R語(yǔ)言深度學(xué)習(xí)不同模型對(duì)比分析案例
深度學(xué)習(xí)是機(jī)器學(xué)習(xí)最近的一個(gè)趨勢(shì),模擬高度非線性的數(shù)據(jù)表示����。在過(guò)去的幾年中,深度學(xué)習(xí)在各種應(yīng)用中獲得了巨大的發(fā)展勢(shì)頭(Wikipedia
2016a)����。其中包括圖像和語(yǔ)音識(shí)別,無(wú)人駕駛汽車���,自然語(yǔ)言處理等等��。有趣的是�,深度學(xué)習(xí)的大部分?jǐn)?shù)學(xué)概念已經(jīng)被認(rèn)識(shí)了幾十年。然而���,只有通過(guò)最近的一些發(fā)展,深度學(xué)習(xí)的全部潛力才得以釋放(Nair
and Hinton�,2010; Srivastava et al。����,2014)。
以前���,由于梯度消失和過(guò)度配合問(wèn)題��,很難訓(xùn)練人工神經(jīng)網(wǎng)絡(luò)?��,F(xiàn)在,這兩個(gè)問(wèn)題都可以通過(guò)使用不同的激活函數(shù)�,輟學(xué)正則化和大量的訓(xùn)練數(shù)據(jù)來(lái)解決。例如����,互聯(lián)網(wǎng)現(xiàn)在可以用來(lái)檢索大量的有標(biāo)簽和無(wú)標(biāo)簽的數(shù)據(jù)�����。另外�����,GPU和GPGPU的可用性使得計(jì)算更便宜和更快���。
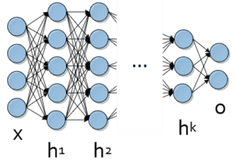
今天,深度學(xué)習(xí)對(duì)于幾乎所有需要機(jī)器學(xué)習(xí)的任務(wù)都是非常有效的���。但是��,它特別適合復(fù)雜的分層數(shù)據(jù)���。其潛在的人工神經(jīng)網(wǎng)絡(luò)模型高度非線性表示; 這些通常由多層結(jié)合非線性轉(zhuǎn)換和定制架構(gòu)組成。圖1描述了一個(gè)深度神經(jīng)網(wǎng)絡(luò)的典型表示���。
圖1.深度神經(jīng)網(wǎng)絡(luò)的模型
深度學(xué)習(xí)的成功帶來(lái)了各種編程語(yǔ)言的各種框架和庫(kù)����。例子包括Caffee,Theano���,Torch和Tensor Flow等等��。這篇博客文章的目的是為編程語(yǔ)言R提供不同深度學(xué)習(xí)軟件包的概述和比較��。我們比較不同數(shù)據(jù)集的性能和易用性�。
R學(xué)習(xí)套裝
R編程語(yǔ)言在統(tǒng)計(jì)人員和數(shù)據(jù)挖掘人員之間的易用性以及復(fù)雜的可視化和分析方面已經(jīng)獲得了相當(dāng)?shù)钠占?���。隨著深度學(xué)習(xí)時(shí)代的到來(lái)�,對(duì)R的深度學(xué)習(xí)的支持不斷增長(zhǎng),隨著越來(lái)越多的軟件包的推出�����,本節(jié)提供以下軟件包提供的有關(guān)深度學(xué)習(xí)的概述:MXNetR���,darch�,deepnet��,H2O和deepr�����。
首先,我們注意到��,從一個(gè)包到另一個(gè)包的底層學(xué)習(xí)算法有很大的不同���。同樣����,表1顯示了每個(gè)軟件包中可用方法/體系結(jié)構(gòu)的列表����。
表1. R包中可用的深度學(xué)習(xí)方法列表。
包神經(jīng)網(wǎng)絡(luò)的可用體系結(jié)構(gòu)
MXNetR前饋神經(jīng)網(wǎng)絡(luò)�����,卷積神經(jīng)網(wǎng)絡(luò)(CNN)
達(dá)奇限制玻爾茲曼機(jī)�����,深層信念網(wǎng)絡(luò)
DEEPNET前饋神經(jīng)網(wǎng)絡(luò)��,受限玻爾茲曼機(jī)器,深層信念網(wǎng)絡(luò)�,堆棧自動(dòng)編碼器
H2O前饋神經(jīng)網(wǎng)絡(luò),深度自動(dòng)編碼器
deepr從H2O和深網(wǎng)包中簡(jiǎn)化一些功能
包“MXNetR”
MXNetR包是用C ++編寫的MXNet庫(kù)的接口����。它包含前饋神經(jīng)網(wǎng)絡(luò)和卷積神經(jīng)網(wǎng)絡(luò)(CNN)(MXNetR
2016a)。它也允許人們構(gòu)建定制的模型����。該軟件包分為兩個(gè)版本:僅限CPU或GPU版本。以前的CPU版本可以直接從R內(nèi)部直接安裝�,而后者的GPU版本依賴于第三方庫(kù)(如cuDNN),并需要從其源代碼(MXNetR
2016b)中構(gòu)建庫(kù)�����。
前饋神經(jīng)網(wǎng)絡(luò)(多層感知器)可以在MXNetR中構(gòu)建��,其函數(shù)調(diào)用如下:
mx.mlp(data, label, hidden_node=1, dropout=NULL, activation=”tanh”, out_activation=”softmax”, device=mx.ctx.default(),…)
參數(shù)如下:
data - 輸入矩陣
label - 培訓(xùn)標(biāo)簽
hidden_node - 包含每個(gè)隱藏層中隱藏節(jié)點(diǎn)數(shù)量的向量
dropout - [0,1)中包含從最后一個(gè)隱藏層到輸出層的丟失率的數(shù)字
activation - 包含激活函數(shù)名稱的單個(gè)字符串或向量�。有效值是{ 'relu'��,'sigmoid'���,'softrelu'����,'tanh'}
out_activation - 包含輸出激活函數(shù)名稱的單個(gè)字符串。有效值是{ 'rmse'�,'sofrmax','logistic'}
device- 是否訓(xùn)練mx.cpu(默認(rèn))或mx.gpu
... - 傳遞給其他參數(shù) mx.model.FeedForward.create
函數(shù)mx.model.FeedForward.create在內(nèi)部使用����,mx.mpl并采用以下參數(shù):
symbol - 神經(jīng)網(wǎng)絡(luò)的符號(hào)配置
y - 標(biāo)簽數(shù)組
x - 培訓(xùn)數(shù)據(jù)
ctx - 上下文,即設(shè)備(CPU / GPU)或設(shè)備列表(多個(gè)CPU或GPU)
num.round - 訓(xùn)練模型的迭代次數(shù)
optimizer- 字符串(默認(rèn)是'sgd')
initializer - 參數(shù)的初始化方案
eval.data - 過(guò)程中使用的驗(yàn)證集
eval.metric - 評(píng)估結(jié)果的功能
epoch.end.callback - 迭代結(jié)束時(shí)回調(diào)
batch.end.callback - 當(dāng)一個(gè)小批量迭代結(jié)束時(shí)回調(diào)
array.batch.size - 用于陣列訓(xùn)練的批量大小
array.layout-可以是{ 'auto'���,'colmajor'�����,'rowmajor'}
kvstore - 多個(gè)設(shè)備的同步方案
示例調(diào)用:
model <- mx.mlp(train.x, train.y, hidden_node=c(128,64), out_node=2,
activation="relu", out_activation="softmax",num.round=100,
array.batch.size=15, learning.rate=0.07, momentum=0.9, device=mx.cpu())
之后要使用訓(xùn)練好的模型��,我們只需要調(diào)用predict()指定model第一個(gè)參數(shù)和testset第二個(gè)參數(shù)的函數(shù):
preds = predict(model, testset)
這個(gè)函數(shù)mx.mlp()本質(zhì)上代表了使用MXNet的'Symbol'系統(tǒng)定義一個(gè)神經(jīng)網(wǎng)絡(luò)的更靈活但更長(zhǎng)的過(guò)程�����。以前的網(wǎng)絡(luò)符號(hào)定義的等價(jià)物將是:
data <- mx.symbol.Variable("data") fc1 <-
mx.symbol.FullyConnected(data, num_hidden=128) act1 <-
mx.symbol.Activation(fc1, name="relu1", act_type="relu")
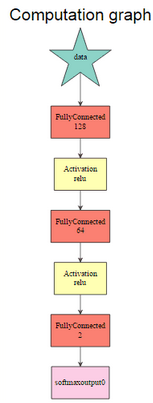
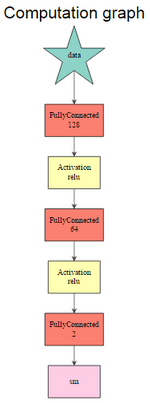
當(dāng)網(wǎng)絡(luò)架構(gòu)最終被創(chuàng)建時(shí)����,MXNetR提供了一種簡(jiǎn)單的方法來(lái)使用以下函數(shù)調(diào)用來(lái)圖形化地檢查它:
graph.viz(model$symbol$as.json())
graph.viz(model2$symbol$as.json())
這里�,參數(shù)是由符號(hào)表示的訓(xùn)練模型����。第一個(gè)網(wǎng)絡(luò)由mx.mlp()第二個(gè)網(wǎng)絡(luò)構(gòu)建���,第二個(gè)網(wǎng)絡(luò)使用符號(hào)系統(tǒng)�。
該定義從輸入到輸出逐層進(jìn)行�����,同時(shí)還為每個(gè)層分別允許不同數(shù)量的神經(jīng)元和特定的激活函數(shù)�。其他選項(xiàng)可通過(guò)mx.symbol以下方式獲得:mx.symbol.Convolution,將卷積應(yīng)用于輸入�,然后添加偏差。它可以創(chuàng)建卷積神經(jīng)網(wǎng)絡(luò)�����。相反mx.symbol.Deconvolution�����,通常在分割網(wǎng)絡(luò)中使用mx.symbol.UpSampling�����,以便重建圖像的按像素分類�����。CNN中使用的另一種類型的層是mx.symbol.Pooling; 這實(shí)質(zhì)上通過(guò)選擇具有最高響應(yīng)的信號(hào)來(lái)減少數(shù)據(jù)�。該層mx.symbol.Flatten需要將卷積層和池層鏈接到完全連接的網(wǎng)絡(luò)。另外��,mx.symbol.Dropout可以用來(lái)應(yīng)付過(guò)度配合的問(wèn)題�。它將輸入的參數(shù)previous_layer和浮點(diǎn)值fraction作為下降的參數(shù)。
正如我們所看到的�,MXNetR可用于快速設(shè)計(jì)標(biāo)準(zhǔn)多層感知器的功能,mx.mlp()或用于更廣泛的關(guān)于符號(hào)表示的實(shí)驗(yàn)��。
LeNet網(wǎng)絡(luò)示例:
data <- mx.symbol.Variable('data')
總而言之�����,MXNetR軟件包非常靈活����,同時(shí)支持多個(gè)CPU和多個(gè)GPU。它具有構(gòu)建標(biāo)準(zhǔn)前饋網(wǎng)絡(luò)的捷徑�,同時(shí)也提供了靈活的功能來(lái)構(gòu)建更復(fù)雜的定制網(wǎng)絡(luò),如CNN LeNet���。
包“darch”
darch軟件包(darch 2015)實(shí)施深層架構(gòu)的訓(xùn)練��,如深層信念網(wǎng)絡(luò)��,它由分層預(yù)訓(xùn)練的限制玻爾茲曼機(jī)器組成��。該套件還需要反向傳播進(jìn)行微調(diào)��,并且在最新版本中����,可以選擇預(yù)培訓(xùn)。
深層信仰網(wǎng)絡(luò)的培訓(xùn)是通過(guò)darch()功能進(jìn)行的��。
示例調(diào)用:
darch <- darch(train.x, train.y, rbm.numEpochs = 0,
rbm.batchSize = 100, rbm.trainOutputLayer =
F, layers = c(784,100,10), darch.batchSize
= 100, darch.learnRate = 2,
darch.retainData = F, darch.numEpochs = 20
)
這個(gè)函數(shù)帶有幾個(gè)最重要的參數(shù)�,如下所示:
x - 輸入數(shù)據(jù)
y - 目標(biāo)數(shù)據(jù)
layers - 包含一個(gè)整數(shù)的矢量,用于每個(gè)圖層中的神經(jīng)元數(shù)量(包括輸入和輸出圖層)
rbm.batchSize - 預(yù)培訓(xùn)批量大小
rbm.trainOutputLayer - 在訓(xùn)練前使用的布爾值��。如果屬實(shí)���,RBM的輸出層也會(huì)被訓(xùn)練
rbm.numCD - 執(zhí)行對(duì)比分歧的完整步數(shù)
rbm.numEpochs - 預(yù)培訓(xùn)的時(shí)期數(shù)量
darch.batchSize - 微調(diào)批量大小
darch.fineTuneFunction - 微調(diào)功能
darch.dropoutInput - 網(wǎng)絡(luò)輸入丟失率
darch.dropoutHidden - 隱藏層上的丟失率
darch.layerFunctionDefault-為DBN默認(rèn)激活功能�,可用的選項(xiàng)包括{ 'sigmoidUnitDerivative'��,'binSigmoidUnit'�����,'linearUnitDerivative'�,'linearUnit','maxoutUnitDerivative'���,'sigmoidUnit'���,'softmaxUnitDerivative','softmaxUnit'��,'tanSigmoidUnitDerivative'���,'tanSigmoidUnit'}
darch.stopErr - 如果錯(cuò)誤小于或等于閾值��,則停止訓(xùn)練
darch.numEpochs - 微調(diào)的時(shí)代數(shù)量
darch.retainData - 布爾型��,指示在培訓(xùn)之后將訓(xùn)練數(shù)據(jù)存儲(chǔ)在darch實(shí)例中的天氣
根據(jù)以前的參數(shù)��,我們可以訓(xùn)練我們的模型產(chǎn)生一個(gè)對(duì)象darch��。稍后我們可以將其應(yīng)用于測(cè)試數(shù)據(jù)集test.x來(lái)進(jìn)行預(yù)測(cè)�����。在這種情況下����,一個(gè)附加參數(shù)type指定預(yù)測(cè)的輸出類型。例如�,可以‘raw’給出‘bin’二進(jìn)制向量和‘class’類標(biāo)簽的概率。最后�,在調(diào)用時(shí)predict()進(jìn)行如下預(yù)測(cè):
predictions <- predict(darch, test.x, type="bin")
總的來(lái)說(shuō),darch的基本用法很簡(jiǎn)單��。它只需要一個(gè)功能來(lái)訓(xùn)練網(wǎng)絡(luò)�。但另一方面,這套教材只限于深層的信仰網(wǎng)絡(luò)���,這通常需要更廣泛的訓(xùn)練����。
包“deepnet ”
deepnet (deepnet
2015)是一個(gè)相對(duì)較小�����,但相當(dāng)強(qiáng)大的軟件包��,有多種架構(gòu)可供選擇。它可以使用函數(shù)來(lái)訓(xùn)練一個(gè)前饋網(wǎng)絡(luò)���,也可以用nn.train()深度信念網(wǎng)絡(luò)來(lái)初始化權(quán)重dbn.dnn.train()�。這個(gè)功能在內(nèi)部rbm.train()用來(lái)訓(xùn)練一個(gè)受限制的波爾茲曼機(jī)器(也可以單獨(dú)使用)�。此外����,深網(wǎng)也可以處理堆疊的自動(dòng)編碼器sae.dnn.train()。
示例調(diào)用(for nn.train()):
nn.train(x, y, initW=NULL, initB=NULL, hidden=c(50,20),
activationfun="sigm", learningrate=0.8, momentum=0.5,
learningrate_scale=1, output="sigm", numepochs=3, batchsize=100,
hidden_dropout=0, visible_dropout=0)
人們可以設(shè)置原來(lái)的權(quán)initW重initB�����,否則隨機(jī)生成���。另外���,hidden控制的在隱藏層單元的數(shù)量,而activationfun指定的隱藏層的激活功能(可以是‘sigm’�,‘linear’或‘tanh’),以及輸出層的(可以是‘sigm’�,‘linear’,‘softmax’)���。
作為一種選擇���,下面的例子訓(xùn)練一個(gè)神經(jīng)網(wǎng)絡(luò)����,其中權(quán)重是由深層信念網(wǎng)絡(luò)(via dbn.dnn.train())初始化的�����。差別主要在于訓(xùn)練受限玻爾茲曼機(jī)的對(duì)比散度算法����。它是通過(guò)cd給定學(xué)習(xí)算法內(nèi)的吉布斯采樣的迭代次數(shù)來(lái)設(shè)置的。
dbn.dnn.train(x, y, hidden=c(1), activationfun="sigm", learningrate=0.8,
momentum=0.5, learningrate_scale=1, output="sigm", numepochs=3,
batchsize=100, hidden_dropout=0, visible_dropout=0, cd=1)
同樣�,也可以從堆棧自動(dòng)編碼器初始化權(quán)重。output這個(gè)例子不是使用參數(shù)���,而是sae_output和以前一樣使用�����。
sae.dnn.train(x, y, hidden=c(1), activationfun="sigm", learningrate=0.8,
momentum=0.5, learningrate_scale=1, output="sigm", sae_output="linear",
numepochs=3, batchsize=100, hidden_dropout=0, visible_dropout=0)
最后���,我們可以使用訓(xùn)練有素的網(wǎng)絡(luò)來(lái)預(yù)測(cè)結(jié)果nn.predict()。隨后,我們可以借助nn.test()錯(cuò)誤率將預(yù)測(cè)轉(zhuǎn)化為錯(cuò)誤率����。第一次調(diào)用需要一個(gè)神經(jīng)網(wǎng)絡(luò)和相應(yīng)的觀察值作為輸入。第二個(gè)電話在進(jìn)行預(yù)測(cè)時(shí)還需要正確的標(biāo)簽和閾值(默認(rèn)值為0.5)���。
predictions = nn.predict(nn, test.x) error_rate = nn.test(nn, test.x, test.y, t=0.5)
總而言之��,深網(wǎng)代表了一個(gè)輕量級(jí)的包�����,其中包含了一系列有限的參數(shù)。但是�,它提供了多種體系結(jié)構(gòu)。
包裝“H2O”
H2O是一個(gè)開(kāi)源軟件平臺(tái)�����,可以利用分布式計(jì)算機(jī)系統(tǒng)(H2O 2015)��。其核心以Java編碼,需要最新版本的JVM和JDK�,可以在https://www.java.com/en/download/上找到�����。該軟件包為許多語(yǔ)言提供接口,最初設(shè)計(jì)用作基于云的平臺(tái)(Candel
et al���。2015)���。因此,通過(guò)調(diào)用h2o.init()以下命令啟動(dòng)H2O :
h2o.init(nthreads = -1)
該參數(shù)nthreads指定將使用多少個(gè)核心進(jìn)行計(jì)算�����。值-1表示H2O將嘗試使用系統(tǒng)上所有可用的內(nèi)核����,但默認(rèn)為2.此例程也可以使用參數(shù),ip并且portH2O安裝在不同的機(jī)器上����。默認(rèn)情況下,它將IP地址127.0.0.1與端口54321一起使用��。因此����,可以在瀏覽器中定位地址“l(fā)ocalhost:54321”以訪問(wèn)基于Web的界面��。一旦您使用當(dāng)前的H2O實(shí)例完成工作�,您需要通過(guò)以下方式斷開(kāi)連接:
h2o.shutdown()
示例調(diào)用:
所有培訓(xùn)操作h2o.deeplearning()如下:
model <- h2o.deeplearning( x=x, y=y, training_frame=train,
validation_frame=test, distribution="multinomial",
activation="RectifierWithDropout", hidden=c(32,32,32),
input_dropout_ratio=0.2, sparse=TRUE, l1=1e-5, epochs=100)
用于在H2O中傳遞數(shù)據(jù)的接口與其他包略有不同:x是包含具有訓(xùn)練數(shù)據(jù)的列的名稱的向量��,并且y是具有所有名稱的變量的名稱�。接下來(lái)的兩個(gè)參數(shù),training_frame并且validation_frame�����,是H2O幀的對(duì)象����。它們可以通過(guò)調(diào)用來(lái)創(chuàng)建h2o.uploadFile(),它將目錄路徑作為參數(shù)���,并將csv文件加載到環(huán)境中。特定數(shù)據(jù)類的使用是由分布式環(huán)境激發(fā)的�����,因?yàn)閿?shù)據(jù)應(yīng)該在整個(gè)集群中可用�����。所述參數(shù)distribution是一個(gè)字符串,并且可以采取的值‘bernoulli’���,‘multinomial’�����,‘poisson’��,‘gamma’�����,‘tweedie’�����,‘laplace’���,‘huber’或‘gaussian’,而‘AUTO’根據(jù)數(shù)據(jù)自動(dòng)選擇一個(gè)參數(shù)�。以下參數(shù)指定activation功能(可能的值是‘Tanh’,‘TanhWithDropout’�����,‘Rectifier’,‘RectifierWithDropout’�����,‘Maxout’或‘MaxoutWithDropout’)���。該參數(shù)sparse是表示高度零的布爾值�,這使得H2
=可以更有效地處理它���。其余的參數(shù)是直觀的�,與其他軟件包差別不大��。然而����,還有更多的微調(diào)可用,但可能沒(méi)有必要更改它們�����,因?yàn)樗鼈儙в型扑]的預(yù)定義值��。
最后�����,我們可以使用h2o.predict()以下簽名進(jìn)行預(yù)測(cè):
predictions <- h2o.predict(model, newdata=test_data)
H2O提供的另一個(gè)強(qiáng)大工具是優(yōu)化超參數(shù)的網(wǎng)格搜索����。可以為每個(gè)參數(shù)指定一組值�����,然后找到最佳組合值h2o.grid()��。
超參數(shù)優(yōu)化
H2 =包將訓(xùn)練四種不同的模型��,兩種架構(gòu)和不同的L1正則化權(quán)重����。因此,可以很容易地嘗試一些超參數(shù)的組合����,看看哪一個(gè)更好:
深度自動(dòng)編碼器
H2O也可以利用深度自動(dòng)編碼器。為了訓(xùn)練這樣的模型��,使用相同的功能h2o.deeplearning()��,但是這組參數(shù)略有不同
在這里,我們只使用訓(xùn)練數(shù)據(jù)����,沒(méi)有測(cè)試集和標(biāo)簽。我們需要深度自動(dòng)編碼器而不是前饋網(wǎng)絡(luò)的事實(shí)由autoencoder參數(shù)指定��。和以前一樣��,我們可以選擇多少隱藏單元應(yīng)該在不同的層次���。如果我們使用一個(gè)整數(shù)值��,我們將得到一個(gè)天真的自動(dòng)編碼器���。
訓(xùn)練結(jié)束后,我們可以研究重建誤差�����。我們通過(guò)特定的h2o.anomaly()函數(shù)來(lái)計(jì)算它�。
總的來(lái)說(shuō),H2O是一個(gè)非常用戶友好的軟件包��,可以用來(lái)訓(xùn)練前饋網(wǎng)絡(luò)或深度自動(dòng)編碼器��。它支持分布式計(jì)算并提供一個(gè)Web界面��。
包“更深”
deepr (deepr
2015)包本身并沒(méi)有實(shí)現(xiàn)任何深度學(xué)習(xí)算法���,而是將其任務(wù)轉(zhuǎn)交給H20�。該包最初是在CRAN尚未提供H2O包的時(shí)候設(shè)計(jì)的���。由于情況不再是這樣�,我們會(huì)將其排除在比較之外����。我們也注意到它的功能train_rbm()使用深層的實(shí)現(xiàn)rbm來(lái)訓(xùn)練帶有一些附加輸出的模型。
軟件包的比較
本節(jié)將比較不同指標(biāo)的上述軟件包�����。其中包括易用性��,靈活性��,易于安裝�,支持并行計(jì)算和協(xié)助選擇超參數(shù)。另外,我們測(cè)量了三個(gè)常見(jiàn)數(shù)據(jù)集“Iris”��,“MNIST”和“森林覆蓋類型”的表現(xiàn)�����。我們希望我們的比較幫助實(shí)踐者和研究人員選擇他們喜歡的深度學(xué)習(xí)包���。
安裝
通過(guò)CRAN安裝軟件包通常非常簡(jiǎn)單和流暢���。但是,一些軟件包依賴于第三方庫(kù)�����。例如�,H2O需要最新版本的Java以及Java Development
Kit。darch和MXNetR軟件包允許使用GPU�����。為此�����,darch依賴于R軟件包gpuools,它僅在Linux和MacOS系統(tǒng)上受支持��。默認(rèn)情況下��,MXNetR不支持GPU�,因?yàn)樗蕾囉赾uDNN����,由于許可限制,cuDNN不能包含在軟件包中����。因此,MXNetR的GPU版本需要Rtools和一個(gè)支持C
++ 11的現(xiàn)代編譯器�,以使用CUDA SDK和cuDNN從源代碼編譯MXNet。
靈活性
就靈活性而言�,MXNetR很可能位列榜首。它允許人們嘗試不同的體系結(jié)構(gòu)����,因?yàn)樗x了網(wǎng)絡(luò)的分層方法,更不用說(shuō)豐富多樣的參數(shù)了��。在我們看來(lái)����,我們認(rèn)為H2O和darch都是第二名�。H20主要針對(duì)前饋網(wǎng)絡(luò)和深度自動(dòng)編碼器����,而darch則側(cè)重于受限制的玻爾茲曼機(jī)器和深度信念網(wǎng)絡(luò)。這兩個(gè)軟件包提供了廣泛的調(diào)整參數(shù)�。最后但并非最不重要的一點(diǎn),deepnet是一個(gè)相當(dāng)輕量級(jí)的軟件包����,但是當(dāng)想要使用不同的體系結(jié)構(gòu)時(shí),它可能是有益的�����。然而�,我們并不推薦將其用于龐大數(shù)據(jù)集的日常使用,因?yàn)槠洚?dāng)前版本缺乏GPU支持���,而相對(duì)較小的一組參數(shù)不允許最大限度地進(jìn)行微調(diào)��。
使用方便
H2O和MXNetR的速度和易用性突出�。MXNetR幾乎不需要準(zhǔn)備數(shù)據(jù)來(lái)開(kāi)始訓(xùn)練�,而H2O通過(guò)使用as.h2o()將數(shù)據(jù)轉(zhuǎn)換為H2OFrame對(duì)象的函數(shù)提供了非常直觀的包裝�����。這兩個(gè)包提供了額外的工具來(lái)檢查模型�。深網(wǎng)以單熱編碼矩陣的形式獲取標(biāo)簽��。這通常需要一些預(yù)處理���,因?yàn)榇蠖鄶?shù)數(shù)據(jù)集都具有矢量格式的類。但是����,它沒(méi)有報(bào)告關(guān)于培訓(xùn)期間進(jìn)展的非常詳細(xì)的信息。該軟件包還缺少用于檢查模型的附加工具�。darch,另一方面��,有一個(gè)非常好的和詳細(xì)的輸出�。
總的來(lái)說(shuō),我們將H2O或者MXNetR看作是這個(gè)類別的贏家�,因?yàn)閮烧叨己芸觳⑶以谟?xùn)練期間提供反饋。這使得人們可以快速調(diào)整參數(shù)并提高預(yù)測(cè)性能����。
并行
深度學(xué)習(xí)在處理大量數(shù)據(jù)集時(shí)很常見(jiàn)��。因此����,當(dāng)軟件包允許一定程度的并行化時(shí)�,它可以是巨大的幫助。表2比較了并行化的支持����。它只顯示文件中明確說(shuō)明的信息。
參數(shù)的選擇
另一個(gè)關(guān)鍵的方面是超參數(shù)的選擇����。H2O軟件包使用全自動(dòng)的每神經(jīng)元自適應(yīng)學(xué)習(xí)速率來(lái)快速收斂。它還可以選擇使用n-fold交叉驗(yàn)證�,并提供h2o.grid()網(wǎng)格搜索功能,以優(yōu)化超參數(shù)和模型選擇�����。
MXNetR在每次迭代后顯示訓(xùn)練的準(zhǔn)確性���。darch在每個(gè)紀(jì)元后顯示錯(cuò)誤�����。兩者都允許在不等待收斂的情況下手動(dòng)嘗試不同的超參數(shù)����,因?yàn)槿绻葲](méi)有提高,訓(xùn)練階段可以提前終止���。相比之下����,深網(wǎng)不會(huì)顯示任何信息���,直到訓(xùn)練完成,這使得調(diào)整超參數(shù)非常具有挑戰(zhàn)性�����。
性能和運(yùn)行時(shí)間
我們準(zhǔn)備了一個(gè)非常簡(jiǎn)單的性能比較����,以便為讀者提供有關(guān)效率的信息。所有后續(xù)測(cè)量都是在CPU Intel Core i7和GPU NVidia
GeForce
750M(Windows操作系統(tǒng))的系統(tǒng)上進(jìn)行的��。比較是在三個(gè)數(shù)據(jù)集上進(jìn)行的:“MNIST” (LeCun等人2012)���,“Iris” (Fisher
1936)和“森林覆蓋類型” (Blackard和Dean 1998)�����。詳情見(jiàn)附錄��。
作為基準(zhǔn)���,我們使用H2O包中實(shí)現(xiàn)的隨機(jī)森林算法���。隨機(jī)森林是通過(guò)構(gòu)建多個(gè)決策樹(shù)(維基百科2016b)來(lái)工作的集合學(xué)習(xí)方法。有趣的是����,它已經(jīng)證明了它能夠在不進(jìn)行參數(shù)調(diào)整的情況下在很大程度上實(shí)現(xiàn)高性能。
結(jié)果
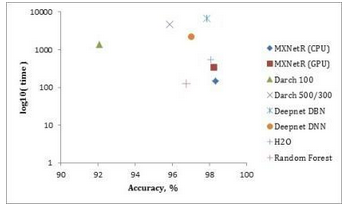
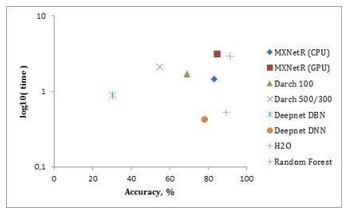
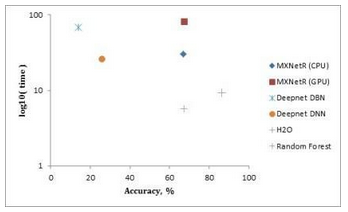
測(cè)量結(jié)果在表3中給出��,并且在圖2��,圖3和圖4中分別針對(duì)“MNIST”��,“虹膜”和“森林覆蓋類型”數(shù)據(jù)集可視化����。
'MNIST'數(shù)據(jù)集��。根據(jù)表3和圖2�����,MXNetR和H2O在“MNIST”數(shù)據(jù)集上實(shí)現(xiàn)了運(yùn)行時(shí)間和預(yù)測(cè)性能之間的優(yōu)越折衷�。darch和deepnet需要相對(duì)較長(zhǎng)的時(shí)間來(lái)訓(xùn)練網(wǎng)絡(luò)��,同時(shí)達(dá)到較低的精度���。
'虹膜'數(shù)據(jù)集���。在這里,我們?cè)俅慰吹?a href='/map/mxnet/' style='color:#000;font-size:inherit;'>MXNetR和H2O表現(xiàn)最好����。從圖3可以看出����,深網(wǎng)具有最低的準(zhǔn)確性,可能是因?yàn)樗侨绱诵〉臄?shù)據(jù)集����,在訓(xùn)練前誤導(dǎo)��。正因?yàn)槿绱?���,darch 100和darch 500/300通過(guò)反向傳播訓(xùn)練���,省略了訓(xùn)練前的階段�����。這由表中的*符號(hào)標(biāo)記����。
“森林覆蓋類型”數(shù)據(jù)集�����。H2O和MXNetR顯示的準(zhǔn)確率大約為67%��,但是這還是比其他軟件包好��。我們注意到darch 100和darch 500/300的培訓(xùn)沒(méi)有收斂�,因此這些模型被排除在這個(gè)比較之外。
我們希望,即使是這種簡(jiǎn)單的性能比較���,也可以為從業(yè)人員在選擇自己喜歡的R包時(shí)提供有價(jià)值的見(jiàn)解
注意:從圖3和圖4可以看出��,隨機(jī)森林比深度學(xué)習(xí)包能夠表現(xiàn)得更好���。這有幾個(gè)有效的原因。首先��,數(shù)據(jù)集太小�,因?yàn)?a href='/map/shenduxuexi/' style='color:#000;font-size:inherit;'>深度學(xué)習(xí)通常需要大數(shù)據(jù)或使用數(shù)據(jù)增強(qiáng)才能正常工作。其次�,這些數(shù)據(jù)集中的數(shù)據(jù)由手工特征組成,這就否定了深層架構(gòu)從原始數(shù)據(jù)中學(xué)習(xí)這些特征的優(yōu)勢(shì)����,因此傳統(tǒng)方法可能就足夠了。最后�����,我們選擇非常相似的(也可能不是最高效的)體系結(jié)構(gòu)來(lái)比較不同的實(shí)現(xiàn)�。
表3. R中不同深度學(xué)習(xí)包的準(zhǔn)確性和運(yùn)行時(shí)間的比較
*僅使用反向傳播訓(xùn)練的模型(不進(jìn)行預(yù)訓(xùn)練)���。
型號(hào)/數(shù)據(jù)集MNIST鳶尾花森林覆蓋類型
準(zhǔn)確性 (%)運(yùn)行時(shí)間(秒)準(zhǔn)確性 (%)運(yùn)行時(shí)間(秒)準(zhǔn)確性 (%)運(yùn)行時(shí)間(秒)
圖2.比較“MNIST”數(shù)據(jù)集的運(yùn)行時(shí)間和準(zhǔn)確度���。
圖3.“虹膜”數(shù)據(jù)集的運(yùn)行時(shí)間和精度比較
圖4.“森林覆蓋類型”數(shù)據(jù)集的運(yùn)行時(shí)間和準(zhǔn)確度的比較���。
結(jié)論
作為本文的一部分,我們?cè)赗中比較了五種不同的軟件包�����,以便進(jìn)行深入的學(xué)習(xí):(1)當(dāng)前版本的deepnet可能代表可用體系結(jié)構(gòu)中差異最大的軟件包����。但是,由于它的實(shí)施��,它可能不是最快也不是用戶最友好的選擇���。此外�����,它可能不提供與其他一些軟件包一樣多的調(diào)整參數(shù)���。(2)H2O和MXNetR相反�,提供了非常人性化的體驗(yàn)�����。兩者還提供額外信息的輸出���,快速進(jìn)行訓(xùn)練并取得體面的結(jié)果�。H2O可能更適合集群環(huán)境�����,數(shù)據(jù)科學(xué)家可以在簡(jiǎn)單的流水線中使用它來(lái)進(jìn)行數(shù)據(jù)挖掘和勘探����。當(dāng)靈活性和原型更受關(guān)注時(shí),MXNetR可能是最合適的選擇�����。它提供了一個(gè)直觀的符號(hào)工具���,用于從頭構(gòu)建自定義網(wǎng)絡(luò)體系結(jié)構(gòu)�����。此外��,通過(guò)利用多CPU
/ GPU功能�����,它可以在個(gè)人電腦上運(yùn)行����。(3)darch提供了一個(gè)有限但是有針對(duì)性的功能���,重點(diǎn)是深度信念網(wǎng)絡(luò)���。
總而言之,我們看到R對(duì)深度學(xué)習(xí)的支持正在順利進(jìn)行�。最初,R提供的功能落后于其他編程語(yǔ)言����。但是,這不再是這種情況����。有了H20和MXnetR��,R用戶就可以在指尖上使用兩個(gè)強(qiáng)大的工具���。
CDA數(shù)據(jù)分析師考試相關(guān)入口一覽(建議收藏):
? 想報(bào)名CDA認(rèn)證考試,點(diǎn)擊>>>
“CDA報(bào)名”
了解CDA考試詳情����;
? 想學(xué)習(xí)CDA考試教材,點(diǎn)擊>>> “CDA教材” 了解CDA考試詳情����;
? 想加入CDA考試題庫(kù),點(diǎn)擊>>> “CDA題庫(kù)” 了解CDA考試詳情�����;
? 想了解CDA考試含金量��,點(diǎn)擊>>> “CDA含金量” 了解CDA考試詳情�;











 京公網(wǎng)安備 11010802034615號(hào)
經(jīng)營(yíng)許可證編號(hào):京B2-20210330
京公網(wǎng)安備 11010802034615號(hào)
經(jīng)營(yíng)許可證編號(hào):京B2-20210330