。
所以需要加判斷����,如果發(fā)現(xiàn)score里面解析的是日期,證明該條評(píng)論沒有給出評(píng)分�����。
name = x.xpath('//*[@id="comments"]/div[{}]/div[2]/h3/span[2]/a/text()'.format(i))
# 下面是個(gè)大bug��,如果有的人沒有評(píng)分�,但是評(píng)論了���,那么score解析出來(lái)是日期����,而日期所在位置spen[3]為空
score = x.xpath('//*[@id="comments"]/div[{}]/div[2]/h3/span[2]/span[2]/@title'.format(i))
date = x.xpath('//*[@id="comments"]/div[{}]/div[2]/h3/span[2]/span[3]/@title'.format(i))
m = '\d{4}-\d{2}-\d{2}'
match = re.compile(m).match(score[0])
if match is not None:
date = score
score = ["null"]
else:
pass
content = x.xpath('//*[@id="comments"]/div[{}]/div[2]/p/span/text()'.format(i))
id = x.xpath('//*[@id="comments"]/div[{}]/div[2]/h3/span[2]/a/@href'.format(i))
try:
city = get_city(id[0], i) # 調(diào)用評(píng)論用戶的ID城市信息獲取
except IndexError:
city = " "
name_list.append(str(name[0]))
score_list.append(str(score[0]).strip('[]\'')) # bug 有些人評(píng)論了文字����,但是沒有給出評(píng)分
date_list.append(str(date[0]).strip('[\'').split(' ')[0])
content_list.append(str(content[0]).strip())
city_list.append(city)
2.5 獲取電影名稱
從url上只能獲取電影的subject的8位ID數(shù)值,引起需要自行解析網(wǎng)頁(yè)獲取ID號(hào)對(duì)應(yīng)的電影名稱�,該功能是后期改進(jìn)添加的��,因此為避免現(xiàn)有代碼改動(dòng)多(偷個(gè)懶)��,采用了全局變量賦值給movie_name�,需要注意全局變量調(diào)用時(shí)���,要加global聲明一下��。
pattern = re.compile('<div id="wrapper">.*?<div id="content">.*?<h1>(.*?) 短評(píng)</h1>', re.S)
global movie_name
movie_name = re.findall(pattern, res.text)[0] # list類型
3. 數(shù)據(jù)存儲(chǔ)
因?yàn)閿?shù)據(jù)量不是很大�����,因?yàn)槠胀╟sv存儲(chǔ)足夠�����,把獲取的數(shù)據(jù)轉(zhuǎn)換為pandas的DF格式��,然后存儲(chǔ)到csv文件中�����。
infos = {'name': name_list, 'city': city_list, 'content': content_list, 'score': score_list, 'date': date_list}
data = pd.DataFrame(infos, columns=['name', 'city', 'content', 'score', 'date'])
data.to_csv(str(ID) + "_comments.csv")
因?yàn)榭紤]到代碼的復(fù)用性��,所以main函數(shù)中傳入了兩個(gè)參數(shù)��。
一個(gè)是待分析影片在豆瓣電影中的ID號(hào)(這個(gè)可以在鏈接中獲取到�����,是一個(gè)8位數(shù)�。
一個(gè)是需要爬取的頁(yè)碼數(shù),一般設(shè)置為49�����,因?yàn)榫W(wǎng)站只開放500條評(píng)論�。
另外有些電影評(píng)論有可能不足500條,所以需要調(diào)整��,之前嘗試通過正則匹配分析頁(yè)面結(jié)構(gòu)����。
爬取出來(lái)的結(jié)果如下:

4.1 城市信息清洗
從爬取的結(jié)果分析可以發(fā)現(xiàn)�,城市信息數(shù)據(jù)有以下問題:
有城市空缺
海外城市
亂寫
pyecharts尚不支持的城市,目前支持的城市列表可以看到Github相關(guān)鏈接:
https://github.com/pyecharts/pyecharts/blob/master/pyecharts/datasets/city_coordinates.json
step1: 過濾篩選中文字
通過正則表達(dá)式篩選中文����,通過split函數(shù)提取清理中文,通過sub函數(shù)替換掉各類標(biāo)點(diǎn)符號(hào)����。
line = str.strip()
p2 = re.compile('[^\u4e00-\u9fa5]') # 中文的編碼范圍是:\u4e00到\u9fa5
zh = " ".join(p2.split(line)).strip()
zh = ",".join(zh.split())
str = re.sub("[A-Za-z0-9!�!���,%\[\],���。]", "", zh)
step2: 匹配pyecharts支持的城市列表
一開始我不知道該庫(kù)有城市列表資料(只找了官網(wǎng),沒看github)所以使用的方法如下�,自己上網(wǎng)找中國(guó)城市字典,然后用excel 篩選和列表分割功能快速獲得一個(gè)不包含省份和’市’的城市字典�����,然后匹配��。后來(lái)去github上issue了下����,發(fā)現(xiàn)有現(xiàn)成的字典文件,一個(gè)json文本�,得到的回復(fù)如下(^__^)。
這樣就方便了���,直接和這個(gè)列表匹配就完了�,不在里面的話,直接list.pop就可以了 但是這樣還有個(gè)問題����,就是爬取下來(lái)的城市信息中還包含著省份,而pyecharts中是不能帶省份的�,所以還需要通過分割,來(lái)提取城市���,可能存在的情況有:
· 兩個(gè)字:北京
· 三個(gè)字:攀枝花
· 四個(gè)字:山東煙臺(tái)
· 五個(gè)字:四川攀枝花
· 六個(gè)字:黑龍江哈爾濱
…
因此我做了簡(jiǎn)化處理:
名稱為2~4的��,如果沒匹配到��,則提取后2個(gè)字�,作為城市名���。
名稱為>4的�,如果沒匹配到,則依次嘗試提取后面5����、4、3個(gè)字的。
其余情況���,經(jīng)過觀察原始數(shù)據(jù)發(fā)現(xiàn)數(shù)量極其稀少��,可以忽略不作處理�。
d = pd.read_csv(csv_file, engine='python', encoding='utf-8')
for i in d['city'].dropna(): # 過濾掉空的城市
i = translate(i) # 只保留中文
if len(i)>1 and len(i)<5: # 如果名稱個(gè)數(shù)2~4��,先判斷是否在字典里
if i in fth:
citys.append(i)
else:
i = i[-2:] # 取城市名稱后兩個(gè)���,去掉省份
if i in fth:
citys.append(i)
else:
continue
if len(i) > 4:
if i in fth: # 如果名稱個(gè)數(shù)>2��,先判斷是否在字典里
citys.append(i)
if i[-5:] in fth:
citys.append(i[-5:])
continue
if i[-4:] in fth:
citys.append(i[-4:])
continue
if i[-3:] in fth:
citys.append(i[-3:])
else:
continue
result = {}
while '' in citys:
citys.remove('') # 去掉字符串中的空值
print("城市總數(shù)量為:",len(citys))
for i in set(citys):
result[i] = citys.count(i)
return result
但是這樣可能還有漏洞����,所以為保證程序一定不出錯(cuò),又設(shè)計(jì)了如下校驗(yàn)?zāi)K:
思路就是�,循環(huán)嘗試�����,根據(jù)xx.add()函數(shù)的報(bào)錯(cuò),確定城市名不匹配��,然后從list中把錯(cuò)誤城市pop掉��,另外注意到豆瓣個(gè)人主頁(yè)上的城市信息一般都是是到市���,那么縣一級(jí)的區(qū)域就不考慮了�,這也算是一種簡(jiǎn)化處理�。
while True: # 二次篩選���,和pyecharts支持的城市庫(kù)進(jìn)行匹配����,如果報(bào)錯(cuò)則刪除該城市對(duì)應(yīng)的統(tǒng)計(jì)
try:
attr, val = geo.cast(info)
geo.add("", attr, val, visual_range=[0, 300], visual_text_color="#fff", is_geo_effect_show=False,
is_piecewise=True, visual_split_number=6, symbol_size=15, is_visualmap=True)
except ValueError as e:
e = str(e)
e = e.split("No coordinate is specified for ")[1] # 獲取不支持的城市名稱
info.pop(e)
else:
break
5. 基于snownlp的情感分析
snownlp主要可以進(jìn)行中文分詞(算法是Character-Based Generative Model)��、詞性標(biāo)注(原理是TnT�����、3-gram 隱馬)�、情感分析(官網(wǎng)木有介紹原理,但是指明購(gòu)物類的評(píng)論的準(zhǔn)確率較高�,其實(shí)是因?yàn)樗恼Z(yǔ)料庫(kù)主要是購(gòu)物方面的,可以自己構(gòu)建相關(guān)領(lǐng)域語(yǔ)料庫(kù)�����,替換原來(lái)的�����,準(zhǔn)確率也挺不錯(cuò)的)���、文本分類(原理是樸素貝葉斯)、轉(zhuǎn)換拼音���、繁體轉(zhuǎn)簡(jiǎn)體���、提取文本關(guān)鍵詞(原理是TextRank)、提取摘要(原理是TextRank)��、分割句子�����、文本相似(原理是BM25)��。
官網(wǎng)還有更多關(guān)于該庫(kù)的介紹,在看本節(jié)之前����,建議先看一下官網(wǎng),里面有最基礎(chǔ)的一些命令的介紹�����。
官網(wǎng)鏈接:https://pypi.org/project/snownlp/
由于snownlp全部是unicode編碼�����,所以要注意數(shù)據(jù)是否為unicode編碼�����。因?yàn)槭莡nicode編碼�,所以不需要去除中文文本里面含有的英文,因?yàn)槎紩?huì)被轉(zhuǎn)碼成統(tǒng)一的編碼上面只是調(diào)用snownlp原生語(yǔ)料庫(kù)對(duì)文本進(jìn)行分析�,snownlp重點(diǎn)針對(duì)購(gòu)物評(píng)價(jià)領(lǐng)域,所以為了提高情感分析的準(zhǔn)確度可以采取訓(xùn)練語(yǔ)料庫(kù)的方法����。
attr, val = [], []
info = count_sentiment(csv_file)
info = sorted(info.items(), key=lambda x: x[0], reverse=False) # dict的排序方法
for each in info[:-1]:
attr.append(each[0])
val.append(each[1])
line = Line(csv_file+":影評(píng)情感分析")
line.add("", attr, val, is_smooth=True, is_more_utils=True)
line.render(csv_file+"_情感分析曲線圖.html")
6. 數(shù)據(jù)可視化與解讀
6.0 文本讀取
在后面的commit版本中,我最終只傳入了電影的中文名字作為參數(shù)���,因此相較于之前的版本����,在路徑這一塊兒需要做寫調(diào)整����。由于python不支持相對(duì)路徑下存在中文,因此需要做如下處理:
step1 獲取文件絕對(duì)路徑
step2 轉(zhuǎn)換路徑中的\為\\
step3 如果還報(bào)錯(cuò)�,在read_csv中加參數(shù)read_csv(csv_file, engine='python', encoding='utf-8')
注意: python路徑中,如果最后一個(gè)字符為\會(huì)報(bào)錯(cuò)���,因此可以采取多段拼接的方法解決��。
完整代碼如下:
path = os.path.abspath(os.curdir)
csv_file = path+ "\\" + csv_file +".csv"
csv_file = csv_file.replace('\\', '\\\\')
6.1 評(píng)論來(lái)源城市分析
調(diào)用pyecharts的page函數(shù)�,可以在一個(gè)圖像對(duì)象中創(chuàng)建多個(gè)chart�,只需要對(duì)應(yīng)的add即可。
城市評(píng)論分析的思路如下:
經(jīng)過步驟4的的清洗處理之后���,獲得形如[("青島", 9),("武漢", 12)]結(jié)構(gòu)的數(shù)據(jù)�。
通過循環(huán)試錯(cuò)�,把不符合條件的城市信息pop掉。
except ValueError as e:
e = str(e)
e = e.split("No coordinate is specified for ")[1] # 獲取不支持的城市名稱
info.pop(e)
遍歷dict�����,抽取信息賦值給attr和val為畫圖做準(zhǔn)備。
for key in info:
attr.append(key)
val.append(info[key])
函數(shù)代碼如下:
geo1 = Geo("", "評(píng)論城市分布", title_pos="center", width=1200, height=600,
background_color='#404a59', title_color="#fff")
geo1.add("", attr, val, visual_range=[0, 300], visual_text_color="#fff", is_geo_effect_show=False,
is_piecewise=True, visual_split_number=10, symbol_size=15, is_visualmap=True, is_more_utils=True)
#geo1.render(csv_file + "_城市dotmap.html")
page.add_chart(geo1)
geo2 = Geo("", "評(píng)論來(lái)源熱力圖",title_pos="center", width=1200,height=600, background_color='#404a59', title_color="#fff",)
geo2.add("", attr, val, type="heatmap", is_visualmap=True, visual_range=[0, 50],visual_text_color='#fff', is_more_utils=True)
#geo2.render(csv_file+"_城市heatmap.html") # 取CSV文件名的前8位數(shù)
page.add_chart(geo2)
bar = Bar("", "評(píng)論來(lái)源排行", title_pos="center", width=1200, height=600 )
bar.add("", attr, val, is_visualmap=True, visual_range=[0, 100], visual_text_color='#fff',mark_point=["average"],mark_line=["average"],
is_more_utils=True, is_label_show=True, is_datazoom_show=True, xaxis_rotate=45)
#bar.render(csv_file+"_城市評(píng)論bar.html") # 取CSV文件名的前8位數(shù)
page.add_chart(bar)
pie = Pie("", "評(píng)論來(lái)源餅圖", title_pos="right", width=1200, height=600)
pie.add("", attr, val, radius=[20, 50], label_text_color=None, is_label_show=True, legend_orient='vertical', is_more_utils=True, legend_pos='left')
#pie.render(csv_file + "_城市評(píng)論P(yáng)ie.html") # 取CSV文件名的前8位數(shù)
page.add_chart(pie)
page.render(csv_file + "_城市評(píng)論分析匯總.html")
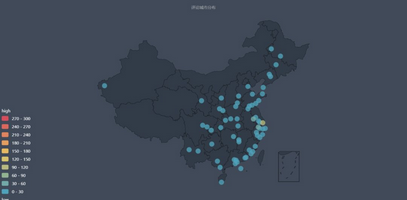
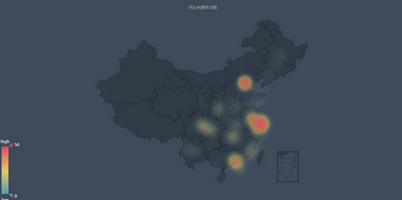
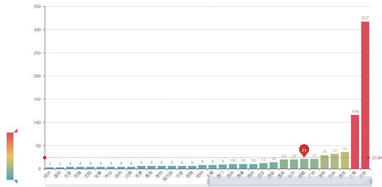
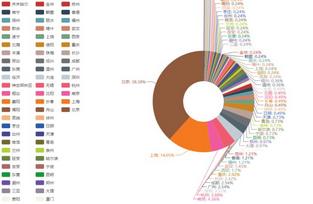
從上圖可以看出�����,《我不是藥神》的觀影人群中��,排名前十的城市依次為 北京、上海、南京���、杭州、深圳、廣州���、成都、長(zhǎng)沙���、重慶�����、西安���。
而相對(duì)的《邪不壓正》觀影人群�,排名前十依次為 北京��、上海��、廣州�����、成都����、杭州�����、南京��、西安�、深圳、長(zhǎng)沙�、哈爾濱。
電影消費(fèi)是城市消費(fèi)的一部分����,某種程度上可以作為觀察一個(gè)城市活力的指標(biāo)��。上述城市大都在近年的GDP排行中居上游�,消費(fèi)力強(qiáng)勁���。
但是我們不能忽略城市人口基數(shù)和熒幕數(shù)量的因素���。一線大城市的熒幕數(shù)量總額是超過其他二三線城市的,大城市人口基數(shù)龐大��,極多的熒幕數(shù)量和座位����、極高密度的排片場(chǎng)次,讓諸多人便捷觀影���,這樣一來(lái)票房自然就比其他城市高出不少���,活躍的觀眾評(píng)論也多。
6.2 評(píng)論情感分析
0.5以下為負(fù)面情緒����,0.5以上為正面情緒��,因?yàn)殡娪昂迷u(píng)太多��,為了圖形的合理性(讓低數(shù)值的統(tǒng)計(jì)量也能在圖中較明顯的展示)�����,把評(píng)論接近1的去掉了���。當(dāng)然按理說情緒正面性到1的應(yīng)該很少,出現(xiàn)這種結(jié)果的原因我覺得是語(yǔ)料庫(kù)的鍋�����。
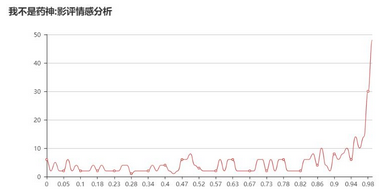
6.3 電影評(píng)分走勢(shì)分析
思路如下:
讀取csv文件����,以dataframe(df)形式保存
遍歷df行�����,保存到list
統(tǒng)計(jì)相同日期相同評(píng)分的個(gè)數(shù)���,例如dict類型 ('很差', '2018-04-28'): 55
轉(zhuǎn)換為df格式�,設(shè)置列名
info_new.columns = ['score', 'date', 'votes']
按日期排序,
info_new.sort_values('date', inplace=True)
遍歷新的df���,每個(gè)日期的評(píng)分分為5種�,因此需要插入補(bǔ)充缺失數(shù)值����。
補(bǔ)充缺失數(shù)值
創(chuàng)建新df,遍歷匹配各種評(píng)分類型��,然后插入行�����。
creat_df = pd.DataFrame(columns = ['score', 'date', 'votes']) # 創(chuàng)建空的dataframe
for i in list(info_new['date']):
location = info_new[(info_new.date==i)&(info_new.score=="力薦")].index.tolist()
if location == []:
creat_df.loc[mark] = ["力薦", i, 0]
mark += 1
location = info_new[(info_new.date==i)&(info_new.score=="推薦")].index.tolist()
if location == []:
creat_df.loc[mark] = ["推薦", i, 0]
mark += 1
location = info_new[(info_new.date==i)&(info_new.score=="還行")].index.tolist()
if location == []:
creat_df.loc[mark] = ["還行", i, 0]
mark += 1
location = info_new[(info_new.date==i)&(info_new.score=="較差")].index.tolist()
if location == []:
creat_df.loc[mark] = ["較差", i, 0]
mark += 1
location = info_new[(info_new.date==i)&(info_new.score=="很差")].index.tolist()
if location == []:
creat_df.loc[mark] = ["很差", i, 0]
mark += 1
info_new = info_new.append(creat_df.drop_duplicates(), ignore_index=True)
細(xì)節(jié)
由于遍歷匹配時(shí)���,抽取的評(píng)分等級(jí)和上文代碼中的“力薦”���、“推薦”、“還行”���、“較差”�����、“很差”次序可能不一致����,因此最后會(huì)有重復(fù)值出現(xiàn),所以在拼接兩個(gè)df時(shí)��,需要duplicates()去重�����。
info_new = info_new.append(creat_df.drop_duplicates(), ignore_index=True)
之后就可以遍歷df取數(shù)畫圖了(第二中遍歷df的方法)����。
for index, row in info_new.iterrows(): # 第二種遍歷df的方法
score_list.append([row['date'], row['votes'], row['score']])
前面還提到了一種遍歷方法。
for indexs in d.index: # 一種遍歷df行的方法
d.loc[indexs].values[:])
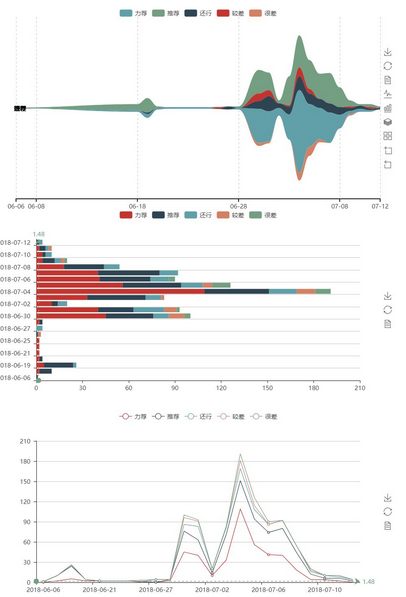
從上述日評(píng)分投票走勢(shì)圖可以發(fā)現(xiàn)�����,在影片上映開始的一周內(nèi)����,為評(píng)論高峰����,尤其是上映3天內(nèi)����,這符合常識(shí)���,但是也可能有偏差�,因?yàn)榕老x獲取的數(shù)據(jù)是經(jīng)過豆瓣電影排序的���,倘若數(shù)據(jù)量足夠大得出的趨勢(shì)可能更接近真實(shí)情況�����。
另外發(fā)現(xiàn)���,影片在上映前也有部分評(píng)論,分析可能是影院公映前的小規(guī)模試映����,且這些提前批的用戶的評(píng)分均值,差不多接近影評(píng)上映后的大規(guī)模評(píng)論的最終評(píng)分 �����,從這些細(xì)節(jié)中����,我們或許可以猜測(cè)�����,這些能提前觀看影片的�,可能是資深影迷或者影視從業(yè)人員�����,他們的評(píng)論有著十分不錯(cuò)的參考價(jià)值��。
那么日后在觀看一部尚未搬上大熒幕的影片前��,我們是否可以通過分析這些提前批用戶的評(píng)價(jià)來(lái)決定是否掏腰包去影院避免邂逅爛片呢��?
6.4 影評(píng)詞云圖
思路如下:
讀取csv文件�����,以dataframe(df)形式保存
去除評(píng)論中非中文文本
選定詞云背景
調(diào)整優(yōu)化停用詞表

《邪不壓正》詞云圖
臺(tái)詞
從詞云圖中可以探究到�,評(píng)論多次提到“臺(tái)詞”�����,《邪不壓正》的臺(tái)詞確實(shí)依舊帶著濃濃的姜文味,例如:
一��、治腳嗎��?不治����。治治吧。不治�。治治?����!缎安粔赫?br />
二�����、怎么相信一個(gè)寫日記的人����。《邪不壓正》
三�、“我就是為了這醋,包了一頓餃子”����?�!缎安粔赫?br />
四���、冰川期就要來(lái)了,海平面降低了��,那幾個(gè)島越來(lái)越大�����,跟澳大利亞連一塊兒了����。《邪不壓正》
五����、你總是給自己設(shè)置障礙,因?yàn)槟悴桓??!缎安粔赫?br />
六、正經(jīng)人誰(shuí)寫日記啊?!缎安粔赫?br />
七�����、都是同一個(gè)師傅教的���,破不了招啊�����?�!缎安粔赫?br />
八�����、你對(duì)我開槍�,不怕殺了我�,不怕。你不愛我����,傻瓜,子彈是假的?��!缎安粔赫?br />
九�、外國(guó)男人只想亂搞����,中國(guó)男人都想成大事?!缎安粔赫?br />
十、老蔣更不可靠���,一個(gè)寫日記的人能可靠嗎�����,正經(jīng)人誰(shuí)寫日記?��。俊缎安粔赫?br />
十一��、你每犯一次錯(cuò)�����,就會(huì)失去一個(gè)爸爸?���!缎安粔赫?br />
十二、誰(shuí)把心里話寫日記里啊��,日記這玩意本來(lái)就不是給外人看���,要是給外人看了,就倆字下賤����!《邪不壓正》
十三 、咳咳…還等什么呢����。——姜文《邪不壓正》
十四���、我當(dāng)時(shí)問你在干嘛����,你拿著肘子和我說:真香�?�!缎安粔赫?br />
十五��、“我要報(bào)仇��!”“那你去呀��!你不敢����?”“我等了十五年了�����,誰(shuí)說我不敢�����?”“那你為什么不去����,你不敢”“對(duì),我不敢”《邪不壓正》
喜歡
雖然這部影片評(píng)分和姜文之前的優(yōu)秀作品相比顯得寒酸��,但是觀眾們依舊對(duì)姜導(dǎo)演抱有期望�,支持和喜愛�����,期待他后續(xù)更多的精彩作品���;程序剛跑完,詞云里突然出現(xiàn)個(gè)爸爸�����,讓我卡頓了(PS:難道程序bug了����?����??)��,接著才想起來(lái)是影片中的姜文飾演的藍(lán)爸爸��,以此稱呼姜導(dǎo)���,可見鐵桿粉絲的滿滿愛意~
一步之遙
同時(shí)可以發(fā)現(xiàn)評(píng)論中����,姜文的另一部作品《一步之遙》也被提及較多。誠(chéng)然����,《邪不壓正》確實(shí)像是《讓子彈飛》和《一步之遙》的糅合,它有著前者的邪性與瀟灑���,又帶有后者的戲謔和浪漫���。因而喜歡《一步之遙》的觀眾會(huì)愛上本片,反之不待見的觀眾也會(huì)給出《一步之遙》的低分��。

高頻重點(diǎn)詞匯有:
-
中國(guó)
-
題材
-
現(xiàn)實(shí)
-
煽情
-
社會(huì)
-
故事
-
好看
-
希望
詞云分析結(jié)果展現(xiàn)出的強(qiáng)烈觀感有一部分原因是《我不是藥神》的意外之喜��,寧浩和徐崢兩個(gè)喜劇界的領(lǐng)軍人物合作�����,很自然的以為會(huì)是喜劇路數(shù)����,誰(shuí)能想到是一部嚴(yán)肅的現(xiàn)實(shí)題材呢?
倘若是尚未觀看本片的讀者�,僅從情感分析的角度看�����,我相信也可以下對(duì)本片下結(jié)論:值得去影院體驗(yàn)的好電影����。正如我在文章開篇所說�,《藥神》的誕生,給中國(guó)當(dāng)前的影片大環(huán)境帶來(lái)了一股清流���,讓人對(duì)國(guó)產(chǎn)電影的未來(lái)多了幾分期許���。
7. 總結(jié)
附錄一下爬取分析的“邪不壓正”的電影數(shù)據(jù)���,因?yàn)閳D形和分析過程相似,所以就不單獨(dú)放圖了����,(ps:姜文這次沒有給人帶來(lái)太大的驚喜==)
視頻:《邪不壓正》——Python數(shù)據(jù)分析
Github完整代碼:
https://github.com/Ctipsy/DA_projects/tree/master/%E6%88%91%E4%B8%8D%E6%98%AF%E8%8D%AF%E7%A5%9E
CDA數(shù)據(jù)分析師考試相關(guān)入口一覽(建議收藏):
? 想報(bào)名CDA認(rèn)證考試,點(diǎn)擊>>>
“CDA報(bào)名”
了解CDA考試詳情�;
? 想學(xué)習(xí)CDA考試教材,點(diǎn)擊>>> “CDA教材” 了解CDA考試詳情���;
? 想加入CDA考試題庫(kù)��,點(diǎn)擊>>> “CDA題庫(kù)” 了解CDA考試詳情��;
? 想了解CDA考試含金量���,點(diǎn)擊>>> “CDA含金量” 了解CDA考試詳情;











 京公網(wǎng)安備 11010802034615號(hào)
經(jīng)營(yíng)許可證編號(hào):京B2-20210330
京公網(wǎng)安備 11010802034615號(hào)
經(jīng)營(yíng)許可證編號(hào):京B2-20210330