R語言實現(xiàn)決策樹算法
決策樹算法的R實現(xiàn)
根據(jù)ppvk上的文章《基于 R 語言和 SPSS 的決策樹算法介紹及應(yīng)用》�,只簡單跑了關(guān)于R部分的代碼,實驗成功,簡單記錄下����。
決策樹算法簡介
R語言實現(xiàn)
決策樹算法
決策樹算法是一種典型的分類方法���,首先對數(shù)據(jù)進(jìn)行處理����,利用歸納算法生成可讀的規(guī)則和決策樹���,然后使用決策對新數(shù)據(jù)進(jìn)行分析����。本質(zhì)上決策樹是通過一系列規(guī)則對數(shù)據(jù)進(jìn)行分類的過程�����。
一個簡單的決策樹示例(圖片來源網(wǎng)絡(luò)):
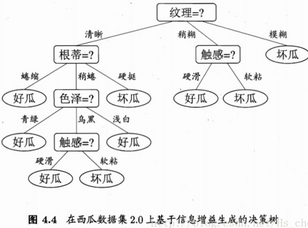
決策樹由節(jié)點和有向邊組成,內(nèi)部節(jié)點代表了特征屬性�����,外部節(jié)點(葉子節(jié)點)代表了類別���,根據(jù)一步步地屬性分類可以將整個特征空間進(jìn)行劃分����,從而區(qū)別出不同的分類樣本�。好的決策樹不僅對訓(xùn)練樣本有著很好的分類效果,對于測試集也有著較低的誤差率����。
數(shù)據(jù)集純度函數(shù)
信息增益
信息熵表示的是不確定度。均勻分布時�,不確定度最大,此時熵就最大���。當(dāng)選擇某個特征對數(shù)據(jù)集進(jìn)行分類時���,分類后的數(shù)據(jù)集信息熵會比分類前的小��,其差值表示為信息增益�����。
假設(shè)在樣本數(shù)據(jù)集 D 中�����,混有 c 種類別的數(shù)據(jù)�。構(gòu)建決策樹時���,根據(jù)給定的樣本數(shù)據(jù)集選擇某個特征值作為樹的節(jié)點。
在數(shù)據(jù)集中�����,可以計算出該數(shù)據(jù)中的信息熵:其中 D 表示訓(xùn)練數(shù)據(jù)集���,c 表示數(shù)據(jù)類別數(shù)����,Pi 表示類別 i 樣本數(shù)量占所有樣本的比例。
作用前的信息熵公式
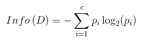
對應(yīng)數(shù)據(jù)集 D�,選擇特征 A 作為決策樹判斷節(jié)點時,在特征 A 作用后的信息熵的為 Info(D)���,其中 k 表示樣本 D 被分為 k 個部分��。
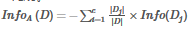
信息增益表示數(shù)據(jù)集 D 在特征 A 的作用后�����,其信息熵減少的值
Gain\left ( A \right )=Info\left ( D \right ) - Info_{A}\left ( D \right )
對于決策樹節(jié)點最合適的特征選擇�,就是 Gain(A) 值最大的特征�����。
基尼指數(shù)
對于給定的樣本集合D��, c 表示數(shù)據(jù)集中類別的數(shù)量����,Pi 表示類別 i 樣
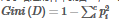
選取的屬性為 A�����,那么分裂后的數(shù)據(jù)集 D 的基尼指數(shù)的計算公式,其中 k 表示樣本 D 被分為 k 個部分,數(shù)據(jù)集 D 分裂成為 k 個 Dj 數(shù)據(jù)集�。
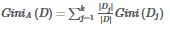
對于特征選取,需要選擇最小的分裂后的基尼指數(shù)���。也可以用基尼指數(shù)增益值作為決策樹選擇特征的依據(jù)
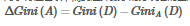
R語言實現(xiàn)決策樹算法
實現(xiàn)決策樹算法之前首先確保自己已經(jīng)安裝了所需相應(yīng)的語言包��。安裝方法有兩種。
方法一:使用 install.packages( ) ,括號內(nèi)填寫要安裝的包�。例如
install.packages("rpart")
方法二:自己在官網(wǎng)下載好語言包��,手動安裝���。使用方法一安裝時��,如果自己安裝的R的版本過低���,而R在執(zhí)行 install.packages( )命令時,會自動下載最新版本���,可能與計算機(jī)上安裝的R的版本不符合��,導(dǎo)致運行不成功等問題�����,這時需要自己去官網(wǎng)上下載與本機(jī)上R版本相符的語言包進(jìn)行安裝����。安裝方法如下:

點擊按鍵,彈出頁面
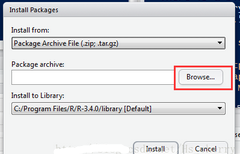
點擊browse���,瀏覽你所保存的r語言包�����,選中后���,點擊install,即可安裝�����。
使用rpart包
# 導(dǎo)入構(gòu)建決策樹所需要的庫
library("rpart")
library("rpart.plot")
library("survival")
#--------------------------------------------------------------------------#
# A查看本次構(gòu)建決策樹所用的數(shù)據(jù)源 stagec
stagec
# 通過 rpart 函數(shù)構(gòu)建決策樹
fit <- rpart(Surv(pgtime,pgstat)~age+eet+g2+grade+gleason+ploidy,stagec,method="exp")
# 查看決策樹的具體信息
print(fit)
printcp(fit)
# 繪制構(gòu)建完的決策樹圖
plot(fit, uniform=T, branch=0.6, compress=T)
text(fit, use.n=T)
# 通過 prune 函數(shù)剪枝
fit2 <- prune(fit, cp=0.016)
# 繪制剪枝完后的決策樹圖
plot(fit2, uniform=T, branch=0.6, compress=T)
text(fit2, use.n=T)
#-------------------------------------------------------------------------#
#B(rpart包)使用TH.data包中的bodyfat數(shù)據(jù)集
str(TH.data::bodyfat)
dim(TH.data::bodyfat)
head(TH.data::bodyfat)
# 分別選取訓(xùn)練樣本(70%)和測試樣本(30%)
set.seed(1234)
indexa <- sample(2,nrow(TH.data::bodyfat),replace = TRUE,prob=c(0.7,0.3))
bodyfat_train <- TH.data::bodyfat[indexa==1,]
bodyfat_test <- TH.data::bodyfat[indexa==2,]
# 使用age���、waistcirc等五個變量進(jìn)行決策樹分類
myFormulaa <- DEXfat ~ age + waistcirc + hipcirc + elbowbreadth + kneebreadth
# minsplit為最小分支節(jié)點數(shù)
bodyfat_rpart <- rpart(myFormulaa, data = bodyfat_train, control = rpart.control(minsplit = 10))
# cptable: a matrix of information on the optimal prunings based on a complexity parameter.
print(bodyfat_rpart$cptable)
# 輸出具體的決策樹模型結(jié)果
bodyfat_rpart
# 可視化展示
rpart.plot::rpart.plot(bodyfat_rpart)
# 對決策樹進(jìn)行剪枝處理(prune)��,防止過度擬合
opt <- which.min(bodyfat_rpart$cptable[,"xerror"])
cp <- bodyfat_rpart$cptable[opt, "CP"]
bodyfat_prune <- prune(bodyfat_rpart, cp = cp)
plot(bodyfat_prune)
text(bodyfat_prune,use.n=T)
# 使用調(diào)整過后的決策樹進(jìn)行預(yù)測
DEXfat_pred <- predict(bodyfat_prune, newdata=bodyfat_test)
xlim <- range(TH.data::bodyfat$DEXfat)
plot(DEXfat_pred ~ DEXfat, data=bodyfat_test, xlab="Observed", ylab="Predicted", ylim=xlim, xlim=xlim)
# 為圖形添加回歸線����,點的分布越靠近該線,則表示使用算法預(yù)測的精度越高
abline(a=0,b=1)
使用party包
# 載入所用的包�����,使用ctree()函數(shù)
library(party)
#本次構(gòu)建決策樹所用的數(shù)據(jù)源 iris
str(iris)
set.seed(1234)
#分別選取訓(xùn)練樣本(70%)和測試樣本(30%)
indexb <- sample(2, nrow(iris), replace = TRUE, prob = c(0.7,0.3))
traindata <- iris[indexb == 1,]
testdata <- iris[indexb == 2,]
# 構(gòu)建模型
myFormulab <- Species ~ Sepal.Length + Sepal.Width + Petal.Length + Petal.Width
iris_ctree <- ctree(myFormulab, data=traindata)
# 決策樹模型的判斷結(jié)果
table(predict(iris_ctree), traindata$Species)
# 輸出具體的決策樹模型結(jié)果
print(iris_ctree)
# 可視化展示
plot(iris_ctree)
plot(iris_ctree,type='simple')
# predict on test data
testpred <- predict(iris_ctree,newdata=testdata)
table(testpred,testdata$Species)
CDA數(shù)據(jù)分析師考試相關(guān)入口一覽(建議收藏):
? 想報名CDA認(rèn)證考試����,點擊>>>
“CDA報名”
了解CDA考試詳情;
? 想學(xué)習(xí)CDA考試教材��,點擊>>> “CDA教材” 了解CDA考試詳情��;
? 想加入CDA考試題庫���,點擊>>> “CDA題庫” 了解CDA考試詳情;
? 想了解CDA考試含金量�,點擊>>> “CDA含金量” 了解CDA考試詳情;











 京公網(wǎng)安備 11010802034615號
經(jīng)營許可證編號:京B2-20210330
京公網(wǎng)安備 11010802034615號
經(jīng)營許可證編號:京B2-20210330