從零開始用Python構建神經(jīng)網(wǎng)絡
動機:為了更加深入的理解深度學習���,我們將使用 python 語言從頭搭建一個神經(jīng)網(wǎng)絡����,而不是使用像 Tensorflow 那樣的封裝好的框架��。我認為理解神經(jīng)網(wǎng)絡的內(nèi)部工作原理�,對數(shù)據(jù)科學家來說至關重要�����。
這篇文章的內(nèi)容是我的所學�,希望也能對你有所幫助�����。
神經(jīng)網(wǎng)絡是什么?
介紹神經(jīng)網(wǎng)絡的文章大多數(shù)都會將它和大腦進行類比���。如果你沒有深入研究過大腦與神經(jīng)網(wǎng)絡的類比,那么將神經(jīng)網(wǎng)絡解釋為一種將給定輸入映射為期望輸出的數(shù)學關系會更容易理解��。
神經(jīng)網(wǎng)絡包括以下組成部分
? 一個輸入層�,x
? 任意數(shù)量的隱藏層
? 一個輸出層,?
? 每層之間有一組權值和偏置��,W and b
? 為隱藏層選擇一種激活函數(shù)�,σ。在教程中我們使用 Sigmoid 激活函數(shù)
下圖展示了 2 層神經(jīng)網(wǎng)絡的結構(注意:我們在計算網(wǎng)絡層數(shù)時通常排除輸入層)
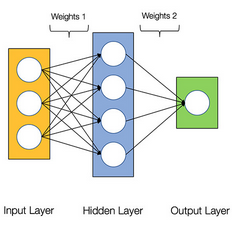
2 層神經(jīng)網(wǎng)絡的結構
用 Python 可以很容易的構建神經(jīng)網(wǎng)絡類

訓練神經(jīng)網(wǎng)絡
這個網(wǎng)絡的輸出 ? 為:
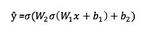
你可能會注意到�,在上面的等式中,輸出 ? 是 W 和 b 函數(shù)����。
因此 W 和 b 的值影響預測的準確率. 所以根據(jù)輸入數(shù)據(jù)對 W 和 b 調(diào)優(yōu)的過程就被成為訓練神經(jīng)網(wǎng)絡。
每步訓練迭代包含以下兩個部分:
? 計算預測結果 ?�����,這一步稱為前向傳播
? 更新 W 和 b,,這一步成為反向傳播
下面的順序圖展示了這個過程:

前向傳播
正如我們在上圖中看到的����,前向傳播只是簡單的計算。對于一個基本的 2 層網(wǎng)絡來說����,它的輸出是這樣的:
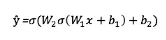
我們在 NeuralNetwork 類中增加一個計算前向傳播的函數(shù)。為了簡單起見我們假設偏置 b 為0:

但是我們還需要一個方法來評估預測結果的好壞(即預測值和真實值的誤差)�����。這就要用到損失函數(shù)���。
損失函數(shù)
常用的損失函數(shù)有很多種,根據(jù)模型的需求來選擇�����。在本教程中�����,我們使用誤差平方和作為損失函數(shù)��。
誤差平方和是求每個預測值和真實值之間的誤差再求和��,這個誤差是他們的差值求平方以便我們觀察誤差的絕對值��。
訓練的目標是找到一組 W 和 b���,使得損失函數(shù)最好小��,也即預測值和真實值之間的距離最小���。
反向傳播
我們已經(jīng)度量出了預測的誤差(損失),現(xiàn)在需要找到一種方法來傳播誤差����,并以此更新權值和偏置。
為了知道如何適當?shù)恼{(diào)整權值和偏置�,我們需要知道損失函數(shù)對權值 W 和偏置 b 的導數(shù)。
回想微積分中的概念��,函數(shù)的導數(shù)就是函數(shù)的斜率���。
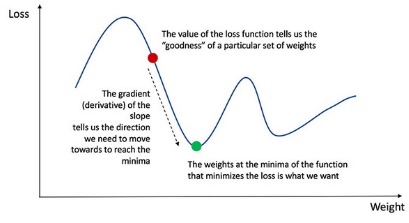
梯度下降法
如果我們已經(jīng)求出了導數(shù)�,我們就可以通過增加或減少導數(shù)值來更新權值 W 和偏置 b(參考上圖)�。這種方式被稱為梯度下降法。
但是我們不能直接計算損失函數(shù)對權值和偏置的導數(shù),因為在損失函數(shù)的等式中并沒有顯式的包含他們��。因此����,我們需要運用鏈式求導發(fā)在來幫助計算導數(shù)。
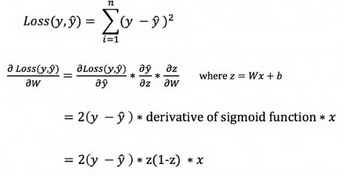
鏈式法則用于計算損失函數(shù)對 W 和 b 的導數(shù)��。注意���,為了簡單起見����。我們只展示了假設網(wǎng)絡只有 1 層的偏導數(shù)�。
這雖然很簡陋,但是我們依然能得到想要的結果—損失函數(shù)對權值 W 的導數(shù)(斜率)����,因此我們可以相應的調(diào)整權值。
現(xiàn)在我們將反向傳播算法的函數(shù)添加到 Python 代碼中

為了更深入的理解微積分原理和反向傳播中的鏈式求導法則�,我強烈推薦 3Blue1Brown 的如下教程:
Youtube:https://youtu.be/tIeHLnjs5U8
整合并完成一個實例
既然我們已經(jīng)有了包括前向傳播和反向傳播的完整 Python 代碼,那么就將其應用到一個例子上看看它是如何工作的吧���。
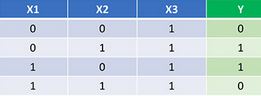
神經(jīng)網(wǎng)絡可以通過學習得到函數(shù)的權重�。而我們僅靠觀察是不太可能得到函數(shù)的權重的��。
讓我們訓練神經(jīng)網(wǎng)絡進行 1500 次迭代���,看看會發(fā)生什么����。 注意觀察下面每次迭代的損失函數(shù)��,我們可以清楚地看到損失函數(shù)單調(diào)遞減到最小值�。這與我們之前介紹的梯度下降法一致。
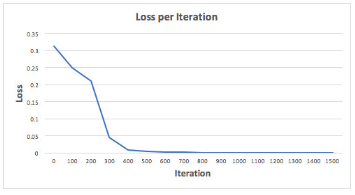
讓我們看看經(jīng)過 1500 次迭代后的神經(jīng)網(wǎng)絡的最終預測結果:
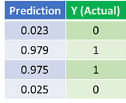
經(jīng)過 1500 次迭代訓練后的預測結果
我們成功了!我們應用前向和方向傳播算法成功的訓練了神經(jīng)網(wǎng)絡并且預測結果收斂于真實值�����。
注意預測值和真實值之間存在細微的誤差是允許的�。這樣可以防止模型過擬合并且使得神經(jīng)網(wǎng)絡對于未知數(shù)據(jù)有著更強的泛化能力。
下一步是什么?
幸運的是我們的學習之旅還沒有結束��,仍然有很多關于神經(jīng)網(wǎng)絡和深度學習的內(nèi)容需要學習�����。例如:
? 除了 Sigmoid 以外�,還可以用哪些激活函數(shù)
? 在訓練網(wǎng)絡的時候應用學習率
? 在面對圖像分類任務的時候使用卷積神經(jīng)網(wǎng)絡
我很快會寫更多關于這個主題的內(nèi)容�,敬請期待!
最后的想法
我自己也從零開始寫了很多神經(jīng)網(wǎng)絡的代碼
雖然可以使用諸如 Tensorflow 和 Keras 這樣的深度學習框架方便的搭建深層網(wǎng)絡而不需要完全理解其內(nèi)部工作原理����。但是我覺得對于有追求的數(shù)據(jù)科學家來說,理解內(nèi)部原理是非常有益的��。
這種練習對我自己來說已成成為重要的時間投入��,希望也能對你有所幫助
CDA數(shù)據(jù)分析師考試相關入口一覽(建議收藏):
? 想報名CDA認證考試���,點擊>>>
“CDA報名”
了解CDA考試詳情�;
? 想學習CDA考試教材���,點擊>>> “CDA教材” 了解CDA考試詳情���;
? 想加入CDA考試題庫,點擊>>> “CDA題庫” 了解CDA考試詳情��;
? 想了解CDA考試含金量�����,點擊>>> “CDA含金量” 了解CDA考試詳情�;











 京公網(wǎng)安備 11010802034615號
經(jīng)營許可證編號:京B2-20210330
京公網(wǎng)安備 11010802034615號
經(jīng)營許可證編號:京B2-20210330