數據科學入門丨選Python還是R
對于想入門數據科學的新手來說�����,選擇學Python還是R語言是一個難題�����,本文對兩種語言進行了比較�,希望能幫助你做出選擇。
我是德勤的數據科學家主管��,多年來我一直在使用Python和R語言��,并且與Python社區(qū)密切合作了15年���。本文是我對這兩種語言的一些個人看法。
第三種選擇
針對這個問題��,Studio的首席數據科學家Htley Wickham認為�,比起在二者中選其一,更好的選擇是讓兩種語言合作��。因此����,這也是我提到的第三種選擇,我在文本最后部分會探討���。
如何比較R和Python
對于這兩種語言�����,有以下幾點值得進行比較:
· 歷史:
R和Python的發(fā)展歷史明顯不同�,同時有交錯的部分。
· 用戶群體:
包含許多復雜的社會學人類學因素���。
· 性能:
詳細比較以及為何難以比較��。
· 第三方支持:
模塊����、代碼庫��、可視化���、存儲庫�����、組織和開發(fā)環(huán)境�。
· 用例:
根據具體任務和工作類型有不同的選擇��。
· 是否能同時使用:
在Python中使用R����,在R中使用Python�。
· 預測:
內部測試��。
· 企業(yè)和個人偏好:
揭曉最終答案��。
歷史

簡史:
ABC語言 - > Python 問世(1989年由Guido van Rossum創(chuàng)立) - > Python 2(2000年) - > Python 3(2008年)
Fortan語言 - > S語言(貝爾實驗室) - > R語言問世(1991年由Ross Ihaka和Robert Gentleman創(chuàng)立) - > R 1.0.0(2000年) - > R 3.0.2(2013年)
用戶群體
在比較Python與R的使用群體時��,要注意:
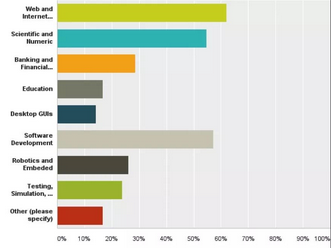
只有50%的Python用戶在同時使用R��。
假設使用R語言的程序員都用R進行相關“科學和數字”研究����。可以確定無論程序員的水平如何���,這種統(tǒng)計分布都是真實。
這里回到第二個問題��,有哪些用戶群體�。整個科學和數字社區(qū)包含幾個子群體,當中存在一些重疊����。
使用Python或R語言的子群體:
· 深度學習
· 機器學習
· 高級分析
· 預測分析
· 統(tǒng)計
· 探索和數據分析
· 學術科研
· 大量計算研究領域
雖然每個領域幾乎都服務于特定群體���,但在統(tǒng)計和探索等方面,使用R語言更為普遍���。在不久之前進行數據探索時�,比起Python�,R語言花的時間更少,而且使用Python還需要花時間進行安裝���。
這一切都被稱為Jupyter Notebooks和Anaconda的顛覆性技術所改變���。
Jupyter Notebook:增加了在瀏覽器中編寫Python和R代碼的能力;
Anaconda:能夠輕松安裝和管理Python和R。
現(xiàn)在�����,你可以在友好的環(huán)境中啟動和運行Python或R��,提供開箱即用的報告和分析���,這兩項技術消除了完成任務和選擇喜歡語言間的障礙。Python現(xiàn)在能以獨立于平臺的方式打包��,并且更快地提供快速簡單的分析。
社區(qū)中影響語言選擇的另一個因素是“開源”�。不僅僅是開源的庫,還有協(xié)作社區(qū)對開源的影響��。諷刺的是�,Tensorflow和GNU
Scientific
Library等開源軟件(分別是Apache和GPL)都與Python和R綁定。雖然使用R語言的用戶很多��,但使用Python的用戶中有很多純粹的Python支持者�����。另一方面��,更多的企業(yè)使用R語言����,特別是那些有統(tǒng)計學背景的。
最后��,關于社區(qū)和協(xié)作����,Github對Python的支持更多�����。如果看到最近熱門的Python包,會發(fā)現(xiàn)Tensorflow等項目有超過3.5萬的用戶收藏�。但看到R的熱門軟件包,Shiny����、Stan等的收藏量則低于2千。
性能
這方面不容易進行比較����。
原因是需要測試的指標和情況太多。很難在任何一個特定硬件上測試���。有些操作通過其中一種語言優(yōu)化�����,而不是另一種��。
循環(huán)
在此之前讓我們想想���,如何比較Python與R。你真的想在R語言寫很多循環(huán)嗎���?畢竟這兩種語言的設計意圖不太相同����。
{
"cells": [
{
"cell_type": "code",
"execution_count": 1,
"metadata": {},
"outputs": [],
"source": [
"import numpy as np\n",
"%load_ext rpy2.ipython"
]
},
{
"cell_type": "code",
"execution_count": 2,
"metadata": {},
"outputs": [],
"source": [
"def do_loop(u1):\n",
"\n",
" # Initialize `usq`\n",
" usq = {}\n",
"\n",
" for i in range(100):\n",
" # i-th element of `u1` squared into `i`-th position of `usq`\n",
" usq[i] = u1[i] * u1[i]\n"
]
},
{
"cell_type": "code",
"execution_count": 3,
"metadata": {},
"outputs": [],
"source": [
"%%R\n",
"do_loop <- function(u1) {\n",
" \n",
" # Initialize `usq`\n",
" usq <- 0\n",
"\n",
" for(i in 1:100) {\n",
" # i-th element of `u1` squared into `i`-th position of `usq`\n",
" usq[i] <- u1[i]*u1[i]\n",
" }\n",
"\n",
"}"
]
},
{
"cell_type": "code",
"execution_count": 4,
"metadata": {},
"outputs": [
{
"name": "stdout",
"output_type": "stream",
"text": [
"1.58 ms ± 42.8 μs per loop (mean ± std. dev. of 7 runs, 1000 loops each)\n"
]
}
],
"source": [
"%%timeit -n 1000\n",
"%%R\n",
"u1 <- rnorm(100)\n",
"do_loop(u1)"
]
},
{
"cell_type": "code",
"execution_count": 5,
"metadata": {},
"outputs": [
{
"name": "stdout",
"output_type": "stream",
"text": [
"36.9 μs ± 5.99 μs per loop (mean ± std. dev. of 7 runs, 1000 loops each)\n"
]
}
],
"source": [
"%%timeit -n 1000\n",
"u1 = np.random.randn(100)\n",
"do_loop(u1)"
]
}
],
"metadata": {
"kernelspec": {
"display_name": "Python 3",
"language": "python",
"name": "python3"
},
"language_info": {
"codemirror_mode": {
"name": "ipython",
"version": 3
},
"file_extension": ".py",
"mimetype": "text/x-python",
"name": "python",
"nbconvert_exporter": "python",
"pygments_lexer": "ipython3",
"version": "3.6.3"
}
},
"nbformat": 4,
"nbformat_minor": 2
}
Python為0.000037秒,R為0.00158秒
包括加載時間和在命令行上運行:R需要0.238秒�����,Python需要0.147秒�。強調,這并不是科學嚴謹的測試��。
測試證明��,Python的運行速度明顯加快�。通常這并沒有太大影響。
除了運行速度外�,對于數據科學家而言哪種性能更重要?兩種語言之所以受歡迎是因為它們能被用作命令語言�����。例如���,在使用Python時大多時候我們都很依賴Pandas��。這涉及到每種語言中模塊和庫�,以及其執(zhí)行方式���。
第三方支持
Python有PyPI�,R語言有CRAN�����,兩者都有Anaconda�。
CRAN使用內置的install.packages命令。目前��,CRAN上有大約1.2萬個包��。其中超過1/2的包都能用于數據科學�。
PyPi中包的數量超過前者的10倍,約有14.1萬個包����。專門用于科學工程的有3700個。其中有些也可以用于科學��,但沒有被標記。
在兩者中都有重復的情況�。當搜索“隨機森林”時,PyPi中可以得到170個項目���,但這些包并不相同��。
盡管Python包的數量是R的10倍�,但數據科學相關的包的數量大致相同�。
運行速度
比較DataFrames和Pandas更有意義。
我們進行了一項實驗:比較針對復雜探索任務的執(zhí)行時間�,結果如下:
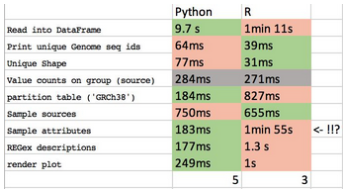
在大多數任務中Python運行速度更快。
來源:
http://nbviewer.jupyter.org/gist/brianray/4ce15234e6ac2975b335c8d90a4b6882
可以看到��,Python + Pandas比原生的R語言DataFrames更快�����。注意��,這并不意味著Python運行更快����,Pandas 是基于Numpy用C語言編寫的。
可視化
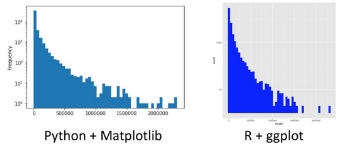
這里將ggplot2與matplotlib進行比較���。
matplotlib是由John D. Hunter編寫的��,他是我在Python社區(qū)中最敬重的人之一����,他也是教會我使用Python的人����。
Matplotlib雖然不易學習但能進行定制和擴展。ggplot難以進行定制�,有些人認為它更難學。
如果你喜歡漂亮的圖表�����,而且無需自定義���,那么R是不錯的選擇��。如果你要做更多的事情�����,那么Matplotlib甚至交互式散景都不錯�����。同樣�,R的ShinnyR能夠增加交互性。
是否能同時使用
可能你會問�,為什么不能同時使用Python和R語言?
以下情況你可以同時使用這兩種語言:
· 公司或組織允許;
· 兩種都能在你的編程環(huán)境中輕松設置和維護�����;
· 你的代碼不需要進入另一個系統(tǒng)����;
· 不會給合作的人帶來麻煩和困擾。
一起使用兩種語言的方法是:
· Python提供給R的包:如rpy2���、pyRserve�、Rpython等��;
· R也有相對的包:rPython�、PythonInR、reticulate���、rJython����,SnakeCharmR、XRPython
· 使用Jupyter���,同時使用兩者�����,例子如下:
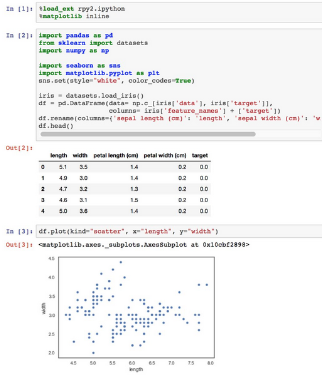
之后可以傳遞pandas的數據框,接著通過rpy2自動轉換為R的數據框��,并用“-i df”轉換:
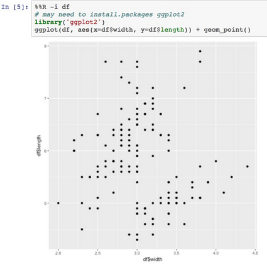
來源:
http://nbviewer.jupyter.org/gist/brianray/734bd54f468d9a6db9171b2cfc98405a
預測
Kaggle上有人對開發(fā)者使用R還是Python寫了一個Kernel��。他根據數據發(fā)現(xiàn)以下有趣的結果:

· 如果你打算明年轉向Linux��,則更可能是Python用戶�;
· 如果你研究統(tǒng)計數據,則更可能使用R��;如果研究計算機科學����,則更可能使用Python;
· 如果你還年輕(18-24歲)�����,則更可能是Python用戶;
· 如果你參加編程比賽���,則更可能是Python用戶�;
· 如果你明年想使用Android���,則更可能是Python用戶���;
· 如果你想在明年學習SQL,則更可能是R用戶�;
· 如果你使用MS office,則更可能是R用戶����;
· 如果你想在明年使用Rasperry Pi,則更可能是Python用戶�����;
· 如果你是全日制學生����,則更可能是Python用戶�;
· 如果你使用的敏捷方法(Agile methodology)���,則更可能是Python用戶��;
· 如果對待人工智能����,比起興奮你更持擔心態(tài)度��,則更可能是R用戶����。
企業(yè)和個人偏好
當我與Googler和Stack Overflow的大神級人物Alex Martelli交流時��,他向我解釋了為什么Google最開始只官方支持少數幾種語言�����。即使是在Google相對開發(fā)的環(huán)境中���,也存在一些限制和偏好,其他企業(yè)也是如此�。
除了企業(yè)偏好��,企業(yè)中第一個使用某種語言的人也會起到決定性作用�。第一個在德勤使用R的人他目前仍在公司工作����,目前擔任首席數據科學家。我的建議是�����,選擇你喜歡的語言�,熱愛你選擇的語言,起到領導作用����,并熱愛你的事業(yè)。
當你在研究某些重要的內容時�,犯錯是難以避免的。然而��,每個精心設計的數據科學項目都為數據科學家留有一些空間�����,讓他們進行實驗和學習��。重要的是保持開放的心態(tài),擁抱多樣性���。
最后就我個人而言���,我主要使用Python�����,之后我期待學習更多R的內容�。
CDA數據分析師考試相關入口一覽(建議收藏):
? 想報名CDA認證考試���,點擊>>>
“CDA報名”
了解CDA考試詳情�����;
? 想學習CDA考試教材�����,點擊>>> “CDA教材” 了解CDA考試詳情���;
? 想加入CDA考試題庫�,點擊>>> “CDA題庫” 了解CDA考試詳情�����;
? 想了解CDA考試含金量�,點擊>>> “CDA含金量” 了解CDA考試詳情�;











 京公網安備 11010802034615號
經營許可證編號:京B2-20210330
京公網安備 11010802034615號
經營許可證編號:京B2-20210330