R語言︱決策樹族——隨機森林算法
一�、隨機森林理論介紹
1.1 優(yōu)缺點
優(yōu)點。
(1)不必擔心過度擬合��;
(2)適用于數(shù)據(jù)集中存在大量未知特征��;
(3)能夠估計哪個特征在分類中更重要�����;
(4)具有很好的抗噪聲能力����;
(5)算法容易理解��;
(6)可以并行處理�����。
缺點���。
(1)對小量數(shù)據(jù)集和低維數(shù)據(jù)集的分類不一定可以得到很好的效果��。
(2)執(zhí)行速度雖然比Boosting等快���,但是比單個的決策樹慢很多��。
(3)可能會出現(xiàn)一些差異度非常小的樹����,淹沒了一些正確的決策����。
1.2 生成步驟介紹
1、從原始訓練數(shù)據(jù)集中��,應用bootstrap方法有放回地隨機抽取k個新的自助樣本集��,并由此構建k棵分類回歸樹�,每次未被抽到的樣本組成了K個袋外數(shù)據(jù)(out-of-bag,BBB)。
2����、設有n 個特征,則在每一棵樹的每個節(jié)點處隨機抽取mtry 個特征���,通過計算每個特征蘊含的信息量�����,特征中選擇一個最具有分類能力的特征進行節(jié)點分裂�����。
3����、每棵樹最大限度地生長, 不做任何剪裁
4�����、將生成的多棵樹組成隨機森林��, 用隨機森林對新的數(shù)據(jù)進行分類, 分類結果按樹分類器投票多少而定��。
1.3 隨機森林與SVM的比較
(1)不需要調節(jié)過多的參數(shù)���,因為隨機森林只需要調節(jié)樹的數(shù)量,而且樹的數(shù)量一般是越多越好����,而其他機器學習算法���,比如SVM,有非常多超參數(shù)需要調整����,如選擇最合適的核函數(shù),正則懲罰等�。
(2)分類較為簡單、直接����。隨機深林和支持向量機都是非參數(shù)模型(復雜度隨著訓練模型樣本的增加而增大)。相較于一般線性模型����,就計算消耗來看,訓練非參數(shù)模型因此更為耗時耗力�。分類樹越多,需要更耗時來構建隨機森林模型�����。同樣���,我們訓練出來的支持向量機有很多支持向量��,最壞情況為�����,我們訓練集有多少實例���,就有多少支持向量��。雖然��,我們可以使用多類支持向量機����,但傳統(tǒng)多類分類問題的執(zhí)行一般是one-vs-all(所謂one-vs-all 就是將binary分類的方法應用到多類分類中����。比如我想分成K類�����,那么就將其中一類作為positive)��,因此我們還是需要為每個類訓練一個支持向量機。相反���,決策樹與隨機深林則可以毫無壓力解決多類問題��。
(3)比較容易入手實踐����。隨機森林在訓練模型上要更為簡單�。你很容易可以得到一個又好且具魯棒性的模型。隨機森林模型的復雜度與訓練樣本和樹成正比�。支持向量機則需要我們在調參方面做些工作,除此之外����,計算成本會隨著類增加呈線性增長。
(4)小數(shù)據(jù)上����,SVM優(yōu)異,而隨機森林對數(shù)據(jù)需求較大�。就經(jīng)驗來說,我更愿意認為支持向量機在存在較少極值的小數(shù)據(jù)集上具有優(yōu)勢����。隨機森林則需要更多數(shù)據(jù)但一般可以得到非常好的且具有魯棒性的模型���。
1.5 隨機森林與深度學習的比較
深度學習需要比隨機森林更大的模型來擬合模型,往往��,深度學習算法需要耗時更大��,相比于諸如隨機森林和支持向量機那樣的現(xiàn)成分類器����,安裝配置好一個神經(jīng)網(wǎng)絡模型來使用深度學習算法的過程則更為乏味。
但不可否認����,深度學習在更為復雜問題上,如圖片分類����,自然語言處理,語音識別方面更具優(yōu)勢����。
另外一個優(yōu)勢為你不需要太關注特征工程相關工作。實際上���,至于如何選擇分類器取決于你的數(shù)據(jù)量和問題的一般復雜性(和你要求的效果)。這也是你作為機器學習從業(yè)者逐步會獲得的經(jīng)驗。
可參考論文《An Empirical Comparison of Supervised Learning Algorithms》��。
1.6 隨機森林與決策樹之間的區(qū)別
模型克服了單棵決策樹易過擬合的缺點���,模型效果在準確性和穩(wěn)定性方面都有顯著提升�。
決策樹+bagging=隨機森林
1.7 隨機森林不會發(fā)生過擬合的原因
在建立每一棵決策樹的過程中�,有兩點需要注意-采樣與完全分裂。首先是兩個隨機采樣的過程���,random forest對輸入的數(shù)據(jù)要進行行�、列的采樣���。對于行采樣����,采用有放回的方式����,也就是在采樣得到的樣本集合中,可能有重復的樣本�����。
假設輸入樣本為N個,那么采樣的樣本也為N個���。這樣使得在訓練的時候�,每一棵樹的輸入樣本都不是全部的樣本���,使得相對不容易出現(xiàn)over-fitting�。
然后進行列采樣�����,從M個feature中���,選擇m個(m << M)�����。之后就是對采樣之后的數(shù)據(jù)使用完全分裂的方式建立出決策樹�����,這樣決策樹的某一個葉子節(jié)點要么是無法繼續(xù)分裂的��,要么里面的所有樣本的都是指向的同一個分類��。一般很多的決策樹算法都一個重要的步驟-剪枝�����,但是這里不這樣干�����,由于之前的兩個隨機采樣的過程保證了隨機性����,所以就算不剪枝�,也不會出現(xiàn)over-fitting。 按這種算法得到的隨機森林中的每一棵都是很弱的���,但是大家組合起來就很厲害了�����。
可以這樣比喻隨機森林算法:每一棵決策樹就是一個精通于某一個窄領域的專家(因為我們從M個feature中選擇m讓每一棵決策樹進行學習)����,這樣在隨機森林中就有了很多個精通不同領域的專家�����,對一個新的問題(新的輸入數(shù)據(jù)),可以用不同的角度去看待它��,最終由各個專家����,投票得到結果。
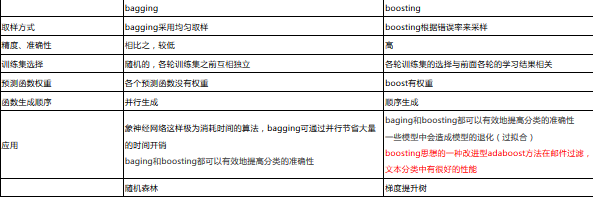
1.8 隨機森林與梯度提升樹(GBDT)區(qū)
隨機森林:決策樹+bagging=隨機森林
梯度提升樹:決策樹Boosting=GBDT
兩者區(qū)別在于bagging boosting之間的區(qū)別����,可見:
1.9 決策樹的特征選擇
本部分參考:隨機森林簡易教程
特征選擇目前比較流行的方法是信息增益、增益率��、基尼系數(shù)和卡方檢驗�。這里主要介紹基于基尼系數(shù)(GINI)的特征選擇,因為隨機森林采用的CART決策樹就是基于基尼系數(shù)選擇特征的�����。
基尼系數(shù)的選擇的標準就是每個子節(jié)點達到最高的純度����,即落在子節(jié)點中的所有觀察都屬于同一個分類,此時基尼系數(shù)最小,純度最高��,不確定度最小�����。
決策樹中最常用的四種算法:
基尼系數(shù)(Gini Index)
基尼系數(shù)指出:我們從總體中隨機挑選兩個樣本��,如果總體是純的�����,那么這兩個樣本是同類別的概率為1���。
用于處理分類型目標變量“Success”或者“Failure”。
它只作用于二進制分裂����。
基尼系數(shù)越大,純度越高�����。
CART(分類和回歸樹)使用Gini方法創(chuàng)建二進制分裂�。
卡方(Chi-Square)
它可以用來衡量子節(jié)點和父節(jié)點之間是否存在顯著性差異。我們用目標變量的觀測頻率和期望頻率之間的標準離差的平方和來計算卡方值���。
它用于處理分類型目標變量“Success”或“Failure”���。
它可以計算兩個或多個分裂����。
卡方越高���,子節(jié)點與父節(jié)點之間的差異越顯著��。
Chi-square = ((Actual – Expected)^2 / Expected)^1/2
它生成的樹稱為:CHAID (Chi-square Automatic Interaction Detector)
如何計算一個分裂的卡方:
通過計算Success和Failure的偏差來計算單個節(jié)點的卡方��。
通過計算每個節(jié)點的Success和Failure的所有卡方總和計算一個分裂的卡方�。
信息增益(Information Gain)
觀察下面的圖像�,想一下哪個節(jié)點描述起來更加容易。答案一定是C��,因為C圖中的所有的值都是相似的���,需要較少的信息去解釋��。相比較�,B和A需要更多的信息去描述。用純度描述�����,就是:Pure(C) > Pure(B) > Pure(A)�����。
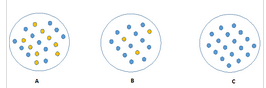
純度越高的節(jié)點�����,就會需要更少的信息去描述它����;相反�����,不純度越高�����,就會需要更多的信息�。信息論用熵來定義系統(tǒng)的混亂程度。如果樣本中的個體是完全相同類別的,那么系統(tǒng)的熵為0����;如果樣本是等劃分的(50%-50%),那么系統(tǒng)的熵為1��。
方差削減(Reduction in Variance)
至此��,我們已經(jīng)討論了很多關于分類型目標變量的算法���。方差削減是用于連續(xù)型目標變量的算法(回歸問題)�。它使用方差公式去挑選最優(yōu)分裂�。方差最小的分裂將會作為分割總體的準則。
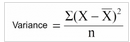
如何計算方差�?
計算每一個節(jié)點的方差。
計算每一個節(jié)點方差的加權平均��,作為一個分裂的方差�����。
二�、隨機森林重要性度量指標——重要性評分、Gini指數(shù)
(1)重要性評分
定義為袋外數(shù)據(jù)自變量值發(fā)生輕微擾動后的分類正確率與擾動前分類正確率的平均減少量����。
(1):對于每棵決策樹�,利用袋外數(shù)據(jù)進行預測�,將袋外數(shù)據(jù)的預測誤差將記錄下來。其每棵樹的誤差是:vote1��,vote2····����,voteb;
(2):隨機變換每個預測變量�,從而形成新的袋外數(shù)據(jù),再利用袋外數(shù)據(jù)進行驗證��,其每個變量的誤差是:vote11��,vote12�����,···����,vote1b��。
(3):對于某預測變量來說,計算其重要性是變換后的預測誤差與原來相比的差的均值���。
r語言中代碼:
[plain] view plain copy
rf <- randomForest(Species ~ ., data=a, ntree=100, proximity=TRUE,importance=TRUE)

(2)gini指數(shù)
gini指數(shù)表示節(jié)點的純度�,gini指數(shù)越大純度越低��。gini值平均降低量表示所有樹的變量分割節(jié)點平均減小的不純度�。對于變量重要度衡量,步驟如同前面介紹�,將變量數(shù)據(jù)打亂,gini指數(shù)變化的均值作為變量的重要程度度量��。
(3)重要性繪圖函數(shù)——varImpPlot(rf)函數(shù)
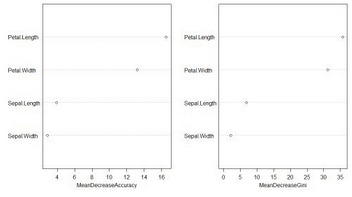
三��、隨機森林模型R語言實踐
3.1 隨機森林模型幾點注意
模型中關于分類任務以及回歸預測任務的區(qū)別:
隨機森林模型���,分類和回歸預測的操作不同之處在于判斷因變量的類型�����,如果因變量是因子則執(zhí)行分類任務�,如果因變量是連續(xù)性變量����,則執(zhí)行回歸預測任務�。
模型中關于數(shù)據(jù)結構的要求:
`randomForest`函數(shù)要求為數(shù)據(jù)框或者矩陣��,需要原來的數(shù)據(jù)框調整為以每個詞作為列名稱(變量)的數(shù)據(jù)框�。在文本挖掘的過程中,需要把詞頻(橫向�����,long型數(shù)據(jù))轉化為變量(wide型縱向數(shù)據(jù))�,可以用reshape2、data.table包來中dcast來實現(xiàn)�����。
隨機森林的兩個參數(shù):
候選特征數(shù)K
K越大��,單棵樹的效果會提升�,但樹之間相關性也會增強
決策樹數(shù)量M
M越大,模型效果會有提升�����,但計算量會變大
R中與決策樹有關的Package:
單棵決策樹:rpart/tree/C50
隨機森林:randomforest/ranger
梯度提升樹:gbm/xgboost
樹的可視化:rpart.plot
3.2 模型擬合
本文以R語言中自帶的數(shù)據(jù)集iris為例����,以setosa為因變量,其他作為自變量進行模型擬合����,由于setosa本身就是因子型,所以不用轉換形式���。
[plain] view plain copy
> data <- iris
> library(randomForest)
> system.time(Randommodel <- randomForest(Species ~ ., data=data,importance = TRUE, proximity = FALSE, ntree = 100))
用戶 系統(tǒng) 流逝
0 0 0
> print(Randommodel)
Call:
randomForest(formula = Species ~ ., data = data, importance = TRUE, proximity = FALSE, ntree = 100)
Type of random forest: classification
Number of trees: 100
No. of variables tried at each split: 2
OOB estimate of error rate: 3.33%
Confusion matrix:
setosa versicolor virginica class.error
setosa 50 0 0 0.00
versicolor 0 47 3 0.06
virginica 0 2 48 0.04
代碼解讀:randomForset���,執(zhí)行建模,x參數(shù)設定自變量數(shù)據(jù)集�����,y參數(shù)設定因變量數(shù)據(jù)列����,importance設定是否輸出因變量在模型中的重要性,如果移除某個變量�,模型方差增加的比例是它判斷變量重要性的標準之一,proximity參數(shù)用于設定是否計算模型的臨近矩陣����,ntree用于設定隨機森林的樹數(shù)(后面單獨討論),最后一句輸出模型在訓練集上的效果�����。
prInt輸出模型在訓練集上的效果,可以看出錯誤率為3.33%�,維持在比較低的水平。
3.3 隨機森林模型重要性檢
[plain] view plain copy
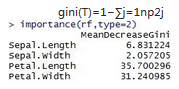
> importance(Randommodel,type=1) #重要性評分
MeanDecreaseAccuracy
Sepal.Length 4.720094
Sepal.Width 1.405924
Petal.Length 16.222059
Petal.Width 13.895115
> importance(Randommodel,type=2) #Gini指數(shù)
MeanDecreaseGini
Sepal.Length 9.484106
Sepal.Width 1.930289
Petal.Length 45.873386
Petal.Width 41.894352
> varImpPlot(Randommodel) #可視化
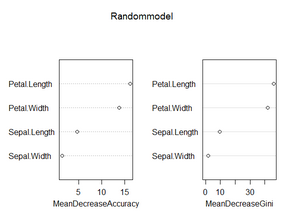
利用iris數(shù)據(jù)���,可以看到這四個變量的重要性排序是一樣的�。
3.4 模型的預測功能
predict中有多種參數(shù)�,比如Nodes,Proximity�����,predict.all��。
[plain] view plain copy
predict(object, newdata, type="response",
norm.votes=TRUE, predict.all=FALSE, proximity=FALSE, nodes=FALSE,
cutoff, ...)
#Nodes判斷是否是終點�����。Proximity判斷是否需要進行近鄰測量�。predict.all判斷是否保留所有的預測器。
舉例�,以前面的隨機森林模型進行建模�����。
predict.all會輸出一個150*150的字符矩陣,代表每一顆樹的150個預測值(前面預設了ntree=100)����;
Nodes輸出100顆樹的節(jié)點情況。
[plain] view plain copy
prediction <- predict(Randommodel, data[,1:5],type="class") #還有response回歸類型
table(observed =data$Species,predicted=prediction)
table輸出混淆矩陣�����,注意table并不是需要把預測值以及實際值放在一個表格之中����,只要順序對上,用observed以及predicted直接調用也可以����。
3.5 補充——隨機森林包(party包)
與randomForest包不同之處在于,party可以處理缺失值����,而這個包可以。
[html] view plain copy
library(party)
#與randomForest包不同之處在于����,party可以處理缺失值��,而這個包可以
set.seed(42)
crf<-cforest(y~.,control = cforest_unbiased(mtry = 2, ntree = 50), data=step2_1)
varimpt<-data.frame(varimp(crf))
party包中的隨機森林建模函數(shù)為cforest函數(shù)���,
mtry代表在每一棵樹的每個節(jié)點處隨機抽取mtry 個特征,通過計算每個特征蘊含的信息量�����,特征中選擇一個最具有分類能力的特征進行節(jié)點分裂��。
CDA數(shù)據(jù)分析師考試相關入口一覽(建議收藏):
? 想報名CDA認證考試���,點擊>>>
“CDA報名”
了解CDA考試詳情��;
? 想學習CDA考試教材���,點擊>>> “CDA教材” 了解CDA考試詳情;
? 想加入CDA考試題庫�����,點擊>>> “CDA題庫” 了解CDA考試詳情�����;
? 想了解CDA考試含金量,點擊>>> “CDA含金量” 了解CDA考試詳情��;











 京公網(wǎng)安備 11010802034615號
經(jīng)營許可證編號:京B2-20210330
京公網(wǎng)安備 11010802034615號
經(jīng)營許可證編號:京B2-20210330