圖數據挖掘淺析
互聯網發(fā)展至今,數據規(guī)模越來越大����,數據結構越來越復雜,而且對系統(tǒng)的需求越來越高����。如果學習過數據結構,那么都知道圖是放在最后一個結構���,當你學習了圖��,那么應該感知到前面的鏈表�,隊列����,樹都是在圖上面加了一些約束而派生出來的結構��。所以圖是一個一般性的結構�����,可以適應于任何結構類型的數據。
一����、什么是圖數據挖掘
這個話題感覺比較沉重,以至于我敲打每個字都要猶豫半天����,這里我說說我對圖數據挖掘的理解。數據是一個不可數名字����,那么說明數據是一個沒有邊界的東西。而挖掘是一個很形象化的動詞����,一般意義上,挖掘是挖掘出對我們有用的東西��,不然也不會閑著沒事刨個坑把自己放進去,肯定是里面有寶貝�,我們才挖掘。那么不難理解���,數據挖掘就是挖掘數據里面的“寶貝”�����,圖數據挖掘�,就是以圖的結構來存儲�、展示、思考數據��,以達到挖掘出其中的“寶貝”�。那這個“寶貝”是什么?這個有點主觀意識來理解了���,“寶貝”這個詞本身就帶有主觀色彩�,而沒有一個客觀的答案���,不像是美女大胸�、翹臀��、高挑、皮膚白皙�、臉蛋好看等一系列標準。那么如何理解圖數據里面的“寶貝”呢��?舉個例子吧���,例如:當今互聯網產生了很多社交數據��,某某關注了某某,那么某某和某某就有了關系��,某某評論過某某���,那么這又產生了關系��,在這個里面某某就是圖中的節(jié)點����,而評論過����,關注了則是節(jié)點之間的關系,如果某某再多點����,這就形成了一個無邊界的圖了�����。那么對這個圖進行關系挖掘���,那么會產生很多有用的數據,比如可以推薦你可能認識的人�,那就是朋友的朋友,甚至更深����,這就形成了某空間好友推薦的功能。比如某寶的你可能喜歡的寶貝�����,可以通過圖數據挖掘來實現�����。這就是我認為的圖數據挖掘���。
從學術上講�����,圖數據挖掘分為數據圖���,模式圖兩種�����。至于這兩個類型的區(qū)別����,由于很久沒有關注這塊����,所以只能給出一個字面意義上的區(qū)別�����。數據圖:則是以數據節(jié)點為基礎來進行分析圖��,模式圖:則是以數據整個關系模型來進行分析數據�。可能解釋存在錯誤�,望指正���。我之前主要是接觸數據圖一塊的東西,模式圖沒有太多了解���。關于數據圖和模式圖在學術界存在幾個比較有參考意義的實現以及算法��。數據圖有:BANKS,BLINKS,Object
rank��;模式圖有:DBXplorer(微軟),DISCOVER(加利福尼亞大學)�����,S-CBR(人民大學���,就是在大學學數據庫都會知道的人:王珊)。下面主要對數據圖的幾種實現進行簡單介紹����,模式圖,可以找上面相關論文進行了解��。
二�、數據圖典型實現介紹
1、BANK(Browsing
and Keyword Searching in Relational Databases)
整體上說一下它的思想是通過關系數據庫進行存儲圖結構的數據加上Dijkstra算法來進行數據的存儲和圖數據的搜索。該算法第一步先是匹配所有關鍵詞的關鍵節(jié)點�,并且以每個關鍵節(jié)點為源節(jié)點進行一次Dijkstra算法對圖進行遍歷,因此可以形成和每個關鍵節(jié)點可達的節(jié)點堆�����,該堆是進行了按照到關鍵節(jié)點距離進行堆排序的堆����。因此可以想想每個關鍵節(jié)點的節(jié)點堆的第一個元素則是到該關鍵節(jié)點最近的節(jié)點。利用這個�,那么對每個節(jié)點堆一次遍歷,每次遍歷只取堆的第一個節(jié)點�,可以得知,這個取出的節(jié)點和節(jié)點對對應的關鍵詞是可達的�����,如果這個節(jié)點和所有關鍵節(jié)點可達�,那么就可以這個節(jié)點為根節(jié)點形成一個結果樹���,所以需要對這個取出的節(jié)點進行標記���,標記的目的就是說我這個關鍵節(jié)點來過這里了(有點類似到此一游的感覺)。這就是BANK的大體上的算法思想����。下面提出一個流程圖�����,幫助大家理解一下���。
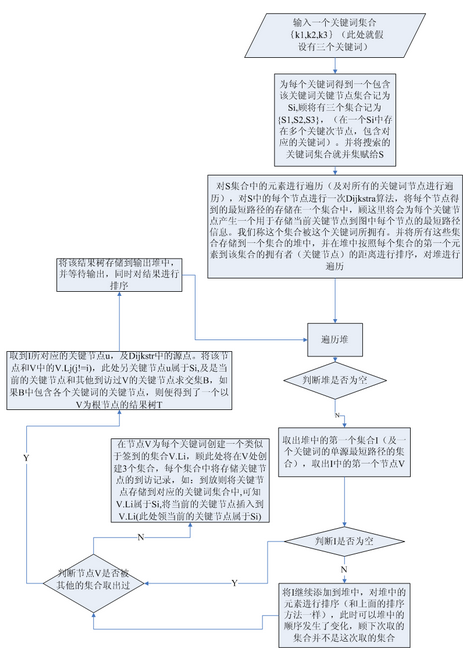
這種方式存在幾個缺點:由于它的這個算法是需要把整個圖結構加載到內存中,所以當節(jié)點數一大����,那么可能會內存的限制。第二個缺點是�,它的搜索是單向的,這樣在效率上面存在一定的缺陷�。這個算法也是我研究圖數據挖掘主要研究的對象,因為比較簡單���,容易理解�。下面針對上面兩個缺陷介紹另外兩個算法�����。
2、Bidirectional
Expansion For Keyword Search on Graph Databases
這個算法則是在第一個基礎上面進行了擴展��,支持雙向搜索��。從而解決了上麥年的第二個缺陷�����。具體算法實現��,很久沒接觸了�����,而且當時也沒關注這方面的實現�����,所以我也不是很清楚�����,只是知道它實現了雙向遍歷��。具體的可以點擊標題��,看它的論文���。
3�、BLINK BLINKS
Ranked keyword searches on graphs
這個實現是解決了大圖問題���,通過對圖進行分割�����,形成超圖的概念��,加載內存只需要把超圖進來��,當需要遍歷這個超圖節(jié)點的時候����,再將超圖節(jié)點里面的明細節(jié)點加載到內存�,基于這個概念可以很好的解決節(jié)點數量大而受內存的限制,這個算法有點類似地圖的放大鏡���,當需要展示某一塊(超圖節(jié)點)的時候�����,則加載當前塊的內容�����,用戶就會看到更加明細的地圖信息�����。具體算法����,可以點擊標題,看看它的論文�����。
既然說道圖��,那么不得不提一下在圖數據庫方面最流行的neo4j�����。neo4j是在09年過年的時候接觸的����,當時是調研以何種方式來存儲圖數據��,所以當時弄了一下,后沒就沒關注了��。當時看neo4j真的很小�,不像現在這么成熟。
三����、NEO4J預覽
在NEO4J官方文檔里面會看到下面幾點介紹圖數據庫。
“A Graph —records data in→ Nodes —which have→ Properties”
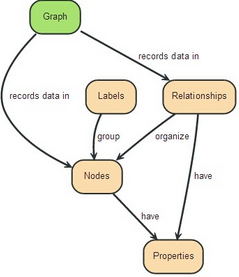
上面很簡單明了的介紹了圖是什么���,圖是以節(jié)點存儲記錄數據�����,而節(jié)點數據是以屬性形式關聯節(jié)點���。
“Nodes —are organized by→ Relationships —which also have→ Properties”
這句話說明了關系在圖中的作用,可以理解節(jié)點是通過關系來進行組織和管理�����,并且關系也可以包裹屬性信息��。
“Nodes —are grouped by→ Labels —into→ Sets”
在圖中標簽的作用就是對節(jié)點進行分組,并且同一個標簽的節(jié)點會放到一個集合中�����,這個有點類似上面說的對圖進行分割�����。比如:給節(jié)點貼上一個“人”的標簽����,那么當對圖進行搜索的時候,當指定“人”這個標簽的時候���,那么只會找到所有人的節(jié)點���,而不會找到貓,狗等節(jié)點����。這樣可以提高圖的遍歷速度,而且可以更好的管理圖的節(jié)點���。
“A Traversal —navigates→ a Graph; it —identifies→ Paths —which order→ Nodes”
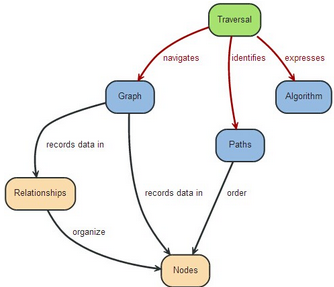
一個路徑的遍歷����,它可以正確的導航整個圖的結構遍歷,并且它可以對應一系列路徑����,這些路徑則是將所有節(jié)點串聯起來����。這個解釋了搜索在圖中的定位,一條搜索可以對應多條路徑����,也就是多條結果,而每個結果包含一系列節(jié)點�����。
“An Index —maps from→ Properties —to either→ Nodes or Relationships”
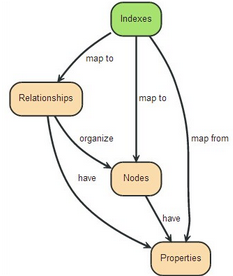
圖中的建立索引的數據來自于節(jié)點和關系的屬性���,并且索引會直接映射到節(jié)點和關系���。這樣可以通過索引遍歷圖中的節(jié)點和關系,以得到結果����。
“A Graph Database —manages a→ Graph and —also manages related→ Indexes”
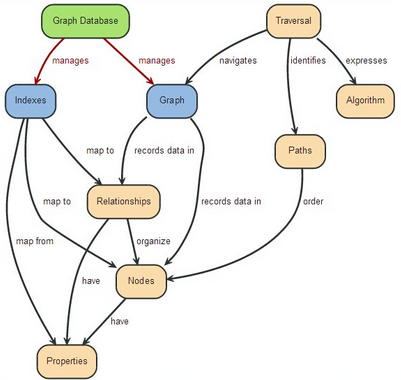
這里明確的表示了圖數據是干什么的���,同時也表達了NEO4J是干什么的。他是管理和維護圖數據CRUD�,并且維護圖數據的索引建立和更新。是對圖數據操作的一個對外接口��。
上面是隔了四年之久�,再次關注NEO4J,感覺它已經真的長大了����,之前只是一個很小很小的一個基本上不會關注的項目,到今天已經發(fā)展到了圖數據庫的領頭羊�����。
CDA數據分析師考試相關入口一覽(建議收藏):
? 想報名CDA認證考試����,點擊>>>
“CDA報名”
了解CDA考試詳情;
? 想學習CDA考試教材���,點擊>>> “CDA教材” 了解CDA考試詳情�����;
? 想加入CDA考試題庫��,點擊>>> “CDA題庫” 了解CDA考試詳情����;
? 想了解CDA考試含金量,點擊>>> “CDA含金量” 了解CDA考試詳情�;











 京公網安備 11010802034615號
經營許可證編號:京B2-20210330
京公網安備 11010802034615號
經營許可證編號:京B2-20210330