入門(mén) | 一文帶你了解Python集合與基本的集合運(yùn)算
一般我們熟悉
Python 中列表�、元組及字典等數(shù)據(jù)結(jié)構(gòu),但集合可能用得稍微少一點(diǎn)。但集合獨(dú)特的元素唯一性與 O(1)
時(shí)間復(fù)雜度的成員檢測(cè)方法��,令其在很多任務(wù)中有特別的優(yōu)勢(shì)�。本文介紹了 Python
集合的常見(jiàn)方法與概念����,包括集合元素的操作、基本集合運(yùn)算以及不可變集等�。
了解 Python 集合: 它們是什么,如何創(chuàng)建它們�,何時(shí)使用它們,什么是內(nèi)置函數(shù)����,以及它們與集合論操作的關(guān)系
集合、 列表與元組
列表(list)和元組(tuple)是標(biāo)準(zhǔn)的
Python 數(shù)據(jù)類型�����,它們將值存儲(chǔ)在一個(gè)序列中���。集合(set)是另一種標(biāo)準(zhǔn)的 Python
數(shù)據(jù)類型����,它也可用于存儲(chǔ)值�����。它們之間主要的區(qū)別在于�,集合不同于列表或元組,集合中的每一個(gè)元素不能出現(xiàn)多次���,并且是無(wú)序存儲(chǔ)的��。
Python 集合的優(yōu)勢(shì)
由于集合中的元素不能出現(xiàn)多次���,這使得集合在很大程度上能夠高效地從列表或元組中刪除重復(fù)值,并執(zhí)行取并集��、交集等常見(jiàn)的的數(shù)學(xué)操作�����。
本教程將向你介紹一些關(guān)于 Python 集合和集合論的話題:
-
如何初始化空集和帶有數(shù)值的集合
-
如何向集合中添加值或者從集合中刪除值
-
如何高效地使用集合���,用于成員檢測(cè)����、從列表中刪除重復(fù)值等任務(wù)。
-
如何執(zhí)行常見(jiàn)的集合操作�����,例如求并集���、交集�����、差集以及對(duì)稱差����。
-
可變集合和不可變集之間的區(qū)別
有了這個(gè)提綱����,讓我們開(kāi)始吧。
集合初始化
集合是一個(gè)擁有確定(唯一)的���、不變的的元素��,且元素?zé)o序的可變的數(shù)據(jù)組織形式����。
你可以使用「set()」操作初始化一個(gè)空集���。
emptySet = set()
如果要初始化一個(gè)帶有值的集合���,你可以向「set()」傳入一個(gè)列表。
dataScientist = set(['Python','R','SQL','Git','Tableau','SAS'])
dataEngineer = set(['Python','Java','Scala','Git','SQL','Hadoop'])

如果你觀察一下上面的「dataScientist」和「dataEngineer」集合中的變量�,就會(huì)發(fā)現(xiàn)集合中元素值的順序與添加時(shí)的順序是不同的,這是因?yàn)榧鲜菬o(wú)序的�。
集合包含的值也可以通過(guò)花括號(hào)來(lái)初始化。
dataScientist = {'Python','R','SQL','Git','Tableau','SAS'}
dataEngineer = {'Python','Java','Scala','Git','SQL','Hadoop'}

請(qǐng)牢記��,花括號(hào)只能用于初始化包含值的集合����。如下圖所示,使用不包含值的花括號(hào)是初始化字典(dict)的方法之一�����,而不是初始化集合的方法����。

向集合添加值或刪除值
要想向集合中添加值或從中刪除值���,你首先必須初始化一個(gè)集合。
# Initialize setwithvalues
graphicDesigner = {'InDesign','Photoshop','Acrobat','Premiere','Bridge'}
向集合中添加值
你可以使用「add」方法向集合中添加一個(gè)值��。
graphicDesigner.add('Illustrator')

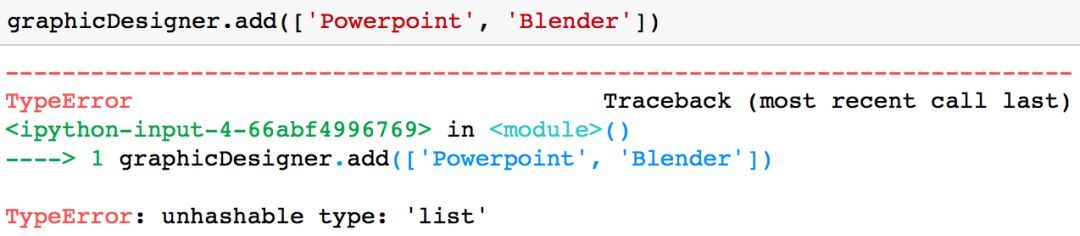
需要注意的一點(diǎn)是��,你只能將不可變的值(例如一個(gè)字符串或一個(gè)元組)加入到集合中�。舉例而言,如果你試圖將一個(gè)列表(list)添加到集合中���,系統(tǒng)會(huì)返回類型錯(cuò)誤「TyprError」���。
graphicDesigner.add(['Powerpoint','Blender'])
從集合中刪除值
有好幾種方法可以從集合中刪除一個(gè)值:
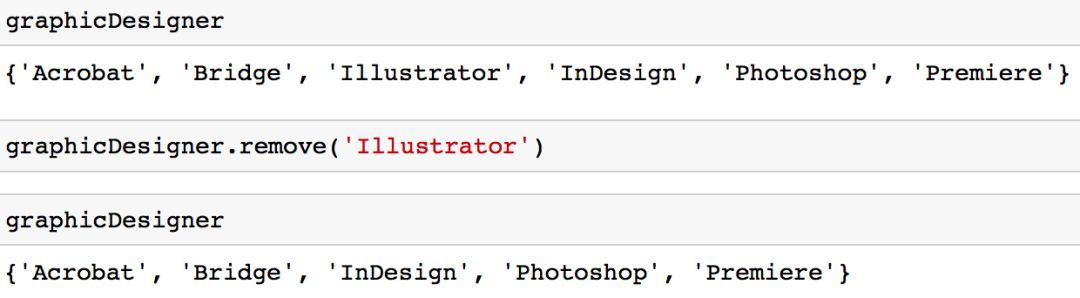
選項(xiàng) 1:你可以使用「remove」方法從集合中刪除一個(gè)值。
graphicDesigner.remove('Illustrator')
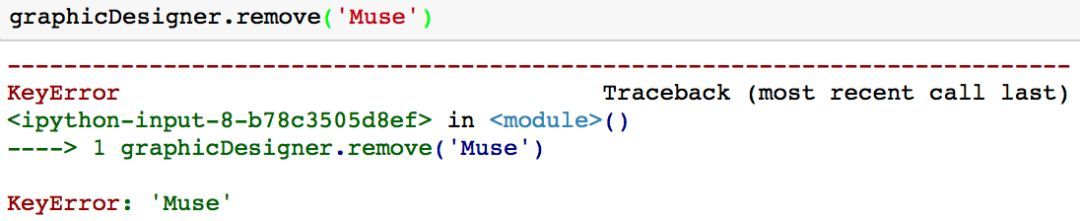
這種方法的一個(gè)缺點(diǎn)是�����,如果你想要?jiǎng)h除一個(gè)集合中不存在的值���,系統(tǒng)會(huì)返回一個(gè)鍵值錯(cuò)誤「KeyError」����。
選項(xiàng) 2:你可以使用「discard」方法從集合中刪除一個(gè)值。
graphicDesigner.discard('Premiere')

這種方法相對(duì)于「remove」方法的好處是����,如果你試圖刪除一個(gè)集合中不存在的值���,系統(tǒng)不會(huì)返回「KeyError」���。如果你熟悉字典(dict)數(shù)據(jù)結(jié)構(gòu),你可能會(huì)發(fā)現(xiàn)這種方法與字典的「get」方法的工作模式相似����。
選項(xiàng) 3:你還可以使用「pop」方法從集合中刪除并且返回一個(gè)任意的值。
graphicDesigner.pop()

需要注意的是�,如果集合是空的,該方法會(huì)返回一個(gè)「KeyError」�。
刪除集合中所有的值
你可以使用「clear」方法刪除集合中所有的值。
graphicDesigner.clear()

在集合上進(jìn)行迭代
與許多標(biāo)準(zhǔn) Python 數(shù)據(jù)類型一樣�,用戶可以在集合(set)上進(jìn)行迭代。
# Initialize a set
dataScientist = {'Python','R','SQL','Git','Tableau','SAS'}
forskillindataScientist:
print(skill)

如果你仔細(xì)觀察「dataScientist」集合中打印出來(lái)的每一個(gè)值��,你會(huì)發(fā)現(xiàn)集合中的值被打印出來(lái)的順序與它們被添加的順序是不同的���。
將集合中的值變?yōu)橛行?
本教程已經(jīng)向大家強(qiáng)調(diào)了集合是無(wú)序的��。如果你認(rèn)為你需要以有序的形式從集合中取出值���,你可以使用「sorted」函數(shù)���,它會(huì)輸出一個(gè)有序的列表。
type(sorted(dataScientist))

下面的代碼按照字母降序(這里指 Z-A)輸出「dataScientist」集合中的值����。
sorted(dataScientist, reverse = True)

刪除列表中的重復(fù)項(xiàng)
首先我們必須強(qiáng)調(diào)的是,集合是從列表(list)中刪除重復(fù)值的最快的方法���。為了證明這一點(diǎn)�,讓我們研究以下兩種方法之間的差異���。
方法 1:使用集合刪除列表中的重復(fù)值���。
print(list(set([1,2,3,1,7])))
方法 2:使用一個(gè)列表推導(dǎo)式(list comprehension)從一個(gè)列表中刪除重復(fù)值。
def remove_duplicates(original):
unique = []
[unique.append(n)forninoriginalifn notinunique]
return(unique)
print(remove_duplicates([1,2,3,1,7]))
性能的差異可以用「timeit」庫(kù)來(lái)測(cè)量��,這個(gè)庫(kù)允許你對(duì) Python 代碼進(jìn)行計(jì)時(shí)����。下面的代碼將每種方法運(yùn)行了 10,000 次����,并且以秒為單位輸出了總計(jì)時(shí)間�。
importtimeit
# Approach1: Execution time
print(timeit.timeit('list(set([1, 2, 3, 1, 7]))', number=10000))
# Approach2: Execution time
print(timeit.timeit('remove_duplicates([1, 2, 3, 1, 7])', globals=globals(), number=10000))

對(duì)比這兩種方法,結(jié)果表明����,使用集合刪除重復(fù)值是更加高效的��。雖然時(shí)間差異看似很小�����,但實(shí)際上在有一個(gè)非常大的列表時(shí)�����,能幫你節(jié)省很多的時(shí)間��。
集合運(yùn)算方法
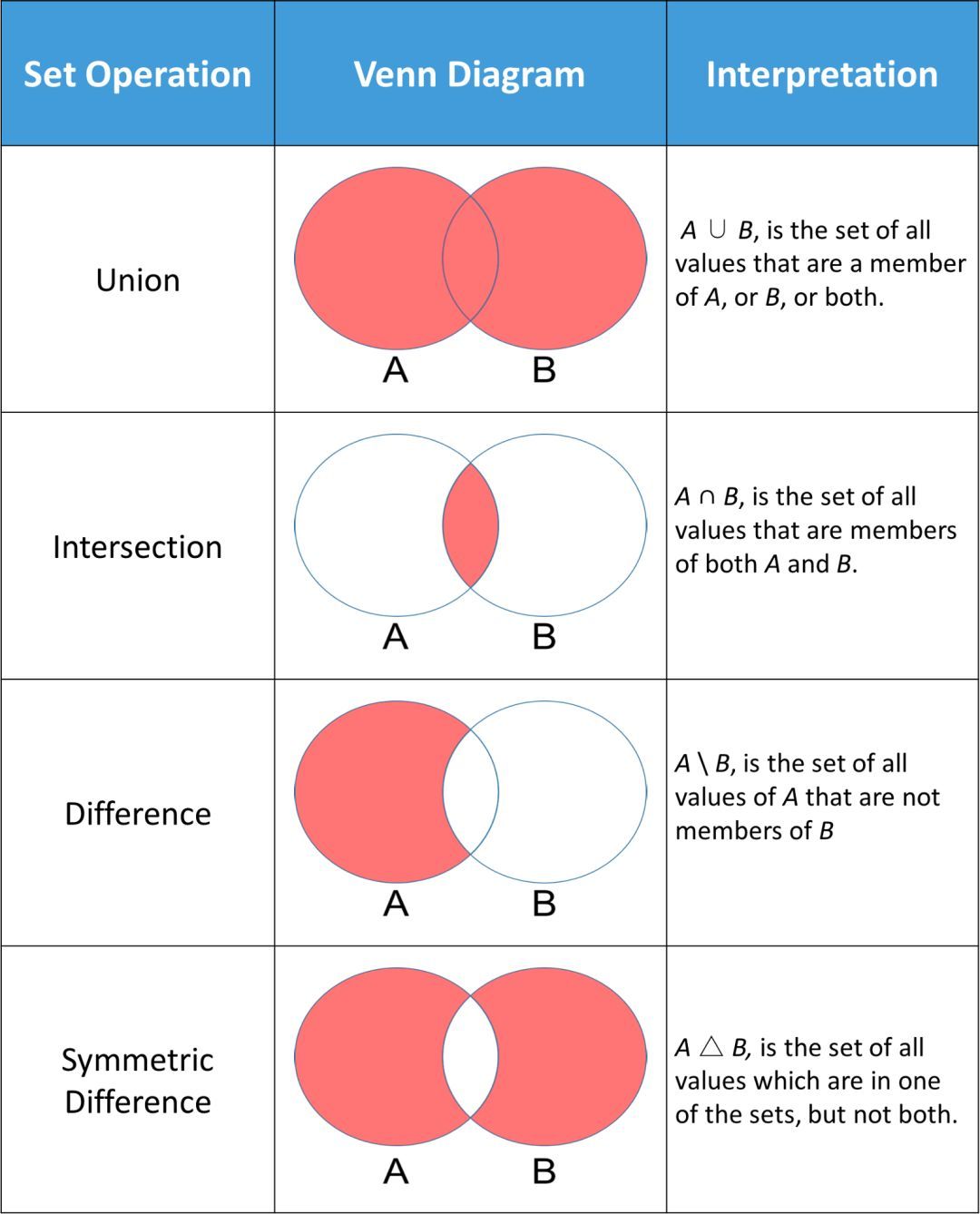
Python 中常用的集合方法是執(zhí)行標(biāo)準(zhǔn)的數(shù)學(xué)運(yùn)算���,例如:求并集���、交集��、差集以及對(duì)稱差��。下圖顯示了一些在集合 A 和集合 B 上進(jìn)行的標(biāo)準(zhǔn)數(shù)學(xué)運(yùn)算�。每個(gè)韋恩(Venn)圖中的紅色部分是給定集合運(yùn)算得到的結(jié)果���。
Python 集合有一些讓你能夠執(zhí)行這些數(shù)學(xué)運(yùn)算的方法��,還有一些給你等價(jià)結(jié)果的運(yùn)算符�����。在研究這些方法之前�,讓我們首先初始化「dataScientist」和「dataEngineer」這兩個(gè)集合�。
dataScientist = set(['Python','R','SQL','Git','Tableau','SAS'])
dataEngineer = set(['Python','Java','Scala','Git','SQL','Hadoop'])
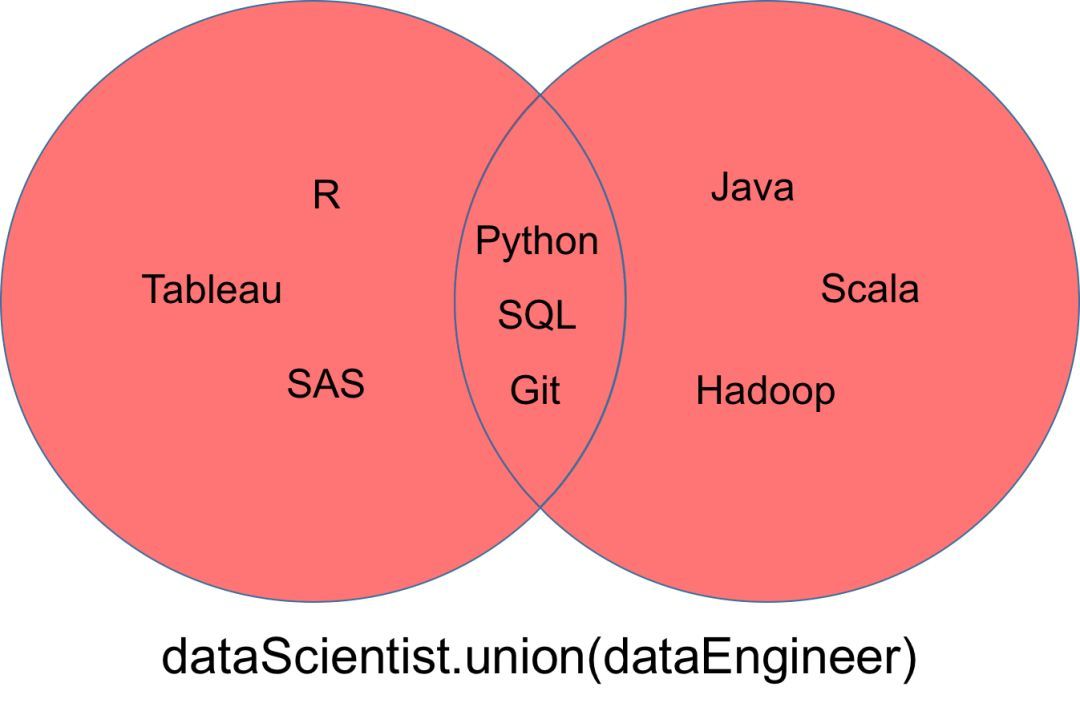
并集
一個(gè)表示為「dataScientist ∪ dataEngineer」的并集,是屬于「dataScientist」或「dataEngineer」或同時(shí)屬于二者元素的集合����。你可以使用「union」方法找出兩個(gè)集合中所有唯一的值。
# set built-infunctionunion
dataScientist.union(dataEngineer)
#EquivalentResult
dataScientist|dataEngineer

求并集操作返回的集合可以被可視化為下面的韋恩(Venn)圖中的紅色部分����。
交集
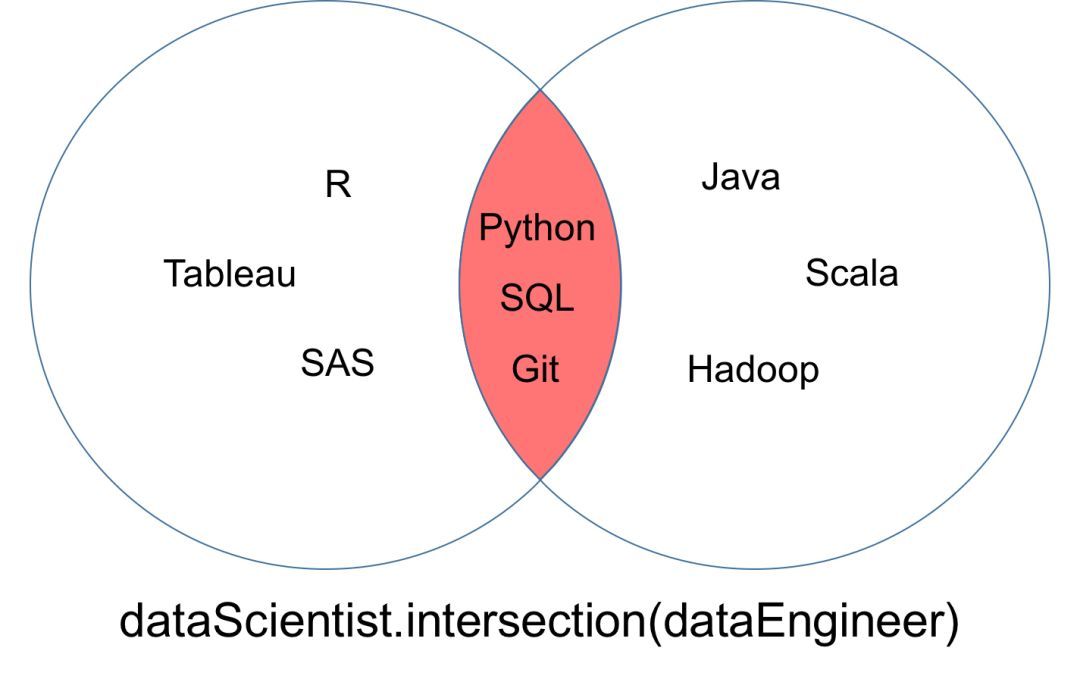
集合「dataScientist」和「dataEngineer」的交集可以表示為「dataScientist ∩ dataEngineer」,是所有同時(shí)屬于兩個(gè)集合的元素集合�。
# Intersection operation
dataScientist.intersection(dataEngineer)
# Equivalent Result
dataScientist & dataEngineer

交集運(yùn)算返回的集合可以被可視化為下面韋恩圖中的紅色部分���。
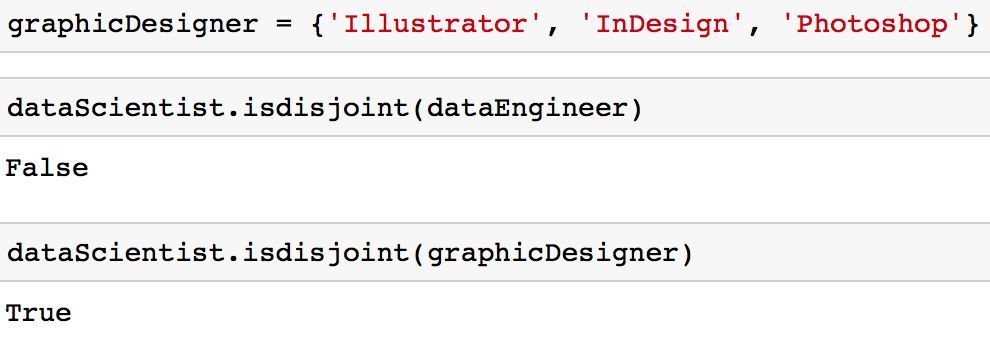
你可能會(huì)發(fā)現(xiàn),你會(huì)遇到你想確保兩個(gè)集合沒(méi)有共同值的情況����。換句話說(shuō),你想得到兩個(gè)交集為空的集合����。這兩個(gè)集合稱為互斥集合,你可以使用「isdisjoint」方法測(cè)試兩個(gè)集合是否為互斥��。
# Initialize a set
graphicDesigner = {'Illustrator','InDesign','Photoshop'}
# These sets have elementsincommon so it wouldreturnFalse
dataScientist.isdisjoint(dataEngineer)
# These sets have no elementsincommon so it wouldreturnTrue
dataScientist.isdisjoint(graphicDesigner)
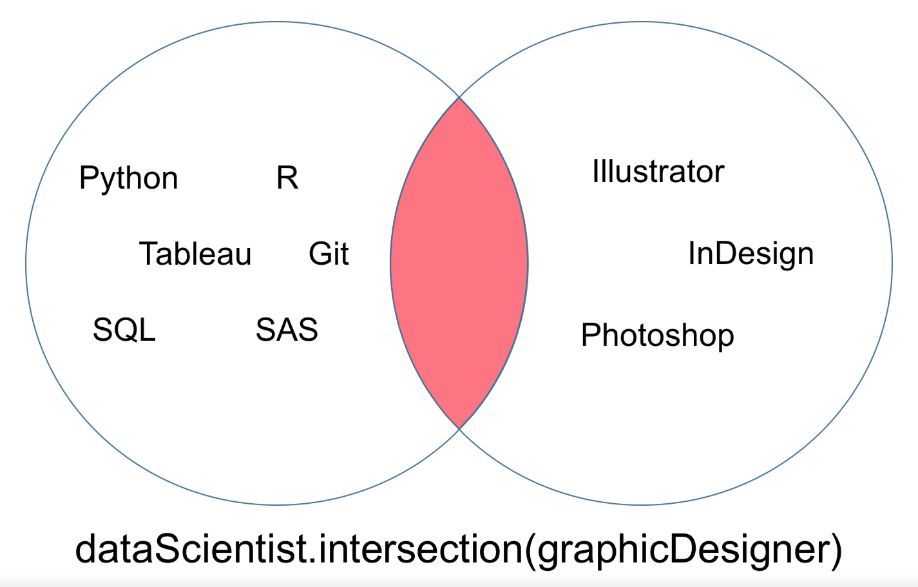
你會(huì)注意到����,在如下韋恩圖所示的交集中�,「dataScientist」和「graphicDesigner」沒(méi)有共有的值。
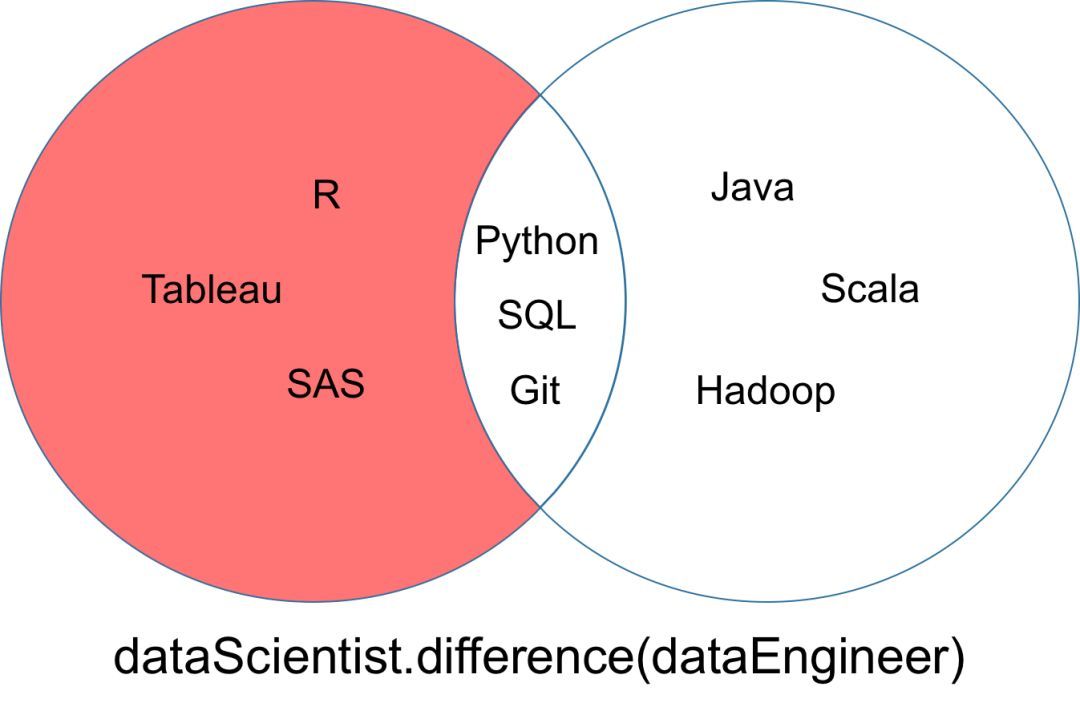
差集
集合「dataScientist」和「dataEngineer」的差集可以表示為「dataScientist dataEngineer」����,是所有屬于「dataScientist」但不屬于「dataEngineer」的元素集合。
# Difference Operation
dataScientist.difference(dataEngineer)
# Equivalent Result
dataScientist - dataEngineer

差集運(yùn)算返回的結(jié)果可以被可視化為以下韋恩圖中的紅色部分�。
對(duì)稱集
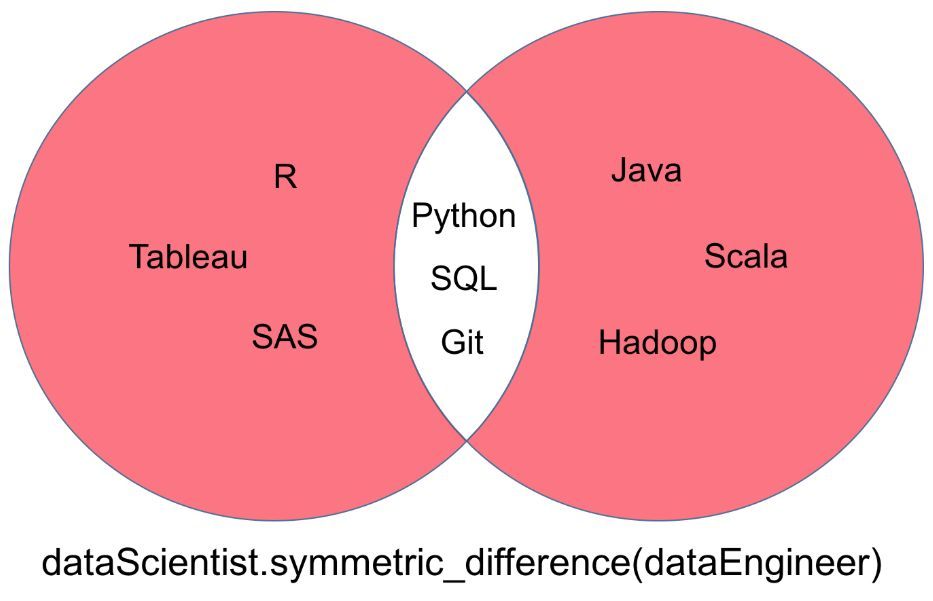
一個(gè)「dataScientist」和「dataEngineer」的對(duì)稱集,表示為「dataScientist △ dataEngineer」�,它是所有屬于兩個(gè)集合但不屬于二者共有部分的集合�����。
# Symmetric Difference Operation
dataScientist.symmetric_difference(dataEngineer)
# Equivalent Result
dataScientist ^ dataEngineer

對(duì)稱集運(yùn)算返回的結(jié)果可以被可視化為下面韋恩圖中的紅色部分�����。
集合推導(dǎo)式
你之前可能已經(jīng)學(xué)習(xí)過(guò)列表推導(dǎo)式(list
comprehensions)�����、字典推導(dǎo)式(dictionary comprehensions)和生成器推導(dǎo)式���。這里還有一個(gè)集合推導(dǎo)式(Set
Comprehension)。集合推導(dǎo)式和它們是很類似的����,Python 中的集合推導(dǎo)式可以按照下面的方法構(gòu)造:
{skillforskillin['SQL','SQL','PYTHON','PYTHON']}

上面的輸出為一個(gè)包含 2 個(gè)值的集合,因?yàn)榧现邢嗤脑夭荒芏啻纬霈F(xiàn)�����。使用集合推導(dǎo)式背后的動(dòng)機(jī)是希望能夠用手動(dòng)進(jìn)行數(shù)學(xué)運(yùn)算的方法在代碼中編寫(xiě)和推導(dǎo)式子�。
{skillforskillin['GIT','PYTHON','SQL']ifskill notin{'GIT','PYTHON','JAVA'}}

上面的代碼與你之前學(xué)過(guò)的求差集類似,只是看上去有一點(diǎn)點(diǎn)不同�����。
成員檢測(cè)
成員檢測(cè)能夠檢查某個(gè)特定的元素是否被包含在一個(gè)序列中,例如字符串�����、列表�����、元組或集合���。在
Python 中使用集合的一個(gè)主要的優(yōu)點(diǎn)是�����,它們?cè)?Python
中為成員檢測(cè)做了深度的優(yōu)化。例如�,對(duì)集合做成員檢測(cè)比對(duì)列表做成員檢測(cè)高效地多。如果你是計(jì)算機(jī)科班出身��,我們可以說(shuō)����,這是因?yàn)榧现谐蓡T檢測(cè)的平均時(shí)間復(fù)雜度是
O(1)的而列表中則是 O(n)����。
下面的代碼展示了使用列表做成員檢測(cè)的過(guò)程:
# Initialize a list
possibleList = ['Python','R','SQL','Git','Tableau','SAS','Java','Spark','Scala']
# Membership test
'Python'inpossibleList

集合中也可以做類似的操作�����,只不過(guò)集合更加高效��。
# Initialize a set
possibleSet = {'Python','R','SQL','Git','Tableau','SAS','Java','Spark','Scala'}
# Membership test
'Python'inpossibleSet

由于「possibleSet」是一個(gè)集合����,而且「Python」是集合「possibleSet」中的一個(gè)元素,這可以被表示為「Python'
∈ possibleSet」如果你有一個(gè)不屬于集合的值��,比如「Fortran」����,這可以被表示為「Fortran' ?
possibleSet」。
子集
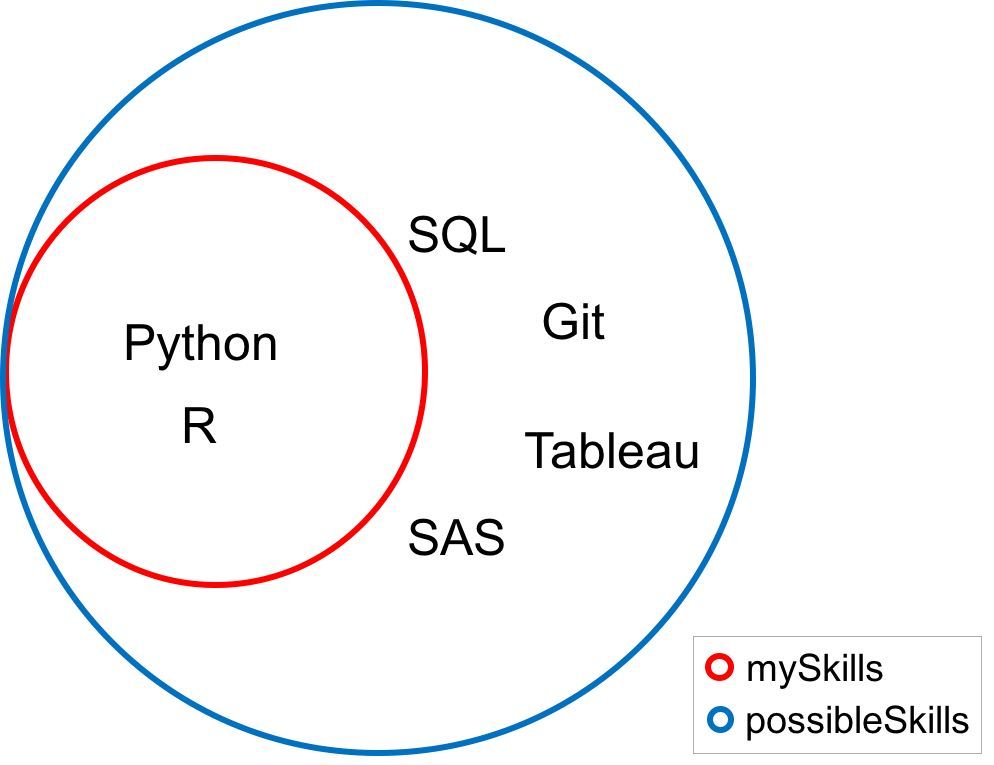
實(shí)際上集合的成員及成員的組合就是一個(gè)子集�,讓我們首先初始化兩個(gè)集合。
possibleSkills = {'Python','R','SQL','Git','Tableau','SAS'}
mySkills = {'Python','R'}
如果集合「mySkills」中的每一個(gè)值都屬于集合「possibleSkills」���,那么「mySkills」被稱為「possibleSkills」的一個(gè)子集�����,數(shù)學(xué)上寫(xiě)作「mySkills
? possibleSkills」�。你可以使用「issubset」方法檢查一個(gè)集合是否是另一個(gè)集合的子集。
mySkills.issubset(possibleSkills)

因?yàn)樵谶@個(gè)例子中��,這個(gè)方法返回的是「True」���。在下面的韋恩圖中�����,請(qǐng)注意「mySkills」中的每一個(gè)值同時(shí)也在集合「possibleSkills」中����。
不可變集
我們常常能看到嵌套的列表或元組���,它們的元素可能是另一個(gè)列表或元組�。
# Nested Lists and Tuples
nestedLists = [['the',12], ['to',11], ['of',9], ['and',7], ['that',6]]
nestedTuples = (('the',12), ('to',11), ('of',9), ('and',7), ('that',6))

嵌套集合的問(wèn)題在于����,集合中通常不能包含集合等可變的值���。在這種情況下�����,你可能希望使用一個(gè)不可變集(frozenset)�。除了值不可以改變,不可變集和可變集是很相似的����。你可以使用「frozenset()」創(chuàng)建一個(gè)不可變集。
# Initialize a frozenset
immutableSet = frozenset()

如果你使用如下所示的不可變集�,就可以創(chuàng)建一個(gè)嵌套集合了。
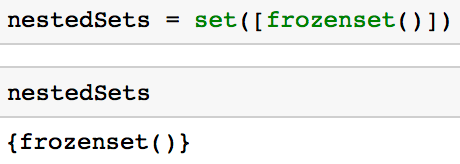
nestedSets = set([frozenset()])
重要的是�����,你需要記住�,不可變集的一個(gè)主要的缺點(diǎn)是:由于它們是不可變的,這意味著你不能向其中添加元素或者刪除其中的元素�����。
結(jié)語(yǔ)
Python
集合是非常實(shí)用的�����,它能夠高效地從列表等數(shù)據(jù)結(jié)構(gòu)中刪除重復(fù)的值,并且執(zhí)行常見(jiàn)的數(shù)學(xué)運(yùn)算�,例如:求并集、交集���。人們經(jīng)常遇到的一個(gè)挑戰(zhàn)是:何時(shí)使用各種數(shù)據(jù)類型���,例如什么時(shí)候使用集合或字典。作者希望本文能展示基本的集合概念�,并有利于我們?cè)诓煌蝿?wù)中使用不同的數(shù)據(jù)類型。
CDA數(shù)據(jù)分析師考試相關(guān)入口一覽(建議收藏):
? 想報(bào)名CDA認(rèn)證考試�,點(diǎn)擊>>>
“CDA報(bào)名”
了解CDA考試詳情;
? 想學(xué)習(xí)CDA考試教材���,點(diǎn)擊>>> “CDA教材” 了解CDA考試詳情�;
? 想加入CDA考試題庫(kù)����,點(diǎn)擊>>> “CDA題庫(kù)” 了解CDA考試詳情;
? 想了解CDA考試含金量��,點(diǎn)擊>>> “CDA含金量” 了解CDA考試詳情��;











 京公網(wǎng)安備 11010802034615號(hào)
經(jīng)營(yíng)許可證編號(hào):京B2-20210330
京公網(wǎng)安備 11010802034615號(hào)
經(jīng)營(yíng)許可證編號(hào):京B2-20210330