用R語言進(jìn)行關(guān)聯(lián)分析
關(guān)聯(lián)是兩個(gè)或多個(gè)變量取值之間存在的一類重要的可被發(fā)現(xiàn)的某種規(guī)律性�����。關(guān)聯(lián)分析目的是尋找給定數(shù)據(jù)記錄集中數(shù)據(jù)項(xiàng)之間隱藏的關(guān)聯(lián)關(guān)系�,描述數(shù)據(jù)之間的密切度�����。
幾個(gè)基本概念
1. 項(xiàng)集
這是一個(gè)集合的概念,在一籃子商品中的一件消費(fèi)品即為一項(xiàng)(Item)����,則若干項(xiàng)的集合為項(xiàng)集��,如{啤酒�,尿布}構(gòu)成一個(gè)二元項(xiàng)集。
2. 關(guān)聯(lián)規(guī)則
一般記為的形式���,X為先決條件���,Y為相應(yīng)的關(guān)聯(lián)結(jié)果,用于表示數(shù)據(jù)內(nèi)隱含的關(guān)聯(lián)性��。如:�����,表示購買了尿布的消費(fèi)者往往也會購買啤酒����。
關(guān)聯(lián)性強(qiáng)度如何���,由三個(gè)概念——支持度、置信度����、提升度來控制和評價(jià)。
例:有10000個(gè)消費(fèi)者購買了商品����,其中購買尿布1000個(gè),購買啤酒2000個(gè)����,購買面包500個(gè),同時(shí)購買尿布和面包800個(gè)�,同時(shí)購買尿布和面包100個(gè)。
3. 支持度(Support)
支持度是指在所有項(xiàng)集中{X, Y}出現(xiàn)的可能性��,即項(xiàng)集中同時(shí)含有X和Y的概率:
該指標(biāo)作為建立強(qiáng)關(guān)聯(lián)規(guī)則的第一個(gè)門檻�,衡量了所考察關(guān)聯(lián)規(guī)則在“量”上的多少。通過設(shè)定最小閾值(minsup)���,剔除“出鏡率”較低的無意義規(guī)則��,保留出現(xiàn)較為頻繁的項(xiàng)集所隱含的規(guī)則���。
設(shè)定最小閾值為5%���,由于{尿布,啤酒}的支持度為800/10000=8%���,滿足基本輸了要求����,成為頻繁項(xiàng)集���,保留規(guī)則;而{尿布�,面包}的支持度為100/10000=1%,被剔除�����。
4. 置信度(Confidence)
置信度表示在先決條件X發(fā)生的條件下����,關(guān)聯(lián)結(jié)果Y發(fā)生的概率:
這是生成強(qiáng)關(guān)聯(lián)規(guī)則的第二個(gè)門檻,衡量了所考察的關(guān)聯(lián)規(guī)則在“質(zhì)”上的可靠性���。相似的���,我們需要對置信度設(shè)定最小閾值(mincon)來實(shí)現(xiàn)進(jìn)一步篩選�����。
具體的�����,當(dāng)設(shè)定置信度的最小閾值為70%時(shí)�,置信度為800/1000=80%��,而的置信度為800/2000=40%�����,被剔除���。
5. 提升度(lift)
提升度表示在含有X的條件下同時(shí)含有Y的可能性與沒有X這個(gè)條件下項(xiàng)集中含有Y的可能性之比:
該指標(biāo)與置信度同樣衡量規(guī)則的可靠性����,可以看作是置信度的一種互補(bǔ)指標(biāo)。
R中Apriori算法
算法步驟:
1. 選出滿足支持度最小閾值的所有項(xiàng)集��,即頻繁項(xiàng)集�����;
2. 從頻繁項(xiàng)集中找出滿足最小置信度的所有規(guī)則����。
> library(arules) #加載arules包
> click_detail =read.transactions("click_detail.txt",format="basket",sep=",",cols=c(1)) #讀取txt文檔(文檔編碼為ANSI)
> rules <- apriori(click_detail, parameter =list(supp=0.01,conf=0.5,target="rules")) #調(diào)用apriori算法
> rules
set of419 rules
> inspect(rules[1:10]) #查看前十條規(guī)則
解釋
1) library(arules):加載程序包arules,當(dāng)然如果你前面沒有下載過這個(gè)包���,就要先install.packages(arules)
2) click_detail =read.transactions("click_detail.txt",format="basket",sep=",",cols=c(1)):讀入數(shù)據(jù)
read.transactions(file, format =c("basket", "single"), sep = NULL,
cols = NULL, rm.duplicates =FALSE, encoding = "unknown")
file:文件名�,對應(yīng)click_detail中的“click_detail.txt”
format:文件格式���,可以有兩種,分別為“basket”,“single”�����,click_detail.txt中用的是basket����。
basket: basket就是籃子,一個(gè)顧客買的東西都放到同一個(gè)籃子,所有顧客的transactions就是一個(gè)個(gè)籃子的組合結(jié)果���。如下形式�����,每條交易都是獨(dú)立的��。
文件形式:
item1,item2
item1
item2,item3
讀入后:
items
1 {item1,
item2}
2 {item1}
3 {item2,
item3}
single: single的意思��,顧名思義����,就是單獨(dú)的交易�����,簡單說��,交易記錄為:顧客1買了產(chǎn)品1�, 顧客1買了產(chǎn)品2,顧客2買了產(chǎn)品3……(產(chǎn)品1��,產(chǎn)品2�,產(chǎn)品3中可以是單個(gè)產(chǎn)品����,也可以是多個(gè)產(chǎn)品)�,如下形式:
trans1 item1
trans2 item1
trans2 item2
讀入后:
items transactionID
1 {item1} trans1
2 {item1,
item2} trans2
sep:文件中數(shù)據(jù)是怎么被分隔的,默認(rèn)為空格���,click_detail里面用逗號分隔
cols:對basket, col=1,表示第一列是數(shù)據(jù)的transaction ids(交易號)���,如果col=NULL,則表示數(shù)據(jù)里面沒有交易號這一列��;對single�����,col=c(1,2)表示第一列是transaction
ids���,第二列是item ids
rm.duplicates:是否移除重復(fù)項(xiàng),默認(rèn)為FALSE
encoding:寫到這里研究了encoding是什么意思���,發(fā)現(xiàn)前面txt可以不是”ANSI”類型�����,如果TXT是“UTF-8”�����,寫encoding=”UTF-8”���,就OK了.
3) rules <- apriori(click_detail,parameter = list(supp=0.01,conf=0.5,target="rules")):apriori函數(shù)
apriori(data, parameter = NULL, appearance = NULL, control = NULL)
data:數(shù)據(jù)
parameter:設(shè)置參數(shù)��,默認(rèn)情況下parameter=list(supp=0.1,conf=0.8,maxlen=10,minlen=1,target=”rules”)
supp:支持度(support)
conf:置信度(confidence)
maxlen,minlen:每個(gè)項(xiàng)集所含項(xiàng)數(shù)的最大最小值
target:“rules”或“frequent itemsets”(輸出關(guān)聯(lián)規(guī)則/頻繁項(xiàng)集)
apperence:對先決條件X(lhs)����,關(guān)聯(lián)結(jié)果Y(rhs)中具體包含哪些項(xiàng)進(jìn)行限制��,如:設(shè)置lhs=beer��,將僅輸出lhs含有beer這一項(xiàng)的關(guān)聯(lián)規(guī)則����。默認(rèn)情況下,所有項(xiàng)都將無限制出現(xiàn)����。
control:控制函數(shù)性能,如可以設(shè)定對項(xiàng)集進(jìn)行升序sort=1或降序sort=-1排序����,是否向使用者報(bào)告進(jìn)程(verbose=F/T)
補(bǔ)充
通過支持度控制:rules.sorted_sup = sort(rules, by=”support”)
通過置信度控制:rules.sorted_con = sort(rules, by=”confidence”)
通過提升度控制:rules.sorted_lift = sort(rules, by=”lift”)
Apriori算法
兩步法:
1. 頻繁項(xiàng)集的產(chǎn)生:找出所有滿足最小支持度閾值的項(xiàng)集����,稱為頻繁項(xiàng)集�;
2. 規(guī)則的產(chǎn)生:對于每一個(gè)頻繁項(xiàng)集l,找出其中所有的非空子集�;然后,對于每一個(gè)這樣的子集a�����,如果support(l)與support(a)的比值大于最小可信度�,則存在規(guī)則a==>(l-a)。
頻繁項(xiàng)集產(chǎn)生所需要的計(jì)算開銷遠(yuǎn)大于規(guī)則產(chǎn)生所需的計(jì)算開銷
頻繁項(xiàng)集的產(chǎn)生
幾個(gè)概念:
1����, 一個(gè)包含K個(gè)項(xiàng)的數(shù)據(jù)集,可能產(chǎn)生2^k個(gè)候選集

2��,先驗(yàn)原理:如果一個(gè)項(xiàng)集是頻繁的�����,則它的所有子集也是頻繁的(理解了頻繁項(xiàng)集的意義���,這句話很容易理解的)����;相反��,如果一個(gè)項(xiàng)集是非頻繁的�����,則它所有子集也一定是非頻繁的����。
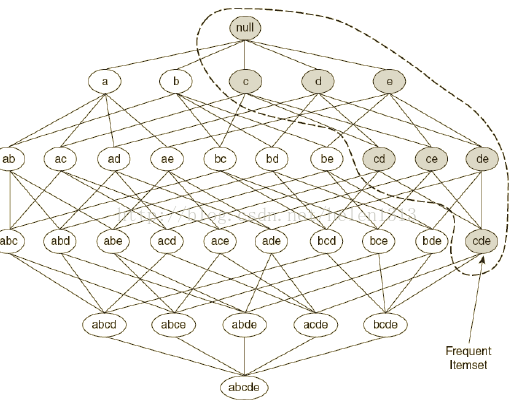
3基于支持度(SUPPORT)度量的一個(gè)關(guān)鍵性質(zhì):一個(gè)項(xiàng)集的支持度不會超過它的子集的支持度(很好理解,支持度是共同發(fā)生的概率����,假設(shè)項(xiàng)集{A,B,C},{A,B}是它的一個(gè)自己�����,A,B,C同時(shí)發(fā)生的概率肯定不會超過A,B同時(shí)發(fā)生的概率)�。
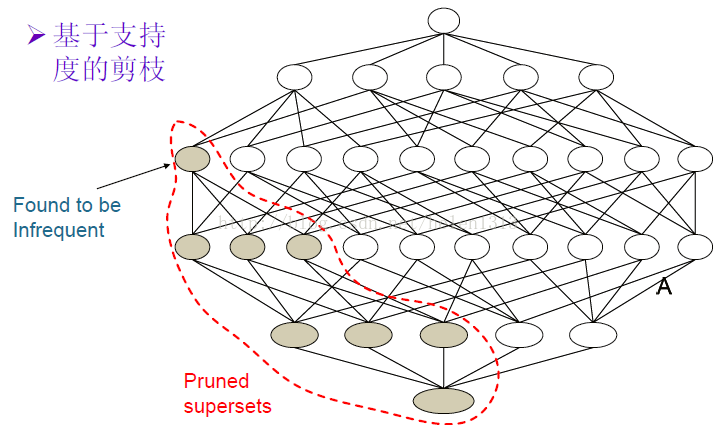
上面這條規(guī)則就是Apriori中使用到的,如下圖����,當(dāng)尋找頻繁項(xiàng)集時(shí)�,從上往下掃描��,當(dāng)遇到一個(gè)項(xiàng)集是非頻繁項(xiàng)集(該項(xiàng)集支持度小于Minsup)�����,那么它下面的項(xiàng)集肯定就是非頻繁項(xiàng)集�����,這一部分就剪枝掉了��。
一個(gè)例子(百度到的一個(gè)PPT上的):
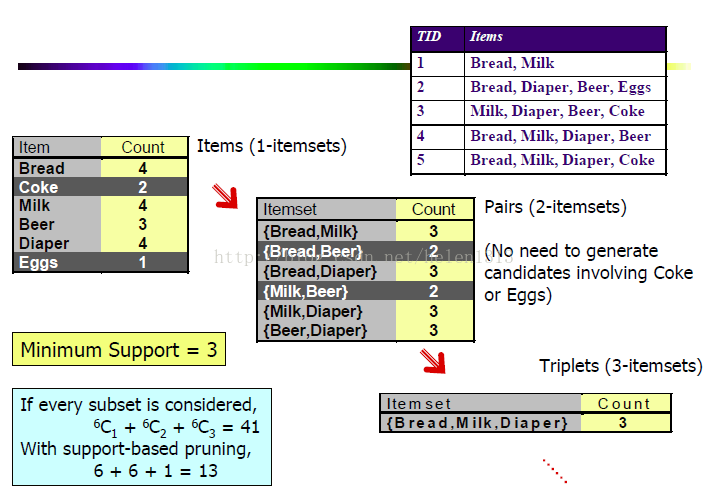
當(dāng)我在理解頻繁項(xiàng)集的意義時(shí)���,在R上簡單的復(fù)現(xiàn)了這個(gè)例子����,這里采用了eclat算法��,跟apriori應(yīng)該差不多:
代碼:
item <- list(
c("bread","milk"),
c("bread","diaper","beer","eggs"),
c("milk","diaper","beer","coke"),
c("bread","milk","diaper","beer"),
c("bread","milk","diaper","coke")
)
names(item) <- paste("tr",c(1:5),sep = "")
item
trans <- as(item,"transactions") #將List轉(zhuǎn)為transactions型
rules = eclat(trans,parameter = list(supp = 0.6,
target ="frequent itemsets"),control = list(sort=1))
inspect(rules) #查看頻繁項(xiàng)集
運(yùn)行后結(jié)果:
>inspect(rules)
items support
1{beer,
diaper} 0.6
2{diaper,
milk} 0.6
3{bread,
diaper} 0.6
4{bread,
milk} 0.6
5{beer} 0.6
6{milk} 0.8
7{bread} 0.8
8{diaper} 0.8
以上就是該例子的所有頻繁項(xiàng)集��,然后我發(fā)現(xiàn)少了{(lán)bread,milk,diaper}這個(gè)項(xiàng)集,回到例子一看���,這個(gè)項(xiàng)集實(shí)際上只出現(xiàn)了兩次,所以是沒有這個(gè)項(xiàng)集的���。
規(guī)則的產(chǎn)生
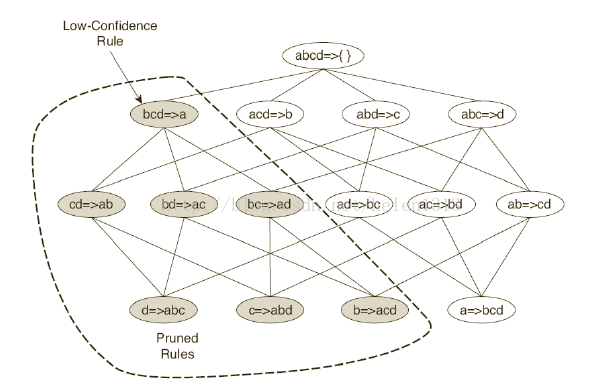
每個(gè)頻繁k項(xiàng)集能產(chǎn)生最多2k-2個(gè)關(guān)聯(lián)規(guī)則
將項(xiàng)集Y劃分成兩個(gè)非空的子集X和Y-X�,使得X ->Y-X滿足置信度閾值
定理:如果規(guī)則X->Y-X不滿足置信度閾值��,則X’->Y-X’的規(guī)則一定也不滿足置信度閾值��,其中X’是X的子集
Apriori按下圖進(jìn)行逐層計(jì)算���,當(dāng)發(fā)現(xiàn)一個(gè)不滿足置信度的項(xiàng)集后���,該項(xiàng)集所有子集的規(guī)則都可以剪枝掉了。
CDA數(shù)據(jù)分析師考試相關(guān)入口一覽(建議收藏):
? 想報(bào)名CDA認(rèn)證考試�����,點(diǎn)擊>>>
“CDA報(bào)名”
了解CDA考試詳情��;
? 想學(xué)習(xí)CDA考試教材����,點(diǎn)擊>>> “CDA教材” 了解CDA考試詳情�;
? 想加入CDA考試題庫�,點(diǎn)擊>>> “CDA題庫” 了解CDA考試詳情;
? 想了解CDA考試含金量��,點(diǎn)擊>>> “CDA含金量” 了解CDA考試詳情���;











 京公網(wǎng)安備 11010802034615號
經(jīng)營許可證編號:京B2-20210330
京公網(wǎng)安備 11010802034615號
經(jīng)營許可證編號:京B2-20210330