R語言建立VAR模型分析聯(lián)合內(nèi)生變量的動態(tài)關(guān)系
最近在寫向量自回歸的論文,無論是百度還是Google����,都沒能找到特別合適的R環(huán)境下中文資料����,大都是Eviews做出來的。所以寫這么一篇blog來分享下自己的經(jīng)驗���。
注:本文著重介紹VAR的R實現(xiàn)�,具體學(xué)術(shù)性質(zhì)的東西請參閱相關(guān)學(xué)術(shù)論文����。
VAR的定義:
自行Google,很詳細,也很簡單
VAR模型的用途:
主要是預(yù)測分析和內(nèi)生變量間影響狀況分析����。
VAR的主要步驟:
(個人拙見,不是標準模板)
選擇合適的變量
Granger因果檢驗�,進一步觀察變量間的關(guān)聯(lián)性,最好做雙向檢驗���,不過也有人說單向就足夠了����,這就人之間人智者見智了
選擇VAR模型滯后階數(shù)
擬合VAR模型
診斷性檢驗:包括系統(tǒng)平穩(wěn)性檢驗�����、正態(tài)性檢驗����、序列相關(guān)誤差等
脈沖響應(yīng)分析
方差分解
預(yù)測分析
各個步驟在R中的實現(xiàn)方法:
R中有個叫“vars”的package,主要用來做向量自回歸分析���,所以先安裝并加載該包:
install.packages(vars)
library(vars)
1.選擇變量
根據(jù)理論分析選擇出相關(guān)聯(lián)的變量����,不多說。
2.Granger因果檢驗
vars包里面有個專門做格蘭杰因果檢驗的函數(shù):
causality(x, cause = NULL, vcov.=NULL, boot=FALSE, boot.runs=100)
另外還有一個適用于普通線性回歸模型的Granger test的函數(shù):
grangertest(x, y, order = 1, na.action = na.omit, ...)
這兩個函數(shù)最直接的區(qū)別在于��,第二個不用擬合VAR模型即可使用��,而第一個必須在擬合VAR模型之后使用��。
3.選擇合適的滯后階數(shù)
沒有一個定論�,主要是通過不同信息準則選擇出合適的結(jié)果,且最好選擇最簡階數(shù)(也就是最低階數(shù))��。
相關(guān)函數(shù):
VARselect(y, lag.max = 10, type = c("const", "trend", "both", "none"),
season = NULL, exogen = NULL)
函數(shù)會return一個結(jié)果��,分別是根據(jù)AIC��、HQ��、SC�、FPE四個信息準則得出的最優(yōu)階數(shù)����。
4.擬合VAR模型
var(x, y = NULL, na.rm = FALSE, use)
5.診斷性檢驗
也就是檢驗?zāi)P偷挠行浴?br />
系統(tǒng)平穩(wěn)性:
stability(x, type = c("OLS-CUSUM", "Rec-CUSUM", "Rec-MOSUM",
"OLS-MOSUM", "RE", "ME", "Score-CUSUM", "Score-MOSUM",
"fluctuation"), h = 0.15, dynamic = FALSE, rescale = TRUE)
這里使用“OLS-CUSUM”,它給出的是殘差累積和�,在該檢驗生成的曲線圖中,殘差累積和曲線以時間為橫坐標����,圖中繪出兩條臨界線��,如果累積和超出了這兩條臨界線����,則說明參數(shù)不具有穩(wěn)定性�����。
結(jié)果如下圖:
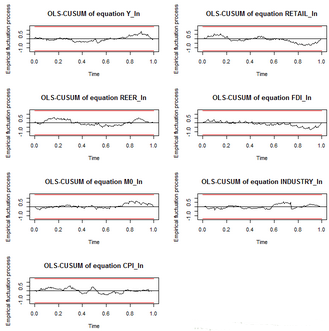
說明系統(tǒng)穩(wěn)定�。
正態(tài)性檢驗:
normality.test(x, multivariate.only = TRUE)
序列相關(guān)誤差檢驗:
serial.test(x, lags.pt = 16, lags.bg = 5, type = c("PT.asymptotic",
"PT.adjusted", "BG", "ES") )
6.脈沖響應(yīng)分析
脈沖響應(yīng)分析,直白的來說就是對于某一內(nèi)生變量對于殘差沖擊的反應(yīng)��。具體而言��,他描述的是在隨機誤差項上施加一個標準差大小的沖擊后對內(nèi)生變量的當(dāng)期值和未來值所產(chǎn)生的影響�����。
irf(x, impulse = NULL, response = NULL, n.ahead = 10,
ortho = TRUE, cumulative = FALSE, boot = TRUE, ci = 0.95,
runs = 100, seed = NULL, ...)
示例:
var<-VAR(timeseries,lag.max=2)
var.irf<-irf(var)
plot(var.irf)
結(jié)果:
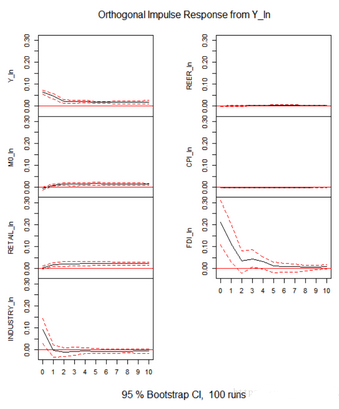
解讀:
標題欄說明�,這是Y_ln對各個變量(包括Y_ln自身)的脈沖響應(yīng)(impulse response),其中可以看出來自Y_ln的正向沖擊�����,來自FDI_ln的正向沖擊、來自INDUSTRY_ln的沖擊不斷減小到負向����。其余變量的沖擊較小。
7.方差分解
VAR模型的應(yīng)用�,還可以采用方差分解方法研究模型的動態(tài)特征。方差分解是進一步評價各內(nèi)生變量對預(yù)測方差的貢獻度���。方差分解是分析預(yù)測殘差的標準差由不同新息的沖擊影響的比例�����,亦即對應(yīng)內(nèi)生變量對標準差的貢獻比例�����。
fevd(x, n.ahead=10, ...)
示例:
var<-VAR(timeseries,lag.max=2)
fevd1<-fevd(var, n.ahead = 5)$Y_ln
結(jié)果:
Y_ln REER_ln M0_ln CPI_ln RETAIL_ln FDI_ln INDUSTRY_ln
[1,] 1.0000000 0.000000000 0.0000000 0.00000000 0.00000000 0.00000000 0.00000000
[2,] 0.5660281 0.004363083 0.3085364 0.01686071 0.01356081 0.06509447 0.02555642
[3,] 0.5411924 0.009721985 0.2755711 0.01899613 0.07313395 0.05837871 0.02300568
[4,] 0.5259530 0.020262020 0.2783238 0.01870045 0.06689414 0.06883620 0.02103032
[5,] 0.5268243 0.036825419 0.2697744 0.01855353 0.06276992 0.06550223 0.01975014
解讀:
例子中選取的是Y_ln變量的方差分解結(jié)果����,如果不加‘$Y_ln’�,則會return全部變量的結(jié)果�����。
最左邊的是滯后期數(shù),一共5期�����,結(jié)果表明當(dāng)滯后期為1時�����,其自身對預(yù)測方差的貢獻率為100%�����,用人話講就是自身其變化�。隨著滯后期增加,Y_ln的貢獻率下降���,其他變量逐漸增加����。不管怎么變化��,每一行(也就是每一期)各個變量的貢獻率之和都為1����。
8.模型預(yù)測
沒什么好說的��,舉例示之��。
var.predict<-predict(var,n.ahead=3,ci=0.95)
var.predict
結(jié)果:
$Y_ln
fcst lower upper CI
[1,] 8.335729 8.208656 8.462802 0.1270727
[2,] 8.284560 8.076325 8.492795 0.2082349
[3,] 8.299723 8.078930 8.520516 0.2207930
fcst:點估計值
lower:區(qū)間估計下界
upper:區(qū)間估計上界
CI:置信區(qū)間
9.預(yù)測結(jié)果可視化
除了直接使用plot()函數(shù)繪圖以外���,vars包有一個fanchart()函數(shù)可以繪制扇形圖,示意圖:
總結(jié):以上內(nèi)容基本上實現(xiàn)了建立向量自回歸模型�,并進行分析所需的主要功能。至于更細分的點��,就需要具體問題具體分析了���。如文中有任何錯誤�����,請及時留言�,謝謝
CDA數(shù)據(jù)分析師考試相關(guān)入口一覽(建議收藏):
? 想報名CDA認證考試�����,點擊>>>
“CDA報名”
了解CDA考試詳情���;
? 想學(xué)習(xí)CDA考試教材��,點擊>>> “CDA教材” 了解CDA考試詳情���;
? 想加入CDA考試題庫,點擊>>> “CDA題庫” 了解CDA考試詳情���;
? 想了解CDA考試含金量�,點擊>>> “CDA含金量” 了解CDA考試詳情��;











 京公網(wǎng)安備 11010802034615號
經(jīng)營許可證編號:京B2-20210330
京公網(wǎng)安備 11010802034615號
經(jīng)營許可證編號:京B2-20210330