AI 又贏了! OpenAI 玩Dota 2在5v5比賽中擊敗人類玩家
2017
年���,OpenAI 在 Dota2 TI 決賽現(xiàn)場(chǎng)以 1 對(duì) 1 solo 的方式擊敗了「Dota
2」世界頂級(jí)玩家��。經(jīng)過一年的發(fā)展���,OpenAI 于昨日宣布他們的 AI bot 在 5 v 5
團(tuán)隊(duì)賽中擊敗業(yè)余人類玩家�����,并計(jì)劃之后能夠擊敗頂級(jí)專業(yè)團(tuán)隊(duì)�。機(jī)器之心對(duì)OpenAI的博客內(nèi)容進(jìn)行了編譯介紹���。
我們團(tuán)隊(duì)構(gòu)建的模型����,OpenAI
Five,已經(jīng)擊敗業(yè)余 Dota2 團(tuán)隊(duì)了����。雖然如今是在有限制的情況下,但我們計(jì)劃到 8 月份在有限英雄池下?lián)魯?TI
賽中的一支頂級(jí)專業(yè)隊(duì)伍���。我們可能不會(huì)成功���,因?yàn)?Dota2 是當(dāng)前最流行也最復(fù)雜的電子競(jìng)技游戲之一,一批有激情與創(chuàng)造力的玩家經(jīng)年訓(xùn)練�,想要瓜分
4000 萬(wàn)美金的獎(jiǎng)金池。
通過自我對(duì)抗學(xué)習(xí)���,OpenAI
Five 每天相當(dāng)于玩 180 年的游戲�。訓(xùn)練上���,它使用 256 塊 GPU���、12 萬(wàn) 8000 個(gè) CPU
核心使用近端策略優(yōu)化(Proximal Policy Optimization)方法進(jìn)行訓(xùn)練,這是在我們?nèi)ツ杲⒌?solo Dota2
系統(tǒng)上的擴(kuò)增�。當(dāng)我們?yōu)槊總€(gè)英雄使用單獨(dú)的一個(gè)
LSTM��,模型就可以在沒有人類數(shù)據(jù)的情況下學(xué)到可識(shí)別的策略����。這表明強(qiáng)化學(xué)習(xí)即使沒有根本性的進(jìn)步�,也能夠產(chǎn)生大規(guī)模但也可接受的長(zhǎng)期規(guī)劃。這出乎了我們剛開始時(shí)的預(yù)料�����。

問題
人工智能的一個(gè)里程碑就是在星際爭(zhēng)霸或者
Dota
這類復(fù)雜的電子游戲中超越人類的水平�。相比于上一個(gè)里程碑,即國(guó)際象棋與圍棋����,復(fù)雜電子游戲開始反映真實(shí)世界的混亂與連續(xù)的本質(zhì)��。因此我們希望�����,能夠解決復(fù)雜電子游戲的系統(tǒng)可以成為通用的�����、在游戲之外有廣闊應(yīng)用場(chǎng)景的系統(tǒng)。
Dota2 是一個(gè)實(shí)時(shí)的 5 v 5 策略游戲���,每個(gè)玩家控制一個(gè)英雄���。而玩 Dota 的 AI 需要掌握以下技能:
-
長(zhǎng)線策略。Dota
游戲平均每秒 30 幀����,一場(chǎng)時(shí)常 45 分鐘,大概 8 萬(wàn)
tick��。大部分操作(例如操縱英雄移動(dòng))都有單獨(dú)的小影響���,但一些個(gè)體行為可能會(huì)影響到游戲戰(zhàn)略��,例如 TP
回家����。此外�����,還有一些策略可能會(huì)終結(jié)整場(chǎng)游戲���。OpenAI Five 每 4 幀觀察一次�����,產(chǎn)生了 2 萬(wàn)個(gè)決策��。相比之下���,國(guó)際象棋一般在 40
步之前就結(jié)束了�����,圍棋大概 150 步�,但這些游戲每一步都很有策略性����。
-
局部可觀測(cè)狀態(tài)。己方單位和建筑的視野都有限��。地圖的其他部分是沒有視野的�����,可能藏有敵人和敵方策略�����。高玩通常需要基于不完整數(shù)據(jù)做推理��,以及建模敵方意圖�����。而國(guó)際象棋和圍棋都是完全信息博弈���。
-
高維���、持續(xù)的行為空間。在
Dota 中�����,每個(gè)英雄能采取數(shù)十種行為��,而且許多行為要么面向敵方單位����,要么點(diǎn)地移動(dòng)位置。我們把這個(gè)空間離散到每個(gè)英雄 17
萬(wàn)種可能的操作(不是每 tick 都有效,例如在技能冷卻時(shí)放技能就是無(wú)效操作)���;不計(jì)算連續(xù)部分�,每 tick 平均 1000
個(gè)可能有效行為��。國(guó)際象棋的行為數(shù)量大概是 35����,圍棋 250。
-
高維��、連續(xù)的觀察空間��。Dota
是在一張包含 10 個(gè)英雄�、20 幾個(gè)塔、數(shù)十個(gè) NPC 單位的地圖上操作的游戲��,此外還有神符���、樹�����、眼衛(wèi)等�����。通過 Valve(Dota 2
的運(yùn)營(yíng)公司)的 Bot API�����,我們的模型把 Dota 游戲視為 2 萬(wàn)個(gè)狀態(tài)���,也就代表人類在游戲中可獲取到的所有信息。國(guó)際象棋代表大概 70
個(gè)枚舉值(8x8 的棋盤�,6 類棋子和較小的歷史信息)。圍棋大概有 400 個(gè)枚舉值(19x19 的棋盤��,黑白 2 子��,加上 Ko)����。
Dota 規(guī)則也非常復(fù)雜,這類游戲開發(fā)了十幾年�����,成百上千的代碼行實(shí)現(xiàn)游戲邏輯�����。而且游戲每?jī)芍芨乱淮危h(huán)境語(yǔ)義一直在變�。
方法
我們的系統(tǒng)使用一個(gè)高度擴(kuò)展版本的近端策略優(yōu)化(Proximal Policy Optimization)算法進(jìn)行學(xué)習(xí)。OpenAI Five 和之前的 1v1 機(jī)器人都是通過自我對(duì)抗進(jìn)行學(xué)習(xí)的����。他們從隨機(jī)參數(shù)開始,并不從人類玩家的方法中進(jìn)行搜索或者自舉���。
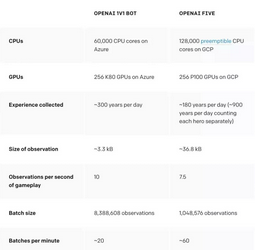
強(qiáng)化學(xué)習(xí)研究人員(包括我們自己)過去普遍認(rèn)為�����,進(jìn)行長(zhǎng)時(shí)間范圍的學(xué)習(xí)需要根本性的算法突破���,例如層級(jí)強(qiáng)化學(xué)習(xí)(hierarchical
reinforcement
learning)。而我們的結(jié)果顯示�,我們并沒有充分信任現(xiàn)有的模型——至少當(dāng)他們以足夠的規(guī)模和合理的探索方式運(yùn)行的時(shí)候。
我們的智能體被訓(xùn)練以最大化未來(lái)獎(jiǎng)勵(lì)的指數(shù)衰減和����,其中指數(shù)衰減因子被稱為
γ。在 OpenAIFive 最新一輪的訓(xùn)練中���,我們將 γ 從 0.998(以 46 秒為半衰期)調(diào)整到了 0.997(以 5
分鐘為半衰期)�����。相比之下���,OpenAI 的近端策略優(yōu)化(PPO)論文中最長(zhǎng)的時(shí)間跨度為半衰期 0.5 秒,DeepMind 的 Rainbow
論文中最長(zhǎng)的時(shí)間跨度為半衰期 4.4 秒�,Google Brain 的 Observe and Look Further 論文中則使用了 46
秒的半衰期。
雖然當(dāng)前
OpenAI Five 的補(bǔ)兵能力略差(看我們的測(cè)試賽���,專業(yè) Dota 解說(shuō)員 Blitz
估計(jì)它的補(bǔ)兵能力只有職業(yè)玩家的中值水平)�,但它在選擇優(yōu)先攻擊目標(biāo)上能達(dá)到專業(yè)水平�����。獲取長(zhǎng)期獎(jiǎng)勵(lì)(例如插眼控圖)通常需要犧牲短期獎(jiǎng)勵(lì)(例如發(fā)育后的金錢)��,因?yàn)閳F(tuán)推時(shí)要也要耗費(fèi)時(shí)間���。這一觀察加強(qiáng)了我們的信念:系統(tǒng)會(huì)隨長(zhǎng)時(shí)間而有優(yōu)化��。
模型架構(gòu)
每個(gè)
Open AI Five 網(wǎng)絡(luò)包含一個(gè)單層����、1024 個(gè)單元的 LSTM 網(wǎng)絡(luò),它能觀察當(dāng)前的游戲狀態(tài)(從 Valve 的 Bot API
中抽?���。┎⑼ㄟ^一些可能的行動(dòng) Head 發(fā)出下一步采取的行動(dòng)。每一個(gè) Head 都包含語(yǔ)義信息���,例如延遲該行動(dòng)的時(shí)間值��、選擇哪一個(gè)行動(dòng)和其 X 與
Y 的坐標(biāo)軸��。
OpenAI
Five 使用了觀察空間和行動(dòng)空間的交互性演示���。它將世界表征為一個(gè)由 2 萬(wàn)個(gè)數(shù)值組成的列表,并通過發(fā)出一個(gè)包含 8
個(gè)枚舉值的列表而采取行動(dòng)�����。我們可以在 OpenAI 網(wǎng)站上選擇不同的行動(dòng)和目標(biāo)以理解 OpenAI Five
是如何編碼每一個(gè)行動(dòng)����,以及如何觀察世界的。下圖展示了人們可能會(huì)觀察到的場(chǎng)景:

Necrophos
OpenAI
Five 可以對(duì)其丟失的狀態(tài)片段作出反應(yīng)����,這些狀態(tài)片段可能與它所看到的相關(guān)�����。例如�,直到最近 OpenAI Five
的觀察還沒有包含彈片落下的區(qū)域���,而人類可以在屏幕上輕松觀察到這些落彈區(qū)域。然而�,我們觀察到 OpenAI Five
可以學(xué)習(xí)走出活躍的落彈區(qū)域,因?yàn)樵谶@樣的區(qū)域中智能體會(huì)發(fā)現(xiàn)它們的生命值在下降���。
探索
盡管構(gòu)建的學(xué)習(xí)算法能處理較長(zhǎng)的視野����,但我們?nèi)匀恍枰剿鳝h(huán)境����。即使我們已經(jīng)限制了復(fù)雜度,但游戲仍然有數(shù)百種物品���、幾十種建筑���、法術(shù)���、單位類型以及需要長(zhǎng)時(shí)間慢慢學(xué)習(xí)的游戲機(jī)制,這些變量將組合成極其巨量的情況��。因此��,有效地探索這一巨大的組合空間是非常困難的�����。
OpenAI
Five 通過自我對(duì)抗(self-play)從隨機(jī)權(quán)重開始學(xué)習(xí)�����,這為探索環(huán)境提供了一個(gè)自然的
curriculum�。為了避免「策略崩壞」,智能體在 80% 的游戲中通過自我對(duì)抗進(jìn)行訓(xùn)練�����,而在 20%
的游戲中與過去的智能體進(jìn)行對(duì)戰(zhàn)��。在第一場(chǎng)游戲中����,英雄漫無(wú)目的地在地圖上探索��,而在幾個(gè)小時(shí)的訓(xùn)練后��,出現(xiàn)了規(guī)劃�����、發(fā)育或中期戰(zhàn)斗等概念�。幾天后����,智能體能一致地采用基本的人類策略:試圖從對(duì)手偷財(cái)富�、推塔發(fā)育、在地圖旋轉(zhuǎn)控制英雄以獲得線路優(yōu)勢(shì)�����。通過進(jìn)一步的訓(xùn)練��,它們變得精通
5 個(gè)英雄一起推塔這樣的高級(jí)策略了�����。
在
2017
年,我們第一個(gè)智能體擊敗了機(jī)器人�����,但仍然不能戰(zhàn)勝人類����。為了強(qiáng)制在策略空間中進(jìn)行探索,我們有且僅在訓(xùn)練期間對(duì)這些單位的屬性(生命�、速度和初始等級(jí)等)進(jìn)行了隨機(jī)化,然后它開始與人類對(duì)戰(zhàn)���。隨后��,當(dāng)一名測(cè)試玩家不停地?fù)魯∥覀兊?
1V1
機(jī)器人時(shí)��,我們?cè)黾恿擞?xùn)練的隨機(jī)性�,然后測(cè)試玩家就開始輸?shù)舯荣惲?�。此外�����,我們的機(jī)器人團(tuán)隊(duì)同時(shí)將類似的隨機(jī)技術(shù)應(yīng)用到物理機(jī)器人中,以便從模仿學(xué)習(xí)遷移知識(shí)到現(xiàn)實(shí)世界中�。
OpenAI Five 使用我們?yōu)?1V1 機(jī)器人編寫的隨機(jī)化,它還使用一個(gè)新的「lane assignment」�����。在每次訓(xùn)練游戲開始時(shí)�,我們隨機(jī)「分配」每一個(gè)英雄到線路的一些子集,并在智能體發(fā)生偏離時(shí)對(duì)其進(jìn)行懲罰����,直到游戲中的隨機(jī)選擇時(shí)間才結(jié)束懲罰。
這樣的探索得到了很好的獎(jiǎng)勵(lì)�。我們的獎(jiǎng)勵(lì)主要由衡量人類如何在游戲中做決策的指標(biāo)組成:凈價(jià)值、殺敵數(shù)���、死亡數(shù)���、助攻數(shù)���、最后人頭等��。我們通過減去每一個(gè)團(tuán)隊(duì)的平均獎(jiǎng)勵(lì)以后處理每一個(gè)智能體的獎(jiǎng)勵(lì)����,因此這能防止智能體找到正項(xiàng)和(positive-sum)的情況��。
合作
OpenAI
Five 沒有在各個(gè)英雄的神經(jīng)網(wǎng)絡(luò)之間搭建顯式的溝通渠道��。團(tuán)隊(duì)合作由一個(gè)我們稱之為「團(tuán)隊(duì)精神」的超參數(shù)控制。團(tuán)隊(duì)精神的取值范圍為從 0 到
1�,代表了 OpenAI Five 的每個(gè)英雄在多大程度上關(guān)注自己的個(gè)人獎(jiǎng)勵(lì)函數(shù)以及在多大程度上關(guān)注團(tuán)隊(duì)平均獎(jiǎng)勵(lì)函數(shù)。在訓(xùn)練中��,我們將其值從 0
逐漸調(diào)整到 1�����。
Rapid

我們的系統(tǒng)是用通用的強(qiáng)化學(xué)習(xí)訓(xùn)練系統(tǒng) Rapid 來(lái)實(shí)現(xiàn)的��。Rapid 可以被應(yīng)用到任何一個(gè) Gym 環(huán)境����。在 OpenAI,我們也用 Rapid 來(lái)解決其他問題���,包括競(jìng)爭(zhēng)性自我對(duì)抗訓(xùn)練(Competitive Self-Play)�。
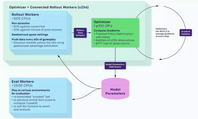
訓(xùn)練系統(tǒng)示意圖
我們已經(jīng)在 IBM Kubernetes����,微軟 Azure�,谷歌 GCP 后端上實(shí)現(xiàn)了 Rapid����。
游戲
到目前為止,我們與這些隊(duì)伍進(jìn)行了對(duì)戰(zhàn):
-
最強(qiáng)的 OpenAI 職員團(tuán)隊(duì): 匹配分 2500
-
觀看 OpenAI 職員比賽的觀眾玩家 (包括 Blitz 等):匹配分 4000-6000��,他們此前從沒有組隊(duì)參賽過����。
-
Valve 公司團(tuán)隊(duì): 匹配分 2500-4000
-
業(yè)余團(tuán)隊(duì): 天梯 4200, 作為一支隊(duì)伍來(lái)進(jìn)行訓(xùn)練。
-
半職業(yè)團(tuán)隊(duì): 天梯 5500, 作為一支隊(duì)伍來(lái)進(jìn)行訓(xùn)練�。
在與前面三支隊(duì)伍的比賽中,OpenAI 取得了勝利���,輸給了后面的兩只隊(duì)伍(只贏了開場(chǎng)前三局)�。
我們觀察到 OpenAI Five 具有以下幾個(gè)特點(diǎn):
經(jīng)常來(lái)犧牲自己的優(yōu)勢(shì)路(夜魘軍團(tuán)的上路����,天輝軍團(tuán)的下路),以壓制敵人的優(yōu)勢(shì)路����,迫使戰(zhàn)斗轉(zhuǎn)移到對(duì)手更難防御的一邊。該策略在過去幾年的專業(yè)領(lǐng)域出現(xiàn)過�����,現(xiàn)在已經(jīng)成為了流行戰(zhàn)術(shù)��。Blitz
說(shuō)他在打 DOTA 8 年后才學(xué)到了這個(gè)戰(zhàn)術(shù)�,當(dāng)時(shí)是 Liquid(一支職業(yè)隊(duì)伍)告訴了他。
比賽初期到中期的轉(zhuǎn)換比對(duì)手更快����。它是這樣做到的:1)在人類玩家走位出問題時(shí),進(jìn)行多次成功 gank�����,2)在對(duì)方組織起反抗前����,去組隊(duì)推塔。
在一些領(lǐng)域機(jī)器有時(shí)也會(huì)偏離主流打法��,例如在前期將錢和經(jīng)驗(yàn)讓給輔助英雄(這些英雄一般不優(yōu)先獲取資源)�。OpenAI Five 的優(yōu)先級(jí)使它獲得的傷害更快達(dá)到頂峰,從而建立起更大的優(yōu)勢(shì)�����,贏得團(tuán)戰(zhàn)以及利用對(duì)方的錯(cuò)誤來(lái)確保快速取勝�。

和人類的差異
OpenAI Five 獲得的信息和人類是一樣的,但前者可以實(shí)時(shí)看到位置�����、生命值和裝備清單等�����,而這些信息都需要人類選手去手動(dòng)查看��。我們的方法從根本上就沒有依賴于(實(shí)時(shí))觀察狀態(tài)��,但從游戲中渲染像素就需要成千上萬(wàn)塊 GPU���。
OpenAI
Five 平均每分鐘可進(jìn)行 150-170 次操作(APM=150-170��,因?yàn)槊克膸^察一次���,所以理論峰值為
450)。熟練的玩家有可能掌握完美捕捉畫面的時(shí)機(jī)�,但這對(duì)機(jī)器來(lái)說(shuō)輕而易舉��。OpenAI Five 的平均反應(yīng)時(shí)間為 80 毫秒,比人類更快��。
這些差異在
1V1 中影響最大(當(dāng)時(shí)我們機(jī)器人的反應(yīng)時(shí)間為 67 毫秒)�,但競(jìng)技是相對(duì)公平的,因?yàn)槲覀円呀?jīng)看到人類在學(xué)習(xí)和適應(yīng)機(jī)器人的打法����。在去年 TI
之后,很多專業(yè)選手使用我們的 1V1 機(jī)器人進(jìn)行了為期數(shù)月的訓(xùn)練��。William *"Blitz"* Lee(前 DOTA2
專業(yè)選手和教練)表示�����,1V1 機(jī)器人已經(jīng)改變了我們對(duì)單挑的傳統(tǒng)看法(機(jī)器人采取了快節(jié)奏的打法�,現(xiàn)在每個(gè)人都已經(jīng)試著去跟著這個(gè)節(jié)奏)。
令人驚訝的發(fā)現(xiàn)
二元獎(jiǎng)勵(lì)可以給予良好的表現(xiàn)���。我們的
1v1
模型具有形狀獎(jiǎng)勵(lì)�,包括上次命中獎(jiǎng)勵(lì)�,殺戮等。我們進(jìn)行了一個(gè)實(shí)驗(yàn)���,只獎(jiǎng)勵(lì)代理的獲勝或失敗����,并且讓它在中間訓(xùn)練了一個(gè)數(shù)量級(jí)較慢并且稍微平穩(wěn)的階段,與我們平?���?吹降钠交?a href='/map/xuexiquxian/' style='color:#000;font-size:inherit;'>學(xué)習(xí)曲線形成對(duì)比。該實(shí)驗(yàn)在
4500 個(gè)核心和 16 個(gè) k80 GPU 上進(jìn)行訓(xùn)練�����,訓(xùn)練至半專業(yè)級(jí)(70 TrueSkill�����,而非我們最好的 1v1 機(jī)器人的 90
TrueSkill)�。
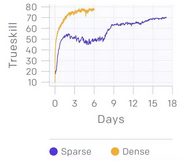
我們可以從頭開始學(xué)習(xí)卡兵。對(duì)
1v1 來(lái)說(shuō)�,我們使用傳統(tǒng)的強(qiáng)化學(xué)習(xí)和一個(gè)卡兵獎(jiǎng)勵(lì)(a creep block
award)來(lái)學(xué)習(xí)卡兵。我們的一個(gè)同事在去度假前(去和未婚妻求婚?��。┝粝铝?2v2
模型���,打算看看需要多久的訓(xùn)練能才提高表現(xiàn)��。令他驚訝的是����,這個(gè)模型在沒有任何指導(dǎo)或獎(jiǎng)勵(lì)的情況下學(xué)會(huì)了卡兵�。
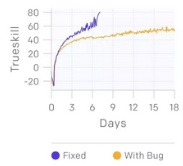
我們?nèi)栽谛迯?fù)系統(tǒng)漏洞��。下圖顯示了擊敗業(yè)余玩家的訓(xùn)練代碼��,相比之下��,我們只是修復(fù)了一些漏洞��,比如訓(xùn)練期間的罕見崩潰�����,或者導(dǎo)致達(dá)到 25 級(jí)的巨大負(fù)面獎(jiǎng)勵(lì)的錯(cuò)誤���。事實(shí)證明我們可以在隱藏嚴(yán)重漏洞的情況下�,依然擊敗優(yōu)秀的人類玩家���!
Open AI Dota 的一個(gè)子團(tuán)隊(duì)手托去年在 Dota 2 國(guó)際邀請(qǐng)賽 1v1 上擊敗世界頂級(jí)專業(yè)玩家的筆記本電腦�����。
下一步計(jì)劃
Open AI 的團(tuán)隊(duì)專注于達(dá)成八月份制定的目標(biāo)��。我們不知道它是否可以實(shí)現(xiàn)�,但是我們相信通過自身的努力(和運(yùn)氣),機(jī)會(huì)還是很大的���。
CDA數(shù)據(jù)分析師考試相關(guān)入口一覽(建議收藏):
? 想報(bào)名CDA認(rèn)證考試��,點(diǎn)擊>>>
“CDA報(bào)名”
了解CDA考試詳情����;
? 想學(xué)習(xí)CDA考試教材����,點(diǎn)擊>>> “CDA教材” 了解CDA考試詳情;
? 想加入CDA考試題庫(kù)���,點(diǎn)擊>>> “CDA題庫(kù)” 了解CDA考試詳情��;
? 想了解CDA考試含金量��,點(diǎn)擊>>> “CDA含金量” 了解CDA考試詳情���;











 京公網(wǎng)安備 11010802034615號(hào)
經(jīng)營(yíng)許可證編號(hào):京B2-20210330
京公網(wǎng)安備 11010802034615號(hào)
經(jīng)營(yíng)許可證編號(hào):京B2-20210330