一個貫穿圖像處理與數(shù)據挖掘的永恒問題
創(chuàng)新對于學術研究或產業(yè)應用都具有不言而喻的重要作用����,現(xiàn)在國家也提出了要建立創(chuàng)新型國家的發(fā)展戰(zhàn)略�。如果回到我們所探討的圖像處理或數(shù)據挖掘研究,細細品讀其中的某些點滴�����,你是否能窺探出些許啟迪����?首先���,創(chuàng)新可以分成兩種,一種是原始創(chuàng)新���,另外一種就是所謂的二次創(chuàng)新����。如果一個東西過去完全不存在���,你鬼使神差的就想出來����,那就是原始創(chuàng)新����。比如圖靈當初石破天驚地構想出圖靈機模型就是原始創(chuàng)新。到現(xiàn)在也沒有任何跡象表明��,他受到了什么事或什么人的啟發(fā)���。事實上����,現(xiàn)在人們(包括我學習圖靈機的時候)也非常驚訝,圖靈是如何提出這種前無古人的奇思妙想的���!
二次創(chuàng)新也有很多種形式�����。比如逆向創(chuàng)新�。據說人們在發(fā)明吸塵器之前最先發(fā)明的是吹塵器���。一吸一吹�����,看似簡單的一個顛倒�����,結果卻如此神奇。現(xiàn)在同學們學習模式匹配算法時�����,必然是言必稱KMP算法��。的確,就原有的思路來說���,KMP算法已經是做到極致了�����。但如果你還想有所突破呢�?那就得首先打破舊有的條條框框���。所以Boyer和Moore逆其道而行之����,便提出了BM算法����。KMP是從前向后做比較,而BM則是從后向前做比較�。BM算法不僅提供了效率,更重要的是��,由他們所提出的新思路為發(fā)端�����,后續(xù)產生了一個龐大的算法族。像BMH����,BMHS等等又接踵而至。現(xiàn)在實際中基于BM算法的改進算法(相比于KMP)應用得其實更為廣泛�����!
但是今天要談的還不是逆序創(chuàng)新的話題��。我們要談的是二次創(chuàng)新中另外一種方法���,暫且稱之為“推衍創(chuàng)新”�。這個思路在現(xiàn)代計算機科學中可謂隨處可見����,如果你還沒有抓住他的名門,那么說明就研究工作來說��,你還沒入門�。舉一個簡單的例子作為序言的結尾����。最初���,“偉哥”是作為治療心絞痛的藥物而研發(fā)的。但是���,后來在臨床試驗中發(fā)現(xiàn)對治療男性勃起功能障礙更加有效�。所以現(xiàn)在它主要被應用于這方面的疾病��。所以我們所說的推衍的大概意思就是����,把一個領域的成果平行地轉移到另外一個領域,說不定就能發(fā)揮起效����!希望本文在這方面能夠給大家一些啟示。
一��、平均值與中位數(shù):一對死纏爛打的概念
平均數(shù)是統(tǒng)計學中用來衡量總體水平的一個統(tǒng)計量��。但是���,顯然它并不“完美”���。舉個例子���,現(xiàn)在房間里有6個人,他們的財富不盡相同�,但又相差無幾,這時我們可以說他們的平均身價是100萬元�。這個平均數(shù)基本上是有意義的,因為在假設前提下�����,我們知道他們6個人的財富或多或少都在100萬元上下?,F(xiàn)在馬云突然來了,然后房間里變成7個人了�����。同樣的問題���,房間里所有的人平均身價可能已經突破100億�����,但是這個平均數(shù)就沒有什么意義了?,F(xiàn)在房間里沒有誰的身價在100億上下。這時就引出了中位數(shù)的概念���!把一組數(shù)從小到大排列,取中間位置的那個數(shù)來作為衡量該組總體水平的一個統(tǒng)計量���。如果取包含馬云在內的7個人之財富的中位數(shù)����,我們知道應該還是100萬左右���,那么它顯然是有意義的����,它至少代表了這個總體中絕大多少人的情況�����。
你看出中位數(shù)的意義和作用了嗎�?現(xiàn)在當數(shù)據點分布比較均勻的時候,平均值是有意義的����。但是一旦數(shù)據中存在異常值時�����,平均數(shù)就有可能失靈���,這時就要用中位數(shù)來排除掉異常值的影響。但是平均數(shù)仍然有存在的價值����,(只是某些時候我們要對其進行修正)。例如體育比賽時的打分機制��,通常是“去掉一個最高分�,去掉一個最低分,然后去平均值”�。顯然在體育比賽打分中,用中位數(shù)就不合適����。所以我們說平均數(shù)和中位數(shù)就是一對死纏爛打的狐朋狗友!后面的內容會討論這對概念在圖像處理和數(shù)據挖掘中的重要應用���。這涉及到簡單平滑����、中值濾波、K-means算法���、k-Median算法等���。你應該注意體會前面談到的推衍創(chuàng)新思維��。這能很好地幫助你舉一反三��。
二�����、簡單平滑與中值濾波:同時聯(lián)系到LeetCode上一道Hard級別的題目
現(xiàn)實中圖像因為受到環(huán)境的影響���,很容易被噪聲所污染����。如下圖中的左上所示�����,這是一幅被椒鹽噪聲污染的圖像����。噪聲體現(xiàn)為原本過渡平滑的(自然圖像)區(qū)域中一個突兀的像素值�����。處理它最簡單的策略是用一個低通濾波器對信號進行過濾��。比如可以采用簡單平滑算法���。說白了,就是針對某個像素點����,在其領域的一個小窗口內(例如3×3),對所有像素值取平均���,然后用這個平均值來代替窗口中心位置的像素值���。這樣就能縮小噪聲和非噪聲像素之間的差距。也就是讓原本高的值變低一點��,而讓原本低的值變高一點���。結果如左下圖所示�����。易見��,簡單平滑有一定效果�����,但是并不“完美”���。舉個例子,現(xiàn)在有一杯堿性溶液(PH>7)�����,我們不斷向其中加入純水來稀釋����,結果PH值會越來越小。但是無論我們放多少水��,這個值也不可能小于7����。就算用盡全世界的水���,它的整體仍然呈現(xiàn)堿性!

有沒有更好的辦法���?如果你還沒有想到用中位數(shù)來替代均值��,那么我覺得你的頭腦應該不用再繼續(xù)讀下去了��!既然(椒鹽)噪聲是一個異常值�,那么顯然用中位數(shù)的方法來將其排掉是最好的選擇了����,這就是所謂的“中值”濾波的基本思想。上圖右下就是采用中值濾波算法處理的圖像����,顯然比簡單平滑效果好。
但是���,問題還沒完���!你有沒有想過中值濾波相對于簡單平滑的一個不足或者劣勢?是的,中值濾波的復雜度太高���,計算起來那是相當?shù)暮臅r���。為什么我會想到這個話題。因為最近我在更新我的MagicHouse(一款小型的圖像處理軟件http://blog.csdn.net/baimafujinji/article/details/50500757)����。原來中值濾波算法是由我的劉師弟完成的。他曾經是騰訊電腦管家研發(fā)的最初核心成員���,現(xiàn)在已經自主創(chuàng)業(yè)變成劉總了~我也順便遙祝他宏圖大展:)����。劉同學寫的中值濾波沒有采用進行任何優(yōu)化措施(當然這也是為了算法演示之用�,如果優(yōu)化了別人比較難把握原始算法的核心思想)��,每次執(zhí)行起來都跟感覺死機了一樣�����。于是最近我決定重寫這個算法�。
有興趣的讀者不妨搜一下關于中值濾波的加速算法,結論是這方面的paper很多,但我不得不告訴你大部分其實沒啥創(chuàng)新�����。很多都是在串行轉并行上下功夫���,我真不認為這有啥意義���。因為它們的基礎仍然是下面我要談的兩個算法。
首先來看Leetcode上一道評級為Hard級別的題目����,如下。兩個有序數(shù)組��,求它們合并后的中位數(shù)����。這當然沒啥難的,你可能會想到合并后用一個quicksort()�����,然后取中間位置��。結果上當然可以得到正確答案。但是一定要注意:題目要求算法時間復雜度是O(log(t))���,t是合并后數(shù)組的長度��。但是���,quicksort()的復雜度應該是O(t·log(t))。顯然這樣做行不通�。滿足時間復雜度要求才是本題的難點!
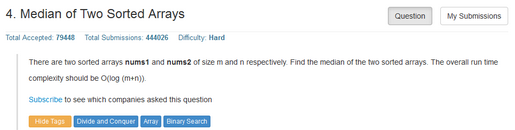
有沒有什么好方法���?題目給出的提示是要用“分治法”策略�����。而且你應該能想到是���,我們要取中位數(shù)的兩個子數(shù)組本來就是有序的,這個條件必須要好好利用�����。所以�����,本題的策略應該是:
該方法的核心是將原問題轉變成一個尋找第k小數(shù)的問題(假設兩個原序列升序排列)��,這樣中位數(shù)實際上是第(m+n)/2小的數(shù)���。所以只要解決了第k小數(shù)的問題�,原問題也得以解決����。
首先假設數(shù)組A和B的元素個數(shù)都大于k/2,我們比較A[k/2-1]和B[k/2-1]兩個元素�����,這兩個元素分別表示A的第k/2小的元素和B的第k/2小的元素��。這兩個元素比較共有三種情況:>��、<和=��。如果A[k/2-1]<B[k/2-1]���,這表示A[0]到A[k/2-1]的元素都在A和B合并之后的前k小的元素中���。換句話說�,A[k/2-1]不可能大于兩數(shù)組合并之后的第k小值�,所以我們可以將其拋棄。反之亦然�,所以當A[k/2-1]>B[k/2-1]時,我們將拋棄B[0]到B[k/2-1]的元素���。
當A[k/2-1]=B[k/2-1]時��,則已經找到了第k小的數(shù)�����,也即這個相等的元素���,將其記為m。由于在A和B中分別有k/2-1個元素小于m�,所以m即是第k小的數(shù)。(這里可能有人會有疑問���,如果k為奇數(shù)��,則m不是中位數(shù)�。當然這種情況我們后面給出的代碼里已有做特殊考慮����,但整個算法的大體思路并無不同)
通過上面的分析,我們即可以采用遞歸的方式實現(xiàn)尋找第k小的數(shù)���。此外還需要考慮幾個邊界條件:
如果A或者B為空���,則直接返回B[k-1]或者A[k-1];
如果k為1��,我們只需要返回A[0]和B[0]中的較小值��;
如果A[k/2-1]=B[k/2-1]����,返回其中一個;
最終實現(xiàn)的代碼為:
-
double findKth(vector<int>& nums1, int size1, vector<int>::iterator it1,
-
vector<int>& nums2, int size2, vector<int>::iterator it2, int k)
-
{
-
//Always assume that size1 is equal or smaller than size2
-
if (size1 > size2)
-
return findKth(nums2, size2, it2, nums1, size1, it1, k);
-
if (size1 == 0) return *(it2+k-1);
-
-
if (k == 1) return min(*it1, *it2);
-
-
//Divide k into two parts
-
int offset1 = min(k / 2, size1);
-
int offset2 = k - offset1;
-
-
if (*(it1+offset1-1) <= *(it2+offset2-1))
-
{
-
return findKth(nums1, size1 - offset1 , it1+offset1, nums2, offset2, it2, k - offset1);
-
}
-
else
-
{
-
return findKth(nums1, offset1, it1, nums2, size2 - offset2, it2+offset2, k - offset2);
-
}
-
}
-
-
-
double findMedianSortedArrays(vector<int>& nums1, vector<int>& nums2) {
-
-
int m = nums1.size();
-
int n = nums2.size();
-
int total = m + n;
-
-
double result = findKth(nums1, m, nums1.begin(), nums2, n, nums2.begin(), (total + 1) / 2);
-
if ((total & 1) == 0) //Odd
-
{
-
result = (result + findKth( nums1, m, nums1.begin(), nums2, n, nums2.begin(), total / 2 + 1)) / 2;
-
}
-
return result;
-
}
通過對上述LeetCode題目的討論�����,其實已經可以給出我們一些優(yōu)化的想法了�。來看下面這個圖,當我們最初計算紅色像素的鄰域中值時���,其實已經得到了紅框中像素值的一個有序排列�。然后在計算綠色像素的鄰域中值時,我們把滑塊向后移動�����。這時為了避免重復計算�����,一定要充分利用之前的有序結果�����。剔除最左面三個像素后的紅框中的6個像素仍然有序�,這時只要把新加入的綠框中的三個元素也做排序,然后得到兩個有序的序列��,是不是就變成了上我們討論的問題了��?而且�����,這個算法面對更大的滑動窗口時,優(yōu)勢會更為明顯�。
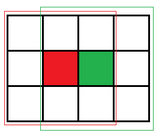
但是,如果我們只想計算3×3鄰域內的中值����,其實還有另外一個選擇��。例如下面的鄰域
0 1 2
3 4 5
6 7 8
首先對窗口內的每一列分別計算最大值����,中值和最小值,這樣就得到了3組數(shù)據
最大值組:Max0 = max[P0�����,P3�,P6],Max1 = max[P1��,P4�����,P7]���,Max2 = max[P2����,P5,P8]
中值組: Med0 = med[P0�,P3,P6]���,Med1 = med[P1�,P4�����,P7]�����, Med2 = med[P2�����,P5�����,P8]
最小值組:Min0 = Min[P0,P3��,P6]��,Min1 = Min[P1����,P4,P7]��,Min2 = max[P2��,P5��,P8]
由此可以看到��,最大值組中的最大值與最小值組中的最小值一定是9個元素中的最大值和最小值���,不可能為中值,剩下7個����;中值組中的最大值至少大于5個像素,中值組中的最小值至少小于5個像素�����,不可能為中值,剩下5個���;最大值組中的中值至少大于5個元素�,最小值組中的中值至少小于5個元素���,不可能為中值��,最后剩下3個要比較的元素��,即
最大值組中的最小值Maxmin��,中值組中的中值Medmed����,最小值組中的最大值MinMax����;找出這三個值中的中值為9個元素的中值。
采用上述方法��,也會大大降低計算量��。可見設計一個好算法永遠是那么的重要�!
三、數(shù)據挖掘中的K-means和K-median
聚類是將相似對象歸到同一個簇中的方法�����,這有點像全自動分類����。簇內的對象越相似,聚類的效果越好��。支持向量機�����、神經網絡所討論的分類問題都是有監(jiān)督的學習方式���,現(xiàn)在我們所介紹的聚類則是無監(jiān)督的。其中��,K均值(K-means)是最基本�����、最簡單的聚類算法。
在K均值算法中��,質心是定義聚類原型(也就是機器學習獲得的結果)的核心�����。在介紹算法實施的具體過程中�,我們將演示質心的計算方法。而且你將看到除了第一次的質心是被指定的以外�����,此后的質心都是經由計算均值而獲得的�����。
首先��,選擇K個初始質心(這K個質心并不要求來自于樣本數(shù)據集)�����,其中K是用戶指定的參數(shù)�����,也就是所期望的簇的個數(shù)。每個數(shù)據點都被收歸到距其最近之質心的分類中��,而同一個質心所收歸的點集為一個簇���。然后�,根據本次分類的結果�����,更新每個簇的質心���。重復上述數(shù)據點分類與質心變更步驟���,直到簇內數(shù)據點不再改變,或者等價地說��,直到質心不再改變��。
基本的K均值算法描述如下:
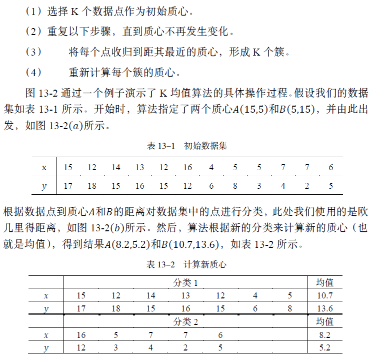
根據數(shù)據點到新質心的距離���,再次對數(shù)據集中的數(shù)據進行分類,如圖13-2(c)所示����。然后�,算法根據新的分類來計算新的質心�����,并再次根據數(shù)據點到新質心的距離�,對數(shù)據集中的數(shù)據進行分類。結果發(fā)現(xiàn)簇內數(shù)據點不再改變���,所以算法執(zhí)行結束����,最終的聚類結果如圖13-2(d)所示���。
對于距離函數(shù)和質心類型的某些組合�����,算法總是收斂到一個解����,即K均值到達一種狀態(tài)�,聚類結果和質心都不再改變�����。但為了避免過度迭代所導致的時間消耗��,實踐中���,也常用一個較弱的條件替換掉“質心不再發(fā)生變化”這個條件。例如�����,使用“直到僅有1%的點改變簇”���。
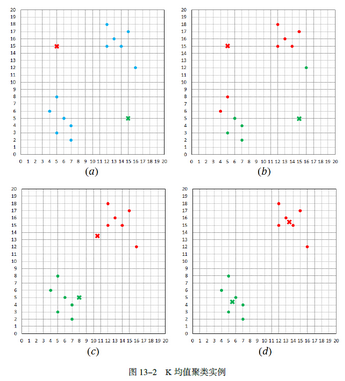
盡管K均值聚類比較簡單�,但它也的確相當有效��。它的某些變種甚至更有效����,
并且不太受初始化問題的影響�。但K均值并不適合所有的數(shù)據類型。它不能處理非球形簇���、不同尺寸和不同密度的簇���,盡管指定足夠大的簇個數(shù)時它通?����?梢园l(fā)現(xiàn)純子簇�。對包含離群點的數(shù)據進行聚類時�,K均值也有問題。在這種情況下����,離群點檢測和刪除大有幫助。K均值的另一個問題是�,它對初值的選擇是敏感的,這說明不同初值的選擇所導致的迭代次數(shù)可能相差很大�����。此外�����,K值的選擇也是一個問題。顯然��,算法本身并不能自適應地判定數(shù)據集應該被劃分成幾個簇����。最后,K均值僅限于具有質心(均值)概念的數(shù)據���。一種相關的K中心點聚類技術沒有這種限制�����。在K中心點聚類中����,我們每次選擇的不再是均值�,而是中位數(shù)。這種算法實現(xiàn)的其他細節(jié)與K均值相差不大���,我們不再贅述�����。
最后我們給出一個實際應用的例子�����。(代碼采用我最喜歡用做數(shù)據挖掘的R語言來實現(xiàn))
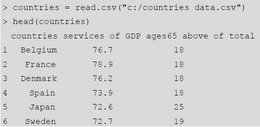
一組來自世界銀行的數(shù)據統(tǒng)計了30個國家的兩項指標���,我們用如下代碼讀入文件并顯示其中最開始的幾行數(shù)據??梢姡瑪?shù)據共分散列���,其中第一列是國家的名字����,該項與后面的聚類分析無關�,我們更關心后面兩列信息。第二列給出的該國第三產業(yè)增加值占GDP的比重���,最后一列給出的是人口結構中年齡大于等于65歲的人口(也就是老齡人口)占總人口的比重�����。
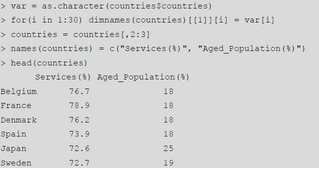
為了方便后續(xù)處理�,下面對讀入的數(shù)據庫進行一些必要的預處理�����,主要是調整列標簽,以及用國名替換掉行標簽(同時刪除包含國名的列)�����。
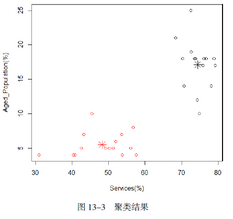
如果你繪制這些數(shù)據的散點圖��,不難發(fā)現(xiàn)這些數(shù)據大致可以分為兩組���。事實上�,數(shù)據中有一半的國家是OECD成員國����,而另外一半則屬于發(fā)展中國家(包括一些東盟國家、南亞國家和拉美國家)�。所以我們可以采用下面的代碼來進行K均值聚類分析。

對于聚類結果��,限于篇幅我們仍然只列出了最開始的幾條����。但是如果用圖形來顯示的話,可能更易于接受�。下面是示例代碼���。

上述代碼的執(zhí)行結果如圖13-3所示。
現(xiàn)在如果我問能不能提出另外一種與k-means類似的算法����,你會想到什么����?如果你能從k-均值算法想到提出k-中值算法,那么你算是沒白讀這篇文章�!觸類旁通,舉一反三這招你算真學會了��。(我想我已經無需再詳細介紹k-中值算法的細節(jié)了�����,基本上和k-means一樣��,只是把所有均值出現(xiàn)的地方換成中值而已)這個思想看起好像很不起眼�,但是你還別說,k-median算法還真的存在�,而且是k-means算法的一個重要補充和改進。你可能會說提出k-median算法的人絕對是撿了一個大便宜�����,這么輕輕松松地就提出了一個足以留名的算法。但其實我想說�,真正想到這一點的人,功力也絕對不可小覷���。冰凍三尺�����、非一日之寒���。唯有基礎扎實,內力深厚的大家才能擁有這般敏銳的創(chuàng)新嗅覺�。
CDA數(shù)據分析師考試相關入口一覽(建議收藏):
? 想報名CDA認證考試,點擊>>>
“CDA報名”
了解CDA考試詳情���;
? 想學習CDA考試教材�����,點擊>>> “CDA教材” 了解CDA考試詳情�;
? 想加入CDA考試題庫�,點擊>>> “CDA題庫” 了解CDA考試詳情�;
? 想了解CDA考試含金量���,點擊>>> “CDA含金量” 了解CDA考試詳情�;











 京公網安備 11010802034615號
經營許可證編號:京B2-20210330
京公網安備 11010802034615號
經營許可證編號:京B2-20210330