盤點(diǎn)丨2018 年熱門 Python 庫(kù)丨TOP20
在解決數(shù)據(jù)科學(xué)任務(wù)和挑戰(zhàn)方面,Python繼續(xù)處于領(lǐng)先地位����。去年,我對(duì)當(dāng)時(shí)熱門的Python庫(kù)進(jìn)行了總結(jié)����。今年,我在當(dāng)中加入新的庫(kù)��,重新對(duì)2018年熱門Python庫(kù)進(jìn)行全面盤點(diǎn)��。
其實(shí)入選的庫(kù)遠(yuǎn)不止20個(gè)���,但由于一些庫(kù)針對(duì)相同問題是可以相互替代的�����,因此沒有納入其中�。
核心庫(kù)和統(tǒng)計(jì)
1. NumPy(提交:17911,貢獻(xiàn)者:641)
首先介紹科學(xué)應(yīng)用方面的庫(kù)����,其中NumPy是不可忽視的選擇。NumPy用于處理大型多維數(shù)組和矩陣�����,并通過大量的高級(jí)數(shù)學(xué)函數(shù)和實(shí)現(xiàn)方法進(jìn)行各種操作�����。
在過去一年里�,NumPy進(jìn)行了大量改進(jìn)。除了bug修復(fù)和兼容性問題之外����,還涉及到樣式可能性,即NumPy對(duì)象的格式化打印����。
2. SciPy(提交:19150��,貢獻(xiàn)者:608)
科學(xué)計(jì)算方面的另一個(gè)核心庫(kù)是SciPy�����。SciPy基于NumPy�����,因此擴(kuò)展了NumPy的功能�����。SciPy的主要數(shù)據(jù)結(jié)構(gòu)是由Numpy實(shí)現(xiàn)的多維數(shù)組。當(dāng)中包括許多解決線性代數(shù)�����、概率論�、積分等任務(wù)的工具。
SciPy的主要改進(jìn)包括�����,持續(xù)集成到不同操作系統(tǒng),以及添加的新功能和新方法�。此外,還封裝了許多新的BLAS和LAPACK函數(shù)�����。
3. Pandas(提交:17144���,貢獻(xiàn)者:1165)
Pandas是一個(gè)Python庫(kù)���,提供高級(jí)數(shù)據(jù)結(jié)構(gòu)和各種分析工具。主要特點(diǎn)是能夠?qū)⑾喈?dāng)復(fù)雜的數(shù)據(jù)操作轉(zhuǎn)換為一兩條命令�。Pandas包含許多用于分組、過濾和組合數(shù)據(jù)的內(nèi)置方法��,以及時(shí)間序列功能����。
Pandas庫(kù)已推出多個(gè)新版本,其中包括數(shù)百個(gè)新功能�����、增強(qiáng)功能、bug修復(fù)和API改進(jìn)�。這些改進(jìn)包括分類和排序數(shù)據(jù)方面,更適合應(yīng)用方法的輸出�,以及執(zhí)行自定義操作。
4. StatsModels(提交:10067��,貢獻(xiàn)者:153)
Statsmodels是一個(gè)Python模塊���,用于統(tǒng)計(jì)模型估計(jì)����、執(zhí)行統(tǒng)計(jì)測(cè)試等統(tǒng)計(jì)數(shù)據(jù)分析�����。在它的幫助下����,你可以使用機(jī)器學(xué)習(xí)方法進(jìn)行各種繪圖嘗試�。
Statsmodels在不斷改進(jìn)。今年加入了時(shí)間序列方面的改進(jìn)和新的計(jì)數(shù)模型�����,即廣義泊松、零膨脹模型和負(fù)二項(xiàng)��。還包括新的多變量方法 ——因子分析���、多元方差分析和方差分析中的重復(fù)測(cè)量����。
可視化
5. Matplotlib(提交:25747�����,貢獻(xiàn)者:725)
Matplotlib是用于創(chuàng)建二維圖表和圖形的低級(jí)庫(kù)�。使用Matplotlib,你可以構(gòu)建直方圖�����、散點(diǎn)圖���、非笛卡爾坐標(biāo)圖等圖表�����。此外����,許多熱門的繪圖庫(kù)都能與Matplotlib結(jié)合使用。
Matplotlib在顏色��、尺寸�、字體、圖例等方面都有一定改進(jìn)��。外觀方面包括坐標(biāo)軸圖例的自動(dòng)對(duì)齊�;色彩方面也做出改進(jìn),對(duì)色盲更加友好����。
6. Seaborn(提交:2044,貢獻(xiàn)者:83)
Seaborn是基于matplotlib庫(kù)更高級(jí)別的API�����。它包含更適合處理圖表的默認(rèn)設(shè)置���。此外,還包括時(shí)間序列等豐富的可視化圖庫(kù)����。
Seaborn的更新包括bug修復(fù)。同時(shí)����,還包括FacetGrid與PairGrid的兼容性,增強(qiáng)了matplotlib后端交互����,并在可視化中添加了參數(shù)和選項(xiàng)。
7. Plotly(提交:2906����,貢獻(xiàn)者:48)
Plotly能夠讓你輕松構(gòu)建復(fù)雜的圖形。Plotly適用于交互式Web應(yīng)用程序����。可視化方面包括等高線圖�����、三元圖和三維圖��。
Plotly不斷增加新的圖像和功能���,對(duì)動(dòng)畫等方面也提供了支持���。
8. Bokeh(提交:16983�,貢獻(xiàn)者:294)
Bokeh庫(kù)使用JavaScript小部件�����,在瀏覽器中創(chuàng)建交互式和可縮放的可視化�����。Bokeh提供了多種圖形集合�、樣式,并通過鏈接圖����、添加小部件和定義回調(diào)等形式增強(qiáng)互動(dòng)性。
Bokeh在交互式功能的進(jìn)行了改進(jìn)�,比如旋轉(zhuǎn)分類標(biāo)簽、小型縮放工具和自定義工具提示字段的增強(qiáng)����。
9. Pydot(提交:169,貢獻(xiàn)者:12)
Pydot用于生成復(fù)雜的定向圖和非定向圖���。它是用Python編寫的Graphviz接口���。使用Pydot能夠顯示圖形結(jié)構(gòu),這經(jīng)常用于構(gòu)建神經(jīng)網(wǎng)絡(luò)和基于決策樹的算法��。
機(jī)器學(xué)習(xí)
10. Scikit-learn(提交:22753����,貢獻(xiàn)者:1084)
Scikit-learn是基于NumPy和SciPy的Python模塊,并且是處理數(shù)據(jù)方面的不錯(cuò)選擇�。Scikit-learn為許多機(jī)器學(xué)習(xí)和數(shù)據(jù)挖掘任務(wù)提供算法,比如聚類�、回歸、分類���、降維和模型選擇�。
Scikit-learn已做出了許多改進(jìn)��。改進(jìn)包括交叉驗(yàn)證�、使用多個(gè)指標(biāo),近鄰取樣和邏輯回歸等訓(xùn)練方法也有小的改進(jìn)��。主要更新還包括完善常用術(shù)語和API元素的術(shù)語表��,這能幫助用戶熟悉Scikit-learn中的術(shù)語和規(guī)則�。
11. XGBoost / LightGBM / CatBoost(提交:3277/1083/1509���,貢獻(xiàn)者:280/79/61)
梯度提升(gradient
boosting)是最流行的機(jī)器學(xué)習(xí)算法之一,這在決策樹模型中是至關(guān)重要的���。因此我們需要重視XGBoost�、LightGBM和CatBoost�����。這幾個(gè)庫(kù)都用相同的方式解決常見問題�。這些庫(kù)能夠更優(yōu)化、擴(kuò)展且快速地實(shí)現(xiàn)梯度提升����,從而它們?cè)跀?shù)據(jù)科學(xué)家和Kaggle競(jìng)爭(zhēng)中備受追捧,其中許多人在這些算法的幫助下贏得了比賽�����。
12. Eli5(提交:922����,貢獻(xiàn)者:6)
通常機(jī)器學(xué)習(xí)模型預(yù)測(cè)的結(jié)果并不特別清晰,這時(shí)就需要用到eli5了�����。它可以用于可視化和調(diào)試機(jī)器學(xué)習(xí)模型,并逐步跟蹤算法運(yùn)行情況����。同時(shí)eli5能為scikit-learn�����,XGBoost���,LightGBM����,lightning和sklearn-crfsuite庫(kù)提供支持�。
深度學(xué)習(xí)
13. TensorFlow(提交:33339,貢獻(xiàn)者:1469)
TensorFlow是用于深度學(xué)習(xí)和機(jī)器學(xué)習(xí)的熱門框架����,由谷歌大腦開發(fā)。TensorFlow能夠用于多個(gè)數(shù)據(jù)集的人工神經(jīng)網(wǎng)絡(luò)���。TensorFlow的主要應(yīng)用包括對(duì)象識(shí)別��、語音識(shí)別等等�。
新版本中加入了新的功能。最新的改進(jìn)包括修復(fù)安全漏洞�����,以及改進(jìn)TensorFlow和GPU集成����,比如能在一臺(tái)機(jī)器上的多個(gè)GPU上運(yùn)行評(píng)估器模型。
14. PyTorch(提交:11306��,貢獻(xiàn)者:635)
PyTorch是一個(gè)大型框架��,能通過GPU加速執(zhí)行tensor計(jì)算���,創(chuàng)建動(dòng)態(tài)計(jì)算圖并自動(dòng)計(jì)算梯度����。此外���,PyTorch為解決神經(jīng)網(wǎng)絡(luò)相關(guān)的應(yīng)用提供了豐富的API����。
PyTorch基于Torch,它是用C語言實(shí)現(xiàn)的開源的深度學(xué)習(xí)庫(kù)���。Python API于2017年推出����,從此之后該框架越來越受歡迎����,并吸引了大量數(shù)據(jù)科學(xué)家����。
15. Keras(提交:4539,貢獻(xiàn)者:671)
Keras是用于神經(jīng)網(wǎng)絡(luò)的高級(jí)庫(kù)�,可運(yùn)行與TensorFlow和Theano。現(xiàn)在由于推出新版本���,還可以使用CNTK和MxNet作為后端�����。它簡(jiǎn)化了許多任務(wù)��,并大大減少了代碼數(shù)量����。但缺點(diǎn)是不適合處理復(fù)雜任務(wù)。
Keras在性能���、可用性�、文檔即API方面都有改進(jìn)����。新功能包括Conv3DTranspose層、新的MobileNet應(yīng)用等����。
分布式深度學(xué)習(xí)
16. Dist-keras / elephas / spark-deep-learning(提交:1125/170/67,貢獻(xiàn)者:5/13/11)
由于越來越多的用例需要大量的精力和時(shí)間����,深度學(xué)習(xí)問題變得更為重要。但是��,使用Apache Spark之類的分布式計(jì)算系統(tǒng)能夠更容易處理大量數(shù)據(jù)����,這又?jǐn)U展了深度學(xué)習(xí)的可能性��。
因此dist-keras���、elephas、和spark-deep-learning變得更為普及��,由于它們有能用于解決相同任務(wù)��,因此很難從中取舍��。這些包能夠讓你在Apache
Spark的幫助下��,直接通過Keras庫(kù)訓(xùn)練神經(jīng)網(wǎng)絡(luò)�����。Spark-deep-learning還提供了使用Python神經(jīng)網(wǎng)絡(luò)創(chuàng)建管道的工具�����。
自然語言處理
17. NLTK(提交:13041����,貢獻(xiàn)者:236)
NLTK是一組庫(kù)��,是進(jìn)行自然語言處理的平臺(tái)。在NLTK的幫助下�,你可以通過多種方式處理和分析文本,對(duì)其進(jìn)行標(biāo)記和提取信息��。NLTK還可用于原型設(shè)計(jì)和構(gòu)建研究系統(tǒng)�。
NLTK的改進(jìn)包括API和兼容性的小改動(dòng),以及CoreNLP的新接口����。
18. SpaCy(提交:8623,貢獻(xiàn)者:215)
SpaCy是自然語言處理庫(kù)�����,具有出色的示例�����、API文檔和演示應(yīng)用�。該庫(kù)用Cython編寫,Cython是C語言在Python的擴(kuò)展��。它支持將近30種語言����,提供簡(jiǎn)單的深度學(xué)習(xí)集成����,并能確保穩(wěn)定性和高準(zhǔn)確性�����。SpaCy的另一個(gè)強(qiáng)大功能是無需將文檔分解��,整體處理整個(gè)文檔�。
19. Gensim(提交:3603,貢獻(xiàn)者:273)
Gensim是Python庫(kù)���,用于語義分析�、主題建模和矢量空間建模��,建立在Numpy和Scipy之上��。它提供了word2vec等NLP算法實(shí)現(xiàn)�。盡管gensim擁有自己的models.wrappers.fasttext實(shí)現(xiàn)���,但fasttext庫(kù)也可用于詞語表示的高效學(xué)習(xí)����。
數(shù)據(jù)抓取
20. Scrapy(提交:6625,貢獻(xiàn)者:281)
Scrapy可用于創(chuàng)建掃描頁(yè)面和收集結(jié)構(gòu)化數(shù)據(jù)����。另外,Scrapy還可以從API中提取數(shù)據(jù)����。由于其可擴(kuò)展性和便攜性,Scrapy非常好用�����。
今年Scrapy的更新包括代理服務(wù)器升級(jí)�,以及錯(cuò)誤通知和問題識(shí)別系統(tǒng)。這也為使用scrapy解析機(jī)械能元數(shù)據(jù)設(shè)置提供了新的方法���。
結(jié)語
以上就是2018年數(shù)據(jù)科學(xué)方面的Python庫(kù)的整理���。與去年相比,一些新的庫(kù)越來越受歡迎�,數(shù)據(jù)科學(xué)方面常用的庫(kù)也在不斷改進(jìn)。
以下的表格顯示了github上各個(gè)庫(kù)的統(tǒng)計(jì)數(shù)據(jù)�。
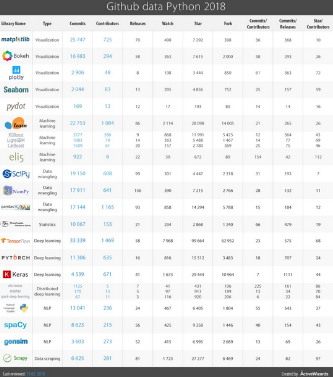
盡管今年我們擴(kuò)大了列表,但仍然可能有一些庫(kù)沒有包含在內(nèi)����,歡迎留言補(bǔ)充�。
CDA數(shù)據(jù)分析師考試相關(guān)入口一覽(建議收藏):
? 想報(bào)名CDA認(rèn)證考試,點(diǎn)擊>>>
“CDA報(bào)名”
了解CDA考試詳情;
? 想學(xué)習(xí)CDA考試教材�����,點(diǎn)擊>>> “CDA教材” 了解CDA考試詳情�����;
? 想加入CDA考試題庫(kù)����,點(diǎn)擊>>> “CDA題庫(kù)” 了解CDA考試詳情���;
? 想了解CDA考試含金量�����,點(diǎn)擊>>> “CDA含金量” 了解CDA考試詳情���;











 京公網(wǎng)安備 11010802034615號(hào)
經(jīng)營(yíng)許可證編號(hào):京B2-20210330
京公網(wǎng)安備 11010802034615號(hào)
經(jīng)營(yíng)許可證編號(hào):京B2-20210330