python數(shù)據(jù)處理實戰(zhàn)
二�����、需求 對雜亂文本數(shù)據(jù)進行處理
部分?jǐn)?shù)據(jù)截圖如下��,第一個字段是原字段�,后面3個是清洗出的字段�����,從數(shù)據(jù)庫中聚合字段觀察��,乍一看數(shù)據(jù)比較規(guī)律,類似(幣種 金額
萬元)這樣�,我想著用sql寫條件判斷,統(tǒng)一轉(zhuǎn)換為‘萬元人民幣'
單位���,用sql腳本進行字符串截取即可完成�����,但是后面發(fā)現(xiàn)數(shù)據(jù)并不規(guī)則�����,條件判斷太多清洗質(zhì)量也不一定��,有的前面不是左括號��,有的字段里面沒有幣種��,有的數(shù)字并不是整數(shù)�,有的沒有萬字����,這樣如果存儲成數(shù)字和‘萬元人民幣'單位兩個字段寫sql腳本復(fù)雜了,mysql我也沒找到能從文本中提取數(shù)字的函數(shù)���,正則表達式常用于where條件中好像����,如果誰知道mysql有類似從文本中過濾文本提取數(shù)字的函數(shù)����,可以告訴我哈,這樣就不用費這么多功夫����,用kettle一個工具即可,工具活學(xué)活用最好��。
結(jié)合用python的經(jīng)驗��,python對字符串過濾有許多函數(shù)稍后代碼中就是用了這樣的辦法去過濾文本��。
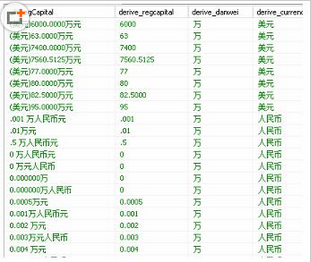
第一次部分清洗數(shù)據(jù)截圖
三���、對數(shù)據(jù)處理的宏觀邏輯思考
拿到數(shù)據(jù)����,先不要著急寫代碼���,先思考清洗的邏輯�����,這點很關(guān)鍵�����,方向?qū)α耸掳牍Ρ?����,剩下的時間就是代碼實現(xiàn)邏輯和調(diào)試代碼的過程��。
3.1思考過程 不寫代碼:
我想實現(xiàn)的最終的數(shù)據(jù)清洗是將資金字段換算成【金額+單位+各幣種】的組合形式或者【金額+單位+統(tǒng)一的人民幣幣種】(幣種進行匯率換算)�,分兩步或者三步都可以
3.1.1拆分出三個字段,數(shù)字����,單位,幣種
(單元分為萬和不含萬�,幣種分為人民幣和具體的外幣)
3.1.2將單位統(tǒng)一換為萬為單位
第一步中單位不是萬的 數(shù)字部分/10000,是萬的數(shù)字部分保持不變
3.1.3將幣種統(tǒng)一為人民幣
幣種是人民幣的前兩個字段都不變�����,不是的數(shù)字部分變?yōu)閿?shù)字*各外幣兌換人民幣的匯率,單位不變依舊是第二步統(tǒng)一的‘萬'
3.2期望各步驟清洗效果 數(shù)據(jù)列舉:
從這個結(jié)果著手我們步步拆解�����,先梳理 清洗邏輯部分
3.2.1第一次清洗期望效果 拆分出三個字段 數(shù)字 單位 幣種:
①字段值=“2000元人民幣”�,第一次清洗
2000 不含萬 人民幣
②字段值=“2000萬元人民幣”�,第一次清洗
2000 萬 人民幣
③字段值=“2000萬元外幣”, 第一次清洗
2000 萬 外幣
3.2.2第二次清洗期望效果 將單位 統(tǒng)一歸為萬:
#二次處理條件
case when 單位=‘萬' then 金額 else 金額/10000 end as 第二次金額
①字段值=“2000元人民幣”
0.2 萬 人民幣
②字段值=“2000萬元人民幣”
2000 萬 人民幣
③字段值=“2000萬元外幣”
2000 萬 外幣
注意:如果上面達到需求 則清洗完畢����,如果想將單位換成人民幣就進行下面三次清洗
3.2.3第三次清洗期望效果:單位 幣種都統(tǒng)一為萬+人民幣
如果最后需求是換算成幣種統(tǒng)一人民幣,那么我們就在二次清洗后的基礎(chǔ)上再寫條件就好����,
#三次處理條件
case when 幣種=‘人民幣' then 金額 else 金額*幣種和人民幣的換算匯率 end as 第三次金額
①字段值=“2000元人民幣”
0.2 萬 人民幣
②字段值=“2000萬元人民幣”
2000 萬 人民幣
③字段值=“2000萬元外幣”
2000*外幣兌換人民幣匯率 萬 人民幣
四、對具體代碼的宏觀邏輯思考
幣種和單位這兩個就2種情況����,很好寫
4.1、幣種部分
這個條件簡單����,如果幣種的值在字符中出現(xiàn)就讓新字段等于這個幣種的值即可。
4.2�、單位(萬為單位)
這個條件也簡單�����,萬字出現(xiàn)在字符中 單位這個變量=‘萬' 沒出現(xiàn)就讓單位變量等于‘不含萬'���,這樣寫是為了方便下一步對數(shù)字進行二次處理的時候?qū)憲l件判斷了。
4.3�����、數(shù)字部分 確保清洗后和原值邏輯上一樣 做些判斷
確保清洗后和原值邏輯上一樣意思是假如有這樣字段300.0100萬清洗后變成300.01 萬 人民幣 也是正確的�����。
filter(str.isdigit,字段的值)這個代碼我首先知道可以將文本中數(shù)字取出��,同過對字段group by
聚合以后知道有小數(shù)點的字段���,取出的值不再帶有小數(shù)點���,如‘20.01萬',filter(str.isdigit,‘20.01萬')取出的數(shù)字就是2001,顯然這個數(shù)字是不正確�,因此就需要考慮有無小數(shù)點的情況,有小數(shù)點的做到和原字段一樣
四��、第一次清洗主要代碼,先不讀取數(shù)據(jù)庫數(shù)據(jù)
從數(shù)據(jù)庫中抽異常值10個左右做測試����,info是regCapital字段的值
#帶小數(shù)點的以小數(shù)點分割 取出小數(shù)點前后部分進行拼接
if '.' in info and int(filter(str.isdigit,info.split('.')[1]))>0:
derive_regcapital=filter(str.isdigit,info.split('.')[0])+'.'+filter(str.isdigit,info.split('.')[1])
elif '.' in info and int(filter(str.isdigit,info.split('.')[1]))==0:
derive_regcapital = filter(str.isdigit, info.split('.')[0])
elif filter(str.isdigit,info)=='':
derive_regcapital='0'
else:
derive_regcapital=filter(str.isdigit,info)
#單位 以萬和不含萬 為統(tǒng)一
if '萬' in info:
derive_danwei='萬'
else:
derive_danwei='不含萬'
#幣種 第一次清洗 外幣保留外幣字段 聚合大量數(shù)據(jù) 發(fā)現(xiàn)數(shù)據(jù)中含有外幣的情況大致有下面這些情況 如果有新外幣出現(xiàn) 進行數(shù)據(jù)的update操作即可
if '美元' in info:
derive_currency='美元'
elif '港幣' in info:
derive_currency = '港幣'
elif '阿富汗尼' in info:
derive_currency = '阿富汗尼'
elif '澳元' in info:
derive_currency = '澳元'
elif '英鎊' in info:
derive_currency = '英鎊'
elif '加拿大元' in info:
derive_currency = '加拿大元'
elif '日元' in info:
derive_currency = '日元'
elif '港幣' in info:
derive_currency = '港幣'
elif '法郎' in info:
derive_currency = '法郎'
elif '歐元' in info:
derive_currency = '歐元'
elif '新加坡' in info:
derive_currency = '新加坡元'
else:
derive_currency = '人民幣'
五、全部代碼:讀取數(shù)據(jù)庫數(shù)據(jù) 進行全量清洗
第四步我是將部分?jǐn)?shù)據(jù)做了測試�,驗證代碼無誤,此時邏輯上應(yīng)再從宏觀上再拓展�,將info變量動態(tài)變?yōu)閿?shù)據(jù)庫中所有的值��,進行全量清洗
#coding:utf-8
from class_mysql import Mysql
project=Mysql('s_58infor_data',[],0,conn_type='local')
p2=Mysql('etl1_58infor_data',[],24,conn_type='local')
field_list=p2.select_fields(db='local_db',table='etl1_58infor_data')
print field_list
project2=Mysql('etl1_58infor_data',field_list=field_list,field_num=26,conn_type='local')
#以上部分 看不懂沒關(guān)系 由于我有兩套數(shù)據(jù)庫環(huán)境����,測試和生產(chǎn)
#不同的數(shù)據(jù)庫連接和網(wǎng)段,因此要傳遞不同的參數(shù)進行切換數(shù)據(jù)庫和數(shù)據(jù)連接 如果一套環(huán)境 連接一次數(shù)據(jù)庫即可 數(shù)據(jù)處理需要經(jīng)常做測試 方便自己調(diào)用
data_tuple=project.select(db='local_db',id=0)
#data_tuple 是我實例化自己寫的操作數(shù)據(jù)庫的類對數(shù)據(jù)庫數(shù)據(jù)進行全字段進行讀取����,返回值是一個不可變的對象元組tuple,清洗需要保留舊表全部字段,同時增加3個清洗后的數(shù)據(jù)字段
data_tuple=project.select(db='local_db',id=0)
#遍歷元組 用字典去存儲每個字段的值 插入到增加3個清洗字段的表 etl1_58infor_data
for data in data_tuple:
item={}
#old_data不取最后一個字段 是因為那個字段我想用當(dāng)前處理的時間
#這樣可以計算數(shù)據(jù)總量運行的時間 來調(diào)整二次清洗的時間去和和kettle定時任務(wù)對接
#元組轉(zhuǎn)換為列表 轉(zhuǎn)換的原因是因為元組為不可變類型 如果有數(shù)據(jù)中有null值 遍歷轉(zhuǎn)換為字符串會報錯
old_data=list(data[:-1])
if data[-2]:
if len(data[-2]) >0 :
info=data[-2].encode('utf-8')
else:
info=''
if '.' in info and int(filter(str.isdigit,info.split('.')[1]))>0:
derive_regcapital=filter(str.isdigit,info.split('.')[0])+'.'+filter(str.isdigit,info.split('.')[1])
elif '.' in info and int(filter(str.isdigit,info.split('.')[1]))==0:
derive_regcapital = filter(str.isdigit, info.split('.')[0])
elif filter(str.isdigit,info)=='':
derive_regcapital='0'
else:
derive_regcapital=filter(str.isdigit,info)
if '萬' in info:
derive_danwei='萬'
else:
derive_danwei='不含萬'
if '美元' in info:
derive_currency='美元'
elif '港幣' in info:
derive_currency = '港幣'
elif '阿富汗尼' in info:
derive_currency = '阿富汗尼'
elif '澳元' in info:
derive_currency = '澳元'
elif '英鎊' in info:
derive_currency = '英鎊'
elif '加拿大元' in info:
derive_currency = '加拿大元'
elif '日元' in info:
derive_currency = '日元'
elif '港幣' in info:
derive_currency = '港幣'
elif '法郎' in info:
derive_currency = '法郎'
elif '歐元' in info:
derive_currency = '歐元'
elif '新加坡' in info:
derive_currency = '新加坡元'
else:
derive_currency = '人民幣'
time_58infor_data = p2.create_time()
old_data.append(time_58infor_data)
old_data.append(derive_regcapital)
old_data.append(derive_danwei)
old_data.append(derive_currency)
#print len(old_data)
for i in range(len(old_data)):
if not old_data[i] :
old_data[i]=''
else:
pass
data2=old_data[i].replace('"','')
item[i+1]=data2
print item[1]
#插入測試環(huán)境 的表
project2.insert(item=item,db='local_db')
六��、代碼運行情況
6.1讀取數(shù)據(jù)庫原表數(shù)據(jù)和新表創(chuàng)建的字段

讀取數(shù)據(jù)庫原表數(shù)據(jù)和新表創(chuàng)建的字段
6.2 插入新表 并進行第一次數(shù)據(jù)清洗
紅框部分為清洗部分�,其他數(shù)據(jù)做了脫敏處理
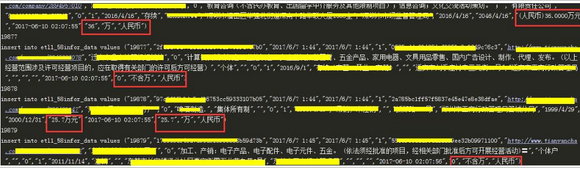
插入新表 并進行第一次數(shù)據(jù)清洗
6.3 數(shù)據(jù)表數(shù)據(jù)清洗結(jié)果
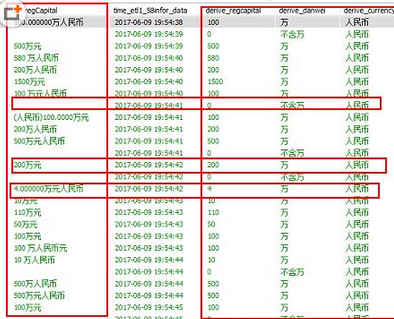
數(shù)據(jù)表數(shù)據(jù)清洗結(jié)果
七、增量數(shù)據(jù)處理
由于每天數(shù)據(jù)有增量進入����,因此第一次執(zhí)行完初始話之后���,我們要根據(jù)表中的時間戳字段進行判斷,讀取昨日新的數(shù)據(jù)進行清洗插入���,這部分留到下篇博客��。
初步計劃用下面函數(shù) 作為參數(shù) 判斷增量 create_time 是爬蟲腳本執(zhí)行時候?qū)懭氲臅r間���,yesterday是昨日時間,在where條件里加以限制�,取出昨天進入數(shù)據(jù)庫的數(shù)據(jù) 進行執(zhí)行 win7系統(tǒng)支持定時任務(wù)
import datetime
from datetime import datetime as dt
#%進行轉(zhuǎn)義使用%%來轉(zhuǎn)義
#主要構(gòu)造sql中條件“where create_time like %s%%“ % yesterday
#寫入腳本運行的當(dāng)前時間
def create_time(self):
create_time = dt.now().strftime('%Y-%m-%d %H:%M:%S')
return create_time
def yesterday(self):
yestoday= datetime.date.today()-datetime.timedelta(days=1)
return yestoday
以上這篇python數(shù)據(jù)處理實戰(zhàn)(必看篇)就是小編分享給大家的全部內(nèi)容了,希望能給大家一個參考
CDA數(shù)據(jù)分析師考試相關(guān)入口一覽(建議收藏):
? 想報名CDA認(rèn)證考試���,點擊>>>
“CDA報名”
了解CDA考試詳情�;
? 想學(xué)習(xí)CDA考試教材�,點擊>>> “CDA教材” 了解CDA考試詳情;
? 想加入CDA考試題庫���,點擊>>> “CDA題庫” 了解CDA考試詳情���;
? 想了解CDA考試含金量,點擊>>> “CDA含金量” 了解CDA考試詳情��;











 京公網(wǎng)安備 11010802034615號
經(jīng)營許可證編號:京B2-20210330
京公網(wǎng)安備 11010802034615號
經(jīng)營許可證編號:京B2-20210330