四種聚類方法之比較
介紹了較為常見的k-means���、層次聚類�、SOM�、FCM等四種聚類算法,闡述了各自的原理和使用步驟�,利用國際通用測試數(shù)據(jù)集IRIS對這些算法進(jìn)行了驗(yàn)證和比較。結(jié)果顯示對該測試類型數(shù)據(jù)��,F(xiàn)CM和k-means都具有較高的準(zhǔn)確度,層次聚類準(zhǔn)確度最差����,而SOM則耗時(shí)最長�。
關(guān)鍵詞:聚類算法;k-means���;層次聚類�����;SOM���;FCM
聚類分析是一種重要的人類行為,早在孩提時(shí)代��,一個(gè)人就通過不斷改進(jìn)下意識中的聚類模式來學(xué)會(huì)如何區(qū)分貓狗��、動(dòng)物植物�。目前在許多領(lǐng)域都得到了廣泛的研究和成功的應(yīng)用,如用于模式識別�����、數(shù)據(jù)分析、圖像處理�、市場研究、客戶分割���、Web文檔分類等[1]�。
聚類就是按照某個(gè)特定標(biāo)準(zhǔn)(如距離準(zhǔn)則)把一個(gè)數(shù)據(jù)集分割成不同的類或簇�,使得同一個(gè)簇內(nèi)的數(shù)據(jù)對象的相似性盡可能大,同時(shí)不在同一個(gè)簇中的數(shù)據(jù)對象的差異性也盡可能地大��。即聚類后同一類的數(shù)據(jù)盡可能聚集到一起���,不同數(shù)據(jù)盡量分離����。
聚類技術(shù)[2]正在蓬勃發(fā)展�,對此有貢獻(xiàn)的研究領(lǐng)域包括數(shù)據(jù)挖掘、統(tǒng)計(jì)學(xué)�、機(jī)器學(xué)習(xí)、空間數(shù)據(jù)庫技術(shù)�����、生物學(xué)以及市場營銷等�����。各種聚類方法也被不斷提出和改進(jìn),而不同的方法適合于不同類型的數(shù)據(jù)�����,因此對各種聚類方法����、聚類效果的比較成為值得研究的課題�����。
1 聚類算法的分類
目前��,有大量的聚類算法[3]����。而對于具體應(yīng)用,聚類算法的選擇取決于數(shù)據(jù)的類型����、聚類的目的。如果聚類分析被用作描述或探查的工具�,可以對同樣的數(shù)據(jù)嘗試多種算法�����,以發(fā)現(xiàn)數(shù)據(jù)可能揭示的結(jié)果���。
主要的聚類算法可以劃分為如下幾類:劃分方法、層次方法�、基于密度的方法、基于網(wǎng)格的方法以及基于模型的方法[4-6]���。
每一類中都存在著得到廣泛應(yīng)用的算法�,例如:劃分方法中的k-means[7]聚類算法�、層次方法中的凝聚型層次聚類算法[8]、基于模型方法中的神經(jīng)網(wǎng)絡(luò)[9]聚類算法等����。
目前,聚類問題的研究不僅僅局限于上述的硬聚類,即每一個(gè)數(shù)據(jù)只能被歸為一類��,模糊聚類[10]也是聚類分析中研究較為廣泛的一個(gè)分支��。模糊聚類通過隸屬函數(shù)來確定每個(gè)數(shù)據(jù)隸屬于各個(gè)簇的程度���,而不是將一個(gè)數(shù)據(jù)對象硬性地歸類到某一簇中���。目前已有很多關(guān)于模糊聚類的算法被提出����,如著名的FCM算法等���。
本文主要對k-means聚類算法�����、凝聚型層次聚類算法�����、神經(jīng)網(wǎng)絡(luò)聚類算法之SOM,以及模糊聚類的FCM算法通過通用測試數(shù)據(jù)集進(jìn)行聚類效果的比較和分析��。
2 四種常用聚類算法研究
2.1 k-means聚類算法
k-means是劃分方法中較經(jīng)典的聚類算法之一�。由于該算法的效率高�,所以在對大規(guī)模數(shù)據(jù)進(jìn)行聚類時(shí)被廣泛應(yīng)用���。目前���,許多算法均圍繞著該算法進(jìn)行擴(kuò)展和改進(jìn)���。
k-means算法以k為參數(shù)�����,把n個(gè)對象分成k個(gè)簇,使簇內(nèi)具有較高的相似度����,而簇間的相似度較低�����。k-means算法的處理過程如下:首先����,隨機(jī)地選擇k個(gè)對象���,每個(gè)對象初始地代表了一個(gè)簇的平均值或中心;對剩余的每個(gè)對象�,根據(jù)其與各簇中心的距離�,將它賦給最近的簇;然后重新計(jì)算每個(gè)簇的平均值。這個(gè)過程不斷重復(fù)�,直到準(zhǔn)則函數(shù)收斂�。通常���,采用平方誤差準(zhǔn)則����,其定義如下:
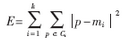
這里E是數(shù)據(jù)庫中所有對象的平方誤差的總和�����,p是空間中的點(diǎn)�����,mi是簇Ci的平均值[9]����。該目標(biāo)函數(shù)使生成的簇盡可能緊湊獨(dú)立����,使用的距離度量是歐幾里得距離,當(dāng)然也可以用其他距離度量���。k-means聚類算法的算法流程如下:
輸入:包含n個(gè)對象的數(shù)據(jù)庫和簇的數(shù)目k;
輸出:k個(gè)簇��,使平方誤差準(zhǔn)則最小��。
步驟:
(1) 任意選擇k個(gè)對象作為初始的簇中心��;
(2) repeat���;
(3) 根據(jù)簇中對象的平均值,將每個(gè)對象(重新)賦予最類似的簇;
(4) 更新簇的平均值��,即計(jì)算每個(gè)簇中對象的平均值�����;
(5) until不再發(fā)生變化�����。
2.2 層次聚類算法
根據(jù)層次分解的順序是自底向上的還是自上向下的,層次聚類算法分為凝聚的層次聚類算法和分裂的層次聚類算法��。
凝聚型層次聚類的策略是先將每個(gè)對象作為一個(gè)簇��,然后合并這些原子簇為越來越大的簇���,直到所有對象都在一個(gè)簇中�,或者某個(gè)終結(jié)條件被滿足�。絕大多數(shù)層次聚類屬于凝聚型層次聚類�,它們只是在簇間相似度的定義上有所不同。四種廣泛采用的簇間距離度量方法如下:

這里給出采用最小距離的凝聚層次聚類算法流程:
(1) 將每個(gè)對象看作一類����,計(jì)算兩兩之間的最小距離���;
(2) 將距離最小的兩個(gè)類合并成一個(gè)新類���;
(3) 重新計(jì)算新類與所有類之間的距離�����;
(4) 重復(fù)(2)、(3)��,直到所有類最后合并成一類。
2.3 SOM聚類算法
SOM神經(jīng)網(wǎng)絡(luò)[11]是由芬蘭神經(jīng)網(wǎng)絡(luò)專家Kohonen教授提出的,該算法假設(shè)在輸入對象中存在一些拓?fù)浣Y(jié)構(gòu)或順序,可以實(shí)現(xiàn)從輸入空間(n維)到輸出平面(2維)的降維映射,其映射具有拓?fù)?a href='/map/tezheng/' style='color:#000;font-size:inherit;'>特征保持性質(zhì),與實(shí)際的大腦處理有很強(qiáng)的理論聯(lián)系�。
SOM網(wǎng)絡(luò)包含輸入層和輸出層����。輸入層對應(yīng)一個(gè)高維的輸入向量,輸出層由一系列組織在2維網(wǎng)格上的有序節(jié)點(diǎn)構(gòu)成��,輸入節(jié)點(diǎn)與輸出節(jié)點(diǎn)通過權(quán)重向量連接���。學(xué)習(xí)過程中,找到與之距離最短的輸出層單元�����,即獲勝單元�����,對其更新���。同時(shí)�����,將鄰近區(qū)域的權(quán)值更新���,使輸出節(jié)點(diǎn)保持輸入向量的拓?fù)?a href='/map/tezheng/' style='color:#000;font-size:inherit;'>特征���。
算法流程:
(1) 網(wǎng)絡(luò)初始化,對輸出層每個(gè)節(jié)點(diǎn)權(quán)重賦初值�����;
(2) 將輸入樣本中隨機(jī)選取輸入向量���,找到與輸入向量距離最小的權(quán)重向量����;
(3) 定義獲勝單元���,在獲勝單元的鄰近區(qū)域調(diào)整權(quán)重使其向輸入向量靠攏����;
(4) 提供新樣本��、進(jìn)行訓(xùn)練;
(5) 收縮鄰域半徑��、減小學(xué)習(xí)率��、重復(fù)�����,直到小于允許值����,輸出聚類結(jié)果。
2.4 FCM聚類算法
1965年美國加州大學(xué)柏克萊分校的扎德教授第一次提出了‘集合’的概念�。經(jīng)過十多年的發(fā)展,模糊集合理論漸漸被應(yīng)用到各個(gè)實(shí)際應(yīng)用方面���。為克服非此即彼的分類缺點(diǎn),出現(xiàn)了以模糊集合論為數(shù)學(xué)基礎(chǔ)的聚類分析�����。用模糊數(shù)學(xué)的方法進(jìn)行聚類分析�,就是模糊聚類分析[12]。
FCM算法是一種以隸屬度來確定每個(gè)數(shù)據(jù)點(diǎn)屬于某個(gè)聚類程度的算法�����。該聚類算法是傳統(tǒng)硬聚類算法的一種改進(jìn)。

算法流程:
(1) 標(biāo)準(zhǔn)化數(shù)據(jù)矩陣��;
(2) 建立模糊相似矩陣��,初始化隸屬矩陣����;
(3) 算法開始迭代,直到目標(biāo)函數(shù)收斂到極小值���;
(4) 根據(jù)迭代結(jié)果��,由最后的隸屬矩陣確定數(shù)據(jù)所屬的類���,顯示最后的聚類結(jié)果。
3 四種聚類算法試驗(yàn)
3.1 試驗(yàn)數(shù)據(jù)
實(shí)驗(yàn)中�����,選取專門用于測試分類�、聚類算法的國際通用的UCI數(shù)據(jù)庫中的IRIS[13]數(shù)據(jù)集,IRIS數(shù)據(jù)集包含150個(gè)樣本數(shù)據(jù)�����,分別取自三種不同的鶯尾屬植物setosa、versicolor和virginica的花朵樣本,每個(gè)數(shù)據(jù)含有4個(gè)屬性��,即萼片長度�、萼片寬度、花瓣長度���,單位為cm���。在數(shù)據(jù)集上執(zhí)行不同的聚類算法,可以得到不同精度的聚類結(jié)果��。
3.2 試驗(yàn)結(jié)果說明
文中基于前面所述各算法原理及算法流程����,用matlab進(jìn)行編程運(yùn)算,得到表1所示聚類結(jié)果�����。
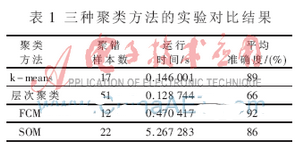
如表1所示���,對于四種聚類算法,按三方面進(jìn)行比較:(1)聚錯(cuò)樣本數(shù):總的聚錯(cuò)的樣本數(shù),即各類中聚錯(cuò)的樣本數(shù)的和��;(2)運(yùn)行時(shí)間:即聚類整個(gè)過程所耗費(fèi)的時(shí)間�����,單位為s���;(3)平均準(zhǔn)確度:設(shè)原數(shù)據(jù)集有k個(gè)類,用ci表示第i類�,ni為ci中樣本的個(gè)數(shù)���,mi為聚類正確的個(gè)數(shù),則mi/ni為第i類中的精度���,則平均精度為:
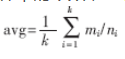
3.3 試驗(yàn)結(jié)果分析
四種聚類算法中,在運(yùn)行時(shí)間及準(zhǔn)確度方面綜合考慮�,k-means和FCM相對優(yōu)于其他。但是��,各個(gè)算法還是存在固定缺點(diǎn):k-means聚類算法的初始點(diǎn)選擇不穩(wěn)定�,是隨機(jī)選取的,這就引起聚類結(jié)果的不穩(wěn)定��,本實(shí)驗(yàn)中雖是經(jīng)過多次實(shí)驗(yàn)取的平均值���,但是具體初始點(diǎn)的選擇方法還需進(jìn)一步研究���;層次聚類雖然不需要確定分類數(shù)����,但是一旦一個(gè)分裂或者合并被執(zhí)行���,就不能修正��,聚類質(zhì)量受限制��;FCM對初始聚類中心敏感��,需要人為確定聚類數(shù)�,容易陷入局部最優(yōu)解�����;SOM與實(shí)際大腦處理有很強(qiáng)的理論聯(lián)系����。但是處理時(shí)間較長��,需要進(jìn)一步研究使其適應(yīng)大型數(shù)據(jù)庫。
聚類分析因其在許多領(lǐng)域的成功應(yīng)用而展現(xiàn)出誘人的應(yīng)用前景���,除經(jīng)典聚類算法外��,各種新的聚類方法正被不斷被提出����。
CDA數(shù)據(jù)分析師考試相關(guān)入口一覽(建議收藏):
? 想報(bào)名CDA認(rèn)證考試����,點(diǎn)擊>>>
“CDA報(bào)名”
了解CDA考試詳情;
? 想學(xué)習(xí)CDA考試教材����,點(diǎn)擊>>> “CDA教材” 了解CDA考試詳情;
? 想加入CDA考試題庫����,點(diǎn)擊>>> “CDA題庫” 了解CDA考試詳情;
? 想了解CDA考試含金量����,點(diǎn)擊>>> “CDA含金量” 了解CDA考試詳情;











 京公網(wǎng)安備 11010802034615號
經(jīng)營許可證編號:京B2-20210330
京公網(wǎng)安備 11010802034615號
經(jīng)營許可證編號:京B2-20210330