讓我去健身的不是漂亮小姐姐�,居然是貝葉斯統(tǒng)計
【導(dǎo)讀】為了大家可以對貝葉斯算法有更多的了解,人工智能頭條為大家整理過一篇關(guān)于貝葉斯算法的文章���。今天將為大家介紹利用貝葉斯統(tǒng)計的一個實踐案例�。通項目實踐達到學(xué)以致用的目的����,相信大家對貝葉斯統(tǒng)計的理解和掌握都可以更深入���,提煉出更精煉的內(nèi)容����。
▌前言
我來自越南,在新加坡上高中�,目前在美國上大學(xué)。我經(jīng)常聽到身邊的人取笑我看起來很“嬌小”�����,我應(yīng)該怎樣做運動��,去健身房增重,然后才能有“更好的體格”...
...然而我對這些評論卻是懷疑的,對于身高1.69米(5’6)和體重58kg(127lb)的人來說�����,我有接近完美的 BMI
指數(shù)(20.3)����。
后來我明白他們沒有在談?wù)?BMI����,他們強調(diào)的是體型。
想想看,他們的出發(fā)點是好的:資料顯示越南男性的平均身高與體重是1米62和58kg����,鑒于我身高高出了平均值,但體重與越南男性平均體重卻相同���,我可能會“看起來”更瘦一些��。
“看起來”圈起來劃重點��。
如果體重相同���,但是身高更高,那看起來更苗條更修長�����,這是一件邏輯很簡單的事����。而我在考慮這是一個值得進一步探究的科學(xué)問題。
那么問題來了�,在身高1米69的越南男性中,我的體型有多瘦?��?��?
我們需要一種方法論的方法來研究這個主題,一個好方法是盡可能多地找到越南男子身高和體重的數(shù)據(jù)�����,看看我的數(shù)據(jù)處于哪個位置��。
▌越南人口概況
在網(wǎng)上搜索后���,我找到了一份包含超過10,000名越南人的人口統(tǒng)計信息調(diào)查研究數(shù)據(jù)�。 我將樣本量范圍縮小到18-29歲年齡段的男性�。 這使我有383名年齡在18-29歲左右的越南男性的樣本,對于接下來的分析來說已經(jīng)是足夠的了����。
首先畫出人口重量直方圖,看看我在越南男性中哪個位置��。
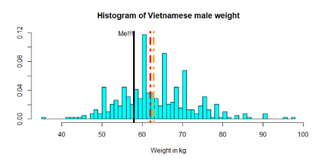
紅線顯示樣本的中位數(shù)����,橙色線顯示均值
這個圖表明��,我略低于這383名越南青年體重的平均數(shù)和中位數(shù)�。是好消息嗎���?
然而����,問題的重點并不在于我的體重與樣本相比如何�。假設(shè)越南男性人口的健康狀況良好,并且整個越南人口可以由這383個人代表��,但考慮到1米68的身高因素����,我們可以推斷出我的體重與整個越南人口相比是什么情況。
為此��,我們需要深入研究回歸分析��。
第一步繪制關(guān)于身高和體重的二維散點圖�。
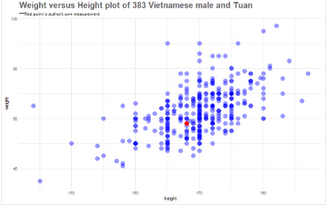
好吧,我的數(shù)據(jù)看起來處在很平均的位置上���。實際上��,如果我們只查看那些身高168cm的人的數(shù)據(jù)(想象一條在168cm處的垂直線�,并穿過紅點),那么我的體重比這些人稍輕一些�。
另一個觀察到的重要結(jié)果是���,散點圖的離散程度表明了越南男性的身高和體重之間存在著較強的線性關(guān)系�。我們將進行定量分析以深入了解這種關(guān)系���。
我們需要做的是快速添加“標準的最小二乘”線����。稍后我會更多地介紹這條線���,但現(xiàn)在先展示它����。
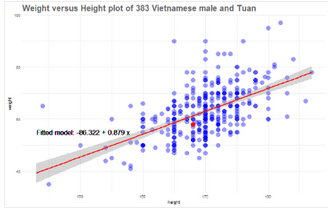
我們的最小二乘線是y = -86.32 + 0.889x��,會發(fā)現(xiàn)在我這個年齡的越南男性的通常情況是����,高1厘米體重就會增加0.88千克����。
但是���,這并不能回答我們的問題��。在身高為1米68時���,58公斤的體重會被認為是太重,太輕或只是平均�����?
為了更加定量地解釋這個問題����,如果我們有一個身高為1米68的人的分布,我的體重下降到25,50或75個百分點的幾率是多少��?
要做到這一點�,需要我們深入挖掘并理解回歸背后的理論。
▌線性回歸的理論
在線性回歸模型中���,Y變量的預(yù)期值(在我們的例子中�,人的體重)是X(高度)的線性函數(shù)。
我們稱之為線性關(guān)系�,其中 β0 和 β1 分別是截距和斜率; 也就是說,我們假設(shè)E(Y | X = x)= β0 + β1 * X����。
但是我們不知道 β0 和 β1 的值,因此它就是未知參數(shù)����。
在最標準的線性回歸模型中�����,我們進一步假設(shè)給定 X = x下Y的條件分布是正態(tài)分布的����。這意味著簡單的線性回歸模型:
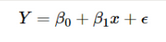
可以寫成下面的形式,注意��,在許多模型中���,我們可以用精度參數(shù) τ 替換方差參數(shù) σ�����,其中 τ = 1 / σ�。
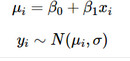
總結(jié):因變量 Y 服從滿足平均值 μi 和精度參數(shù) τ 的正態(tài)分布。 μi 與由 β0 和 β1 參數(shù)化的 X 是線性關(guān)系
最后����,我們還假設(shè)未知方差不依賴于 x ; 這個假設(shè)被稱為同方差���。
上述內(nèi)容可能有點多��,可以在下面這張圖中看到剛討論過的內(nèi)容��。
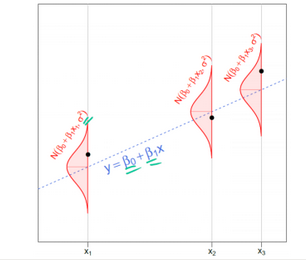
在實際的數(shù)據(jù)分析問題中���,我們只給出黑點(數(shù)據(jù))。我們的目標是使用這些數(shù)據(jù)�����,對我們不知道的事情做出推斷��,包括 β0�����,β1(陰影,藍色虛線)和 σ(紅色正常密度的寬度)��。 注意每個點周圍的正態(tài)分布看起來完全相同��。 這是同方差性的性質(zhì)�����。
▌參數(shù)估計
現(xiàn)在�,你可以通過幾種方法來估計
β0 和 β1。如果你使用最小二乘法來估計此類模型���,則不必擔(dān)心概率公式,因為你搜索 β0 和 β1
的最優(yōu)值的方式是使擬合值與預(yù)測值的平方誤差最小化�。另一種,可以使用最大似然估計來估計這種模型�,你可以通過最大化似然函數(shù)來尋找參數(shù)的最優(yōu)值。
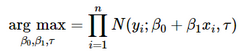
注意:一個有趣的結(jié)果是(這里沒有數(shù)學(xué)證明)�,如果我們進一步假設(shè)誤差也屬于正態(tài)分布,則最小二乘估計量也是最大似然估計量���。
▌使用貝葉斯觀點的線性回歸
貝葉斯方法不是單獨最大化似然函數(shù)���,而是假設(shè)了參數(shù)的先驗分布并使用貝葉斯定理:
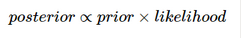
似然函數(shù)與上面的相同�,但是不同之處在于對待估計參數(shù)β0��,β1�����,τ假設(shè)了一些先驗分布并且將它們包括到了等式中:
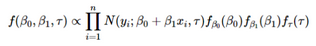
“ 什么是先驗����,為什么我們的方程看起來復(fù)雜了10倍?”
相信我���,這個先驗信息雖然看起來感覺有點奇怪���,但它非常直觀。事實是�,有一個非常強烈的哲學(xué)推理,為什么我們可以使用一些看似任意的分布來確定一個未知參數(shù)(在我們的例子中是β0�,β1,τ)�����。這些先驗分布是為了在看到數(shù)據(jù)之前捕捉我們對數(shù)據(jù)分布特點的看法。在觀察一些數(shù)據(jù)之后�,我們應(yīng)用貝葉斯規(guī)則來獲得這些未知參數(shù)的后驗分布,它考慮了先驗信息和數(shù)據(jù)�����。從這個后驗分布我們可以計算數(shù)據(jù)的預(yù)測分布����。
這些先驗分布是為了表達我們在看到數(shù)據(jù)之前,對數(shù)據(jù)分布特點的一種假設(shè)
最終的估計值將取決于(1)你的數(shù)據(jù)和(2)先驗信息����,但數(shù)據(jù)中包含的信息越多,先驗信息的作用就越小����。
“所以我可以選擇先驗分布嗎����?”
這是一個很好的問題,因為有無限的選擇��。
(理論上)只有一個正確的先驗�,即表示你的先驗假設(shè)。然而,在實踐中��,先驗分布的選擇可能相當(dāng)主觀����,有時甚至是任意的。 我們可以選擇標準偏差較大的正態(tài)先驗(小精度)�����。例如����,我們可以假設(shè)
β0 和 β1 是來自均值為 0 和標準差為 10,000
的正態(tài)分布。這被稱為無信息先驗�,因為基本上這種分布將是相當(dāng)平坦的(即,它為特定范圍內(nèi)的任何值分配幾乎相等的概率)�。
接下來,如果這種先驗分布是我們的選擇���,我們不必擔(dān)心哪個分布可能會更好����,因為它的形狀幾乎都是平坦的���,并且后驗分布并不關(guān)心先驗分布的分布情況特點�。
同樣,對于精度 τ����,我們知道這些必須是非負的,所以選擇一個限制為非負值的分布是有意義的��。例如��,我們可以使用低形狀和尺度參數(shù)的 Gamma 分布�����。
另一個有用的非信息選擇是均勻分布��。如果你選擇σ或τ的均勻分布����,你可能會得到John K. Kruschke所說的模型����。
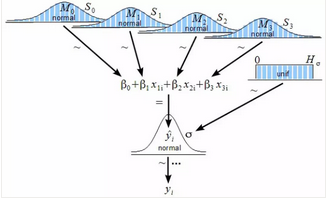
▌用R和JAGS進行仿真
迄今為止這個理論非常好�。求解方程在數(shù)學(xué)上具有挑戰(zhàn)性�����。 在絕大多數(shù)情況下����,后驗分布不會直接可用(正態(tài)分布和 Gamma 分布是多么的復(fù)雜���,你必須將其中的一系列數(shù)據(jù)乘在一起)�����。
馬爾可夫鏈蒙特卡羅方法通常用于估計模型的參數(shù)���。JAGS工具包幫助我們做到了這一點。
JAGS工具是基于馬爾可夫鏈蒙特卡羅(MCMC)的仿真過程�,能產(chǎn)生參數(shù)空間 θ =(β0;β1;τ)的許多迭代結(jié)果。 在該參數(shù)空間中為每個參數(shù)生成的樣本分布將接近該參數(shù)的總體分布�����。
為什么會這樣�? 解釋非常復(fù)雜。簡單的解釋就是:MCMC通過構(gòu)建具有目標后驗分布的馬爾可夫鏈�����,從而在后驗分布中生成樣本。
講真它并不好玩�。 與通常解析方程(2)的方式不同,我們可以做一些聰明的抽樣�,從數(shù)學(xué)角度證明我們樣本的分布是 β0,β1�����,τ 的實際分布����。
▌如何使用這個JAGS工具呢
我們在R中通過如下步驟運行JAGS
第一步,我們用文本格式編寫我們的模型:
然后��,我們使用JAGs進行模擬���。在這里,我設(shè)定 JAGs 模擬參數(shù)空間θ 10000次的值���。在這樣的采樣之后,我們可以得到如下所示θ=(β0;β1;τ)的采樣數(shù)據(jù)����。
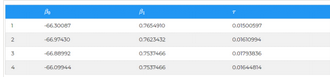
現(xiàn)在我們對參數(shù)空間θ進行10,000次迭代��,記住通過公式:
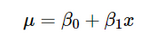
這意味著�,如果我們用 x = 168 cm 代替每次迭代����,我們將找到 10,000 個體重值,并且因此給出高度為 168 cm 的體重分布��。
我們現(xiàn)在是在給定身高條件下�����,計算我體重的百分位�。我們能做的就是根據(jù)我的身高找到我體重百分位數(shù)的分布�。
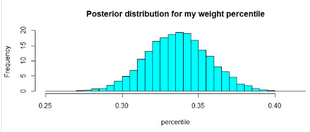
現(xiàn)在,這個圖告訴我們的是��,我的體重(給定168厘米的身高)最有可能位于越南人口模擬數(shù)據(jù)的0.3%左右����。例如�����,我們可以找到我的體重在前40個百分點或更少的百分位數(shù)�����。
所以絕大多數(shù)證據(jù)表明身高168厘米����,體重58公斤會使我處于越南人口分布中百分位數(shù)較低的位置���。也許是時候去健身房并增加一些體重了。畢竟��,如果你不能相信貝葉斯統(tǒng)計的結(jié)果���,你還能相信什么呢���?
CDA數(shù)據(jù)分析師考試相關(guān)入口一覽(建議收藏):
? 想報名CDA認證考試,點擊>>>
“CDA報名”
了解CDA考試詳情����;
? 想學(xué)習(xí)CDA考試教材�����,點擊>>> “CDA教材” 了解CDA考試詳情�;
? 想加入CDA考試題庫��,點擊>>> “CDA題庫” 了解CDA考試詳情���;
? 想了解CDA考試含金量,點擊>>> “CDA含金量” 了解CDA考試詳情�;











 京公網(wǎng)安備 11010802034615號
經(jīng)營許可證編號:京B2-20210330
京公網(wǎng)安備 11010802034615號
經(jīng)營許可證編號:京B2-20210330