資源 | 一個Python特征選擇工具����,助力實現(xiàn)高效機器學習
鑒于特征選擇在機器學習過程中的重要性����,數(shù)據(jù)科學家 William Koehrsen 近日在 GitHub 上公布了一個特征選擇器 Python 類��,幫助研究者更高效地完成特征選擇。本文是 Koehrsen 寫的項目介紹及案例演示文章����。
項目地址:https://github.com/WillKoehrsen/feature-selector
特征選擇(feature selection)是查找和選擇數(shù)據(jù)集中最有用特征的過程,是機器學習流程中的一大關鍵步驟��。不必要的特征會降低訓練速度����、降低模型可解釋性,并且最重要的是還會降低其在測試集上的泛化表現(xiàn)����。
目前存在一些專用型的特征選擇方法,我常常要一遍又一遍地將它們應用于機器學習問題�,這實在讓人心累。所以我用 Python 構建了一個特征選擇類并開放在了 GitHub 上����。這個 FeatureSelector 包含一些最常用的特征選擇方法:
1.具有高缺失值百分比的特征
2.共線性(高度相關的)特征
3.在基于樹的模型中重要度為零的特征
4.重要度較低的特征
5.具有單個唯一值(unique value)的特征
在本文中,我們將介紹在示例機器學習數(shù)據(jù)集上使用 FeatureSelector 的全過程�。我們將看到如何快速實現(xiàn)這些方法,從而實現(xiàn)更高效的工作流程�����。
完整代碼已在 GitHub 上提供,歡迎任何人貢獻�。這個特征選擇器是一項正在進行的工作,將根據(jù)社區(qū)需求繼續(xù)改進��!
示例數(shù)據(jù)集
為了進行演示�,我們將使用來自
Kaggle「家庭信用違約風險」機器學習競賽的一個數(shù)據(jù)樣本。了解該競賽可參閱:https://towardsdatascience.com/machine-learning-kaggle-competition-part-one-getting-started-32fb9ff47426����,完整數(shù)據(jù)集可在這里下載:https://www.kaggle.com/c/home-credit-default-risk/data。這里我們將使用部分數(shù)據(jù)樣本來進行演示���。

數(shù)據(jù)示例�。TARGET 是分類標簽
這個競賽是一個監(jiān)督分類問題��,這也是一個非常合適的數(shù)據(jù)集�����,因為其中有很多缺失值�����、大量高度關聯(lián)的(共線性)特征,還有一些無助于機器學習模型的無關特征�����。
創(chuàng)建實例
要創(chuàng)建一個 FeatureSelector 類的實例���,我們需要傳入一個結構化數(shù)據(jù)集,其中觀察在行中�,特征在列中。我們可以使用一些僅操作特征的方法��,但基于重要度的方法也需要訓練標簽����。因為這是一個監(jiān)督分類任務,所以我們將使用一組特征和一組標簽��。
(請確保在 feature_selector.py 所在目錄下運行這段代碼)
fromfeature_selectorimportFeatureSelector
# Features areintrain and labels areintrain_labels
fs = FeatureSelector(data = train, labels = train_labels)
方法
這個特征選擇器有 5 種用于查找待移除特征的方法�����。我們可以訪問任何已被識別出來的特征并通過人工方式將它們移出數(shù)據(jù)�,也可以使用 FeatureSelector 中的 remove 函數(shù)。
這里我們將介紹其中每種識別方法,還將展示如何同時運行這 5 種方法�。此外,F(xiàn)eatureSelector 還有幾個圖表繪制功能��,因為可視化地檢查數(shù)據(jù)是機器學習的一大關鍵部分��。
缺失值
查找和移除特征的第一個方法很簡單:查找缺失值比例超過特定閾值的特征���。下面的調用能識別缺失值比例超過 60% 的特征(粗體是輸出結果)���。
fs.identify_missing(missing_threshold =0.6)
17featureswithgreater than0.60missing values.
我們可以在一個 dataframe 中查看每一列的缺失值比例:
fs.missing_stats.head()
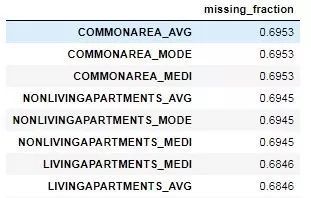
要查看待移除特征,我們可以讀取 FeatureSelector 的 ops 屬性���,這是一個 Python 特征詞典��,特征會以列表的形式給出��。
missing_features = fs.ops['missing']
missing_features[:5]
['OWN_CAR_AGE',
'YEARS_BUILD_AVG',
'COMMONAREA_AVG',
'FLOORSMIN_AVG',
'LIVINGAPARTMENTS_AVG']
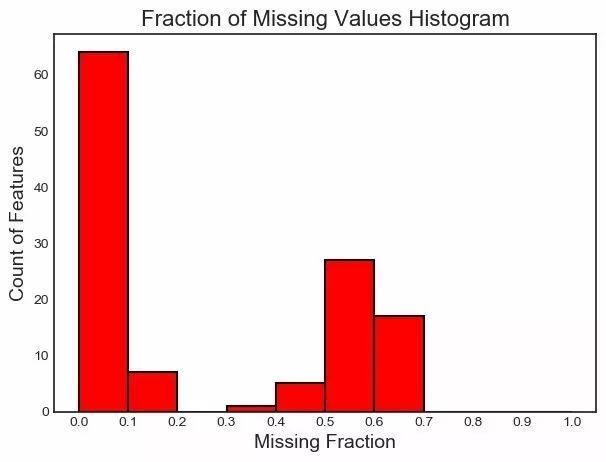
最后�,我們可以繪制一張所有特征的缺失值分布圖:
fs.plot_missing()
共線性特征
共線性特征是指彼此之間高度關聯(lián)的特征����。在機器學習領域,高方差和較低的模型可解釋性導致在測試集上的泛化能力下降���。
identify_collinear 方法能基于指定的相關系數(shù)值查找共線性特征���。對于每一對相關的特征�����,它都會標識出其中要移除的一個(因為我們只需要移除其中一個):
fs.identify_collinear(correlation_threshold =0.98)
21featureswitha correlation magnitude greater than0.98.
使用熱圖可以很好地可視化共線性����。下圖展示了所有至少有一個相關關系(correlation)超過閾值的特征:
fs.plot_collinear()

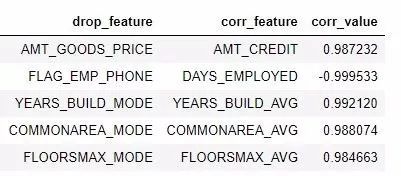
和之前一樣���,我們可以訪問將會被移除的整個相關特征列表,或者在一個 dataframe 中查看高度相關的特征對��。
# listofcollinear features to remove
collinear_features = fs.ops['collinear']
# dataframeofcollinear features
fs.record_collinear.head()
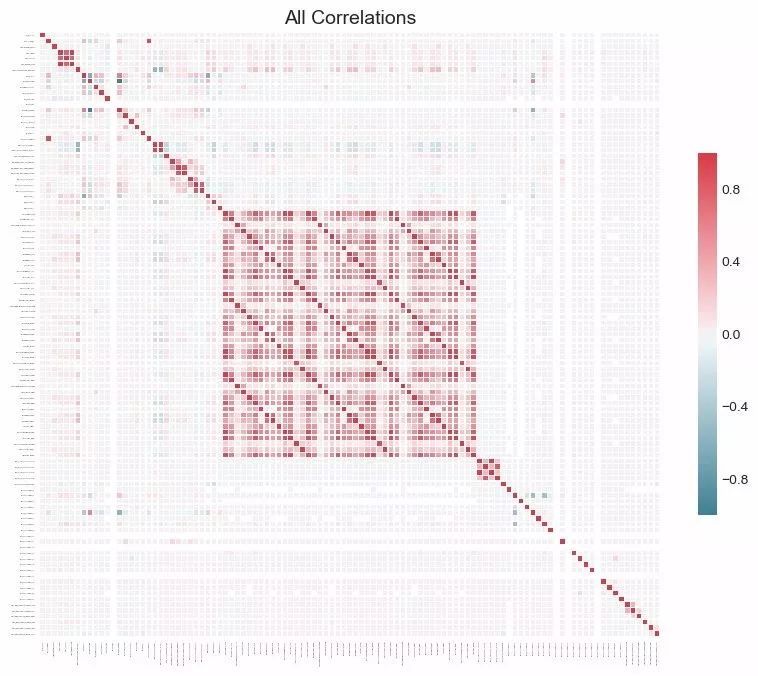
如果我們想全面了解數(shù)據(jù)集����,我們還可以通過將 plot_all = True 傳入該調用,繪制出數(shù)據(jù)中所有相關性的圖表:
零重要度特征
前面兩種方法可被應用于任何結構化的數(shù)據(jù)集并且結果是確定的——對于一個給定的閾值�����,每次結果都一樣�。接下來的方法是專為監(jiān)督式機器學習問題設計的,其中我們有訓練模型的標簽并且是非確定性的。identify_zero_importance
函數(shù)能根據(jù)梯度提升機(GBM)學習模型查找重要度為零的特征�。
我們可以使用基于樹的機器學習模型(比如
boosting
ensemble)求取特征重要度。這個重要度的絕對值沒有相對值重要��,我們可以將相對值用于確定對一個任務而言最相關的特征��。我們還可以通過移除零重要度特征來在特征選擇中使用特征重要度�。在基于樹的模型中,零重要度的特征不會被用于分割任何節(jié)點�����,所以我們可以移除它們而不影響模型表現(xiàn)���。
FeatureSelector
能使用來自 LightGBM 庫的梯度提升機來得到特征重要度��。為了降低方差�����,所得到的特征重要度是在 GBM 的 10
輪訓練上的平均�。另外����,該模型還使用早停(early stopping)進行訓練(也可關閉該選項)����,以防止在訓練數(shù)據(jù)上過擬合�����。
LightGBM 庫:http://lightgbm.readthedocs.io/
下面的代碼調用了該方法并提取出了零重要度特征:
# Passinthe appropriate parameters
fs.identify_zero_importance(task ='classification',
eval_metric ='auc',
n_iterations =10,
early_stopping = True)
# listofzero importance features
zero_importance_features = fs.ops['zero_importance']
63featureswithzero importance after one-hot encoding.
我們傳入的參數(shù)解釋如下:
-
task:根據(jù)我們的問題��,要么是「classification」��,要么是「regression」
-
eval_metric:用于早停的度量(如果早停禁用了�,就不必使用)
-
n_iterations:訓練輪數(shù),最后結果取多輪的平均
-
early_stopping:是否為訓練模型使用早停
這時候我們可以使用 plot_feature_importances 繪制兩個圖表:
# plot the feature importances
fs.plot_feature_importances(threshold =0.99, plot_n =12)
124features requiredfor0.99ofcumulative importance
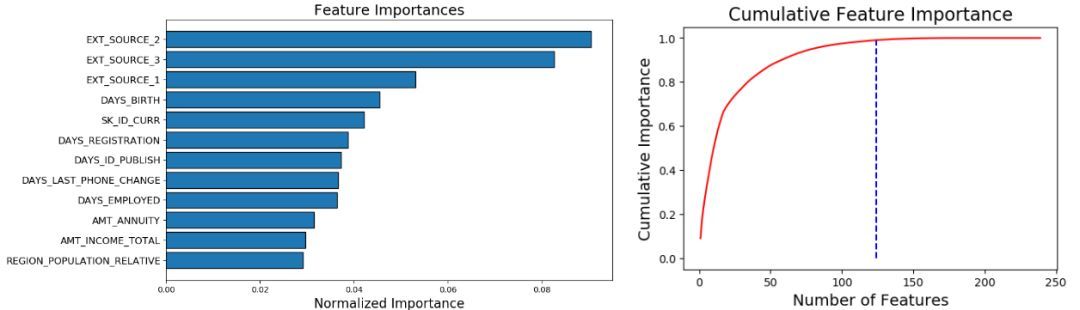
左圖給出了 plot_n 最重要的特征(重要度進行了歸一化����,總和為 1)�。右圖是對應特征數(shù)量的累積重要度。藍色豎線標出了累積重要度為 99% 的閾值����。
對于基于重要度的方法,有兩點需要記?�。?
-
訓練梯度提升機是隨機的�,這意味著模型每次運行后�����,特征重要度都會改變���。
這應該不會有太大的影響(最重要的特征不會突然就變成最不重要的),但這會改變某些特征的排序���,也會影響識別出的零重要度特征的數(shù)量����。如果特征重要度每次都改變����,請不要感到驚訝!
-
要訓練機器學習模型�,特征首先要經(jīng)過 one-hot 編碼。這意味著某些被識別為零重要度的特征可能是在建模過程中加入的 one-hot 編碼特征���。
當我們到達特征移除階段時�,還有一個選項可移除任何被添加進來的 one-hot 編碼的特征�����。但是,如果我們要在特征選擇之后做機器學習����,我們還是必須要 one-hot 編碼這些特征。
低重要度特征
接下來的方法基于零重要度函數(shù)�,使用來自模型的特征重要度來進一步選擇。identify_low_importance 函數(shù)能找到重要度最低的特征�����,這些特征無助于指定的總重要性���。
比如���,下面的調用能找到最不重要的特征,即使沒有這些特征也能達到 99% 的重要度�。
fs.identify_low_importance(cumulative_importance =0.99)
123features requiredforcumulative importanceof0.99after one hot encoding.
116featuresdonot contribute to cumulative importanceof0.99.
根據(jù)前面的累積重要度圖和這一信息,梯度提升機認為很多特征都與學習無關��。重申一下��,每次訓練運行后該方法的結果都不一樣�。
我們也可以在一個 dataframe 中查看所有特征重要度:
fs.feature_importances.head(10)
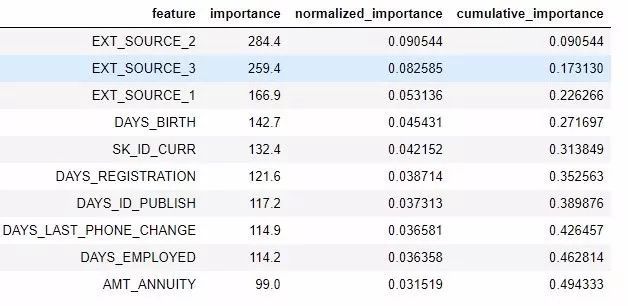
low_importance 方法借鑒了主成分分析(PCA)中的一種方法��,其中僅保留維持一定方差比例(比如 95%)所需的主成分是很常見的做法。要納入考慮的總重要度百分比基于同一思想����。
只有當我們要用基于樹的模型來做預測時,基于特征重要度的方法才真正有用��。除了結果隨機之外��,基于重要度的方法還是一種黑箱方法�,也就是說我們并不真正清楚模型認為某些特征無關的原因。如果使用這些方法���,多次運行它們看到結果的改變情況���,也許可以創(chuàng)建具有不同參數(shù)的多個數(shù)據(jù)集來進行測試!
單個唯一值特征
最后一個方法相當基礎:找出任何有單個唯一值的列���。僅有單個唯一值的特征不能用于機器學習��,因為這個特征的方差為 0���。舉個例子,如果一個特征僅有一個值�����,那么基于樹的模型就永遠不能進行區(qū)分(因為沒有可做區(qū)分的依據(jù))。
不同于其它方法�����,這個方法沒有可選參數(shù):
fs.identify_single_unique()
4featureswitha single unique value.
我們可以繪制每個類別唯一值數(shù)量的直方圖:
fs.plot_unique()
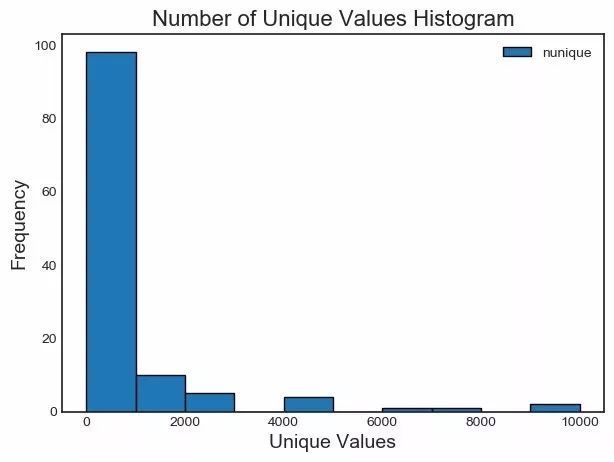
還有一點要記住��,在計算唯一值之前��,NaNs 已經(jīng)使用 Pandas 默認移除了�。
移除特征
在確定了待移除特征之后,我們有兩種移除它們的選擇����。所有要移除的特征都存儲在 FeatureSelector 的 ops 詞典中,我們可以使用這個列表來手動移除它們����,當然也可使用內置的 remove 函數(shù)。
對于這一方法����,我們需傳入要用于移除特征的 methods���。如果我們想使用所實現(xiàn)的所有方法���,我們只需使用 methods = 'all'
# Remove the featuresfromall methods (returns a df)
train_removed = fs.remove(methods ='all')
['missing','single_unique','collinear','zero_importance','low_importance'] methods have been run
Removed140features.
這個方法會返回一個包含被移除特征的 dataframe���。另外,要移除在機器學習過程中創(chuàng)建的 one-hot 編碼的特征:
train_removed_all = fs.remove(methods ='all', keep_one_hot=False)
Removed187features including one-hot features.
在執(zhí)行操作之前檢查將被移除的特征可能是個好想法����!原來的數(shù)據(jù)集會被存儲在 FeatureSelector 的 data 屬性中用作備份!
一次運行所有方法
除了單獨使用各個方法之外�,我們也可通過 identify_all 一次性使用所有方法。我們需要使用一個詞典來設定其中每個方法的參數(shù):
fs.identify_all(selection_params = {'missing_threshold':0.6,
'correlation_threshold':0.98,
'task':'classification',
'eval_metric':'auc',
'cumulative_importance':0.99})
151total features outof255identifiedforremoval after one-hot encoding.
注意�����,多次運行該模型的總特征數(shù)量可能也各不相同���。之后就可以調用 remove 函數(shù)來移除這些特征了�。
總結
這個特征選擇器類實現(xiàn)了訓練機器學習模型之前幾種用于移除特征的常見操作�����。其提供了可用于識別待移除特征的函數(shù)以及可視化函數(shù)。這些方法可以單獨使用���,也可以一次全部應用以實現(xiàn)高效的工作流程��。
其中
missing��、collinear 和 single_unique
方法是確定性的,而基于特征重要度的方法會隨每次運行而變化����。與機器學習領域很相似,特征選擇很大程度上是實證式的����,需要測試多種組合才能找到最優(yōu)解。最好的做法是在流程中嘗試多種配置�����,并且
FeatureSelector 提供了一種用于快速評估特征選擇參數(shù)的方法���。
CDA數(shù)據(jù)分析師考試相關入口一覽(建議收藏):
? 想報名CDA認證考試��,點擊>>>
“CDA報名”
了解CDA考試詳情���;
? 想學習CDA考試教材���,點擊>>> “CDA教材” 了解CDA考試詳情��;
? 想加入CDA考試題庫�����,點擊>>> “CDA題庫” 了解CDA考試詳情����;
? 想了解CDA考試含金量���,點擊>>> “CDA含金量” 了解CDA考試詳情���;











 京公網(wǎng)安備 11010802034615號
經(jīng)營許可證編號:京B2-20210330
京公網(wǎng)安備 11010802034615號
經(jīng)營許可證編號:京B2-20210330