SPSS操作:多個相關(guān)樣本的非參數(shù)檢驗(Cochran's Q檢驗)
一、問題與數(shù)據(jù)
某康復(fù)科醫(yī)生擬評價康復(fù)訓(xùn)練對卒中后患者體能恢復(fù)的效果���?����;颊叻謩e在開始康復(fù)�����、康復(fù)3個月和康復(fù)6個月時進行體能測試��。為了保證一致性��,三次體能測試內(nèi)容是一樣的���,體能測試的結(jié)果為“通過”和“不通過”�。該醫(yī)生想知道卒中后患者體能測試的結(jié)果為“通過”的比例是否一直上升����。
該研究隨機選取了63例進行康復(fù)訓(xùn)練的卒中后患者,并收集了所有研究對象的開始康復(fù)時的體能測試結(jié)果
(initial_fitness_test)���,康復(fù)3個月時的體能測試結(jié)果
(month3_fitness_test)和康復(fù)6個月時的體能測試結(jié)果
(final_fitness_test)��。結(jié)果均為“通過(Passed)”和“不通過(Failed)”的形式(分別賦值為1和2)�。部分數(shù)據(jù)如下圖。
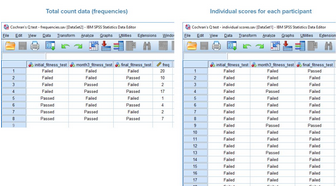
其中��,Individual scores for each paticipant列出了每一個研究對象的情況��,而Total count data (frequencies)則是對相同情況研究對象的數(shù)據(jù)進行了匯總��。
二�����、對問題的分析
要檢驗三組或多組相關(guān)樣本中����,分類變量是否存在差異,可以使用Cochran's Q 檢驗����,但需要考慮以下4個假設(shè)。
假設(shè)1:結(jié)局變量為二分類��,且兩類之間互斥����。互斥是指一個研究對象只能在一個分組中,不可能同時出現(xiàn)在兩個組中���。例如 “安全”和“不安全”,“及格”和“不及格”等�����。
假設(shè)2:分組變量包含3個及以上分類�����,且各組之間相關(guān)���。(當分組變量只有2個分類時��,可使用McNemar’s檢驗)
假設(shè)3:樣本是來自于研究人群的隨機樣本����。然而實際中�����,樣本并非都是隨機樣本����。
假設(shè)4:樣本量足夠����。當樣本量n≥4且nk≥24(k為分組變量數(shù))時�,可以采用Cochran's Q檢驗;否則采用“精確” Cochran's Q檢驗����。
本研究中,結(jié)局變量有兩個分組且互斥(“通過”和“不通過”)�,符合假設(shè)1;分組變量包含3個分類(開始康復(fù)����、康復(fù)3個月和康復(fù)6個月時),各組之間相關(guān)��,符合假設(shè)2�����;研究對象是隨機選取�����,符合假設(shè)3。
那么應(yīng)該如何檢驗假設(shè)4��,并進行比較呢�?
三、SPSS操作
3.1 檢驗假設(shè)4:樣本量足夠
1. 轉(zhuǎn)換數(shù)據(jù)格式
如果原始數(shù)據(jù)格式是Total
count data (frequencies)�,則可以跳過此步。如果原始數(shù)據(jù)格式是Individual scores for each
paticipant�,則需要將數(shù)據(jù)轉(zhuǎn)換成Total count data (frequencies)格式���。
在主界面點擊Data→Aggregate���,出現(xiàn)Aggregate Data對話框。將變量initial_fitness_test��、month3_fitness_test和final_fitness_test選入Break Variable(s)框中�����。
點擊下方Number
of cases框���,并在Name框中填入“freq”���。在Save下方勾選Create a new dataset containing
only the aggregated variables,并在Dataset
name框中填入新數(shù)據(jù)集的名字(例如“cochran_q_freq”)。
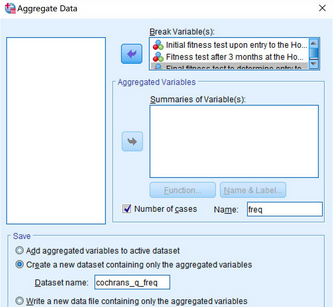
點擊OK��,產(chǎn)生新數(shù)據(jù)集���。在新數(shù)據(jù)集中�,可以看到新變量“freq”�,代表每一種自變量組合的頻數(shù)。
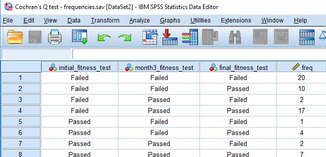
2. 數(shù)據(jù)加權(quán)
使用Total
count data (frequencies)格式數(shù)據(jù)��,并在主界面點擊Data→Weight Cases����,彈出Weight
Cases對話框后,點擊Weight cases by�����,激活Frequency Variable窗口���。將freq變量放入Frequency
Variable欄���,點擊OK。
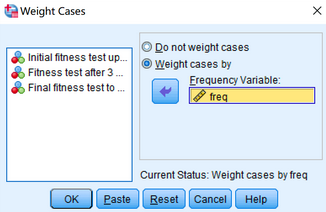
3. 計算樣本量
本研究的總樣本數(shù)N=63��,但計算Cochran's
Q
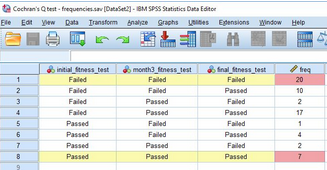
檢驗的樣本量時,需要減去三次測試結(jié)果都一致的樣本數(shù)����。如下突出顯示所示,全部為“Failed”有20例�,全部為“Passed”有7例,所以三次測試結(jié)果都一致的樣本數(shù)為20+7=27��,Cochran's
Q 檢驗的樣本量n=63-27=36��。
其次����,需要確定nk的大小�����。由于本研究共有三個分組���,所以k=3�,nk=36*3=108��。
綜上��,n≥4且nk≥24,符合假設(shè)4����。
3.2 計算比例
在主界面點擊Descriptive
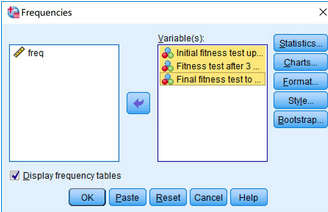
Statistics→Frequencies,在Frequencies對話框中��,將變量initial_fitness_test�、month3_fitness_test和final_fitness_test選入Variable(s):框中,點擊OK�。
3.3 符合假設(shè)4的Cochran's Q檢驗
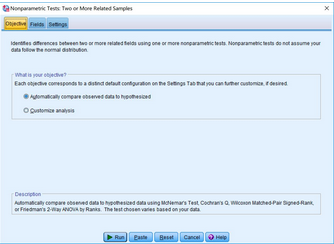
在主界面點擊Analyze→Nonparametric
Tests→Related Samples,出現(xiàn)Nonparametric Tests: Two or More Related
Samples對話框���。確認在What is your objective?區(qū)域勾選了Automatically compare observed
data to hypothesized�����。
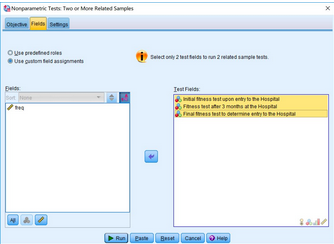
點擊Fields���,將變量initial_fitness_test、month3_fitness_test和final_fitness_test選入Test Fields框中��。
點擊Settings→Customize tests�����,勾選Cochran's Q (k samples)。
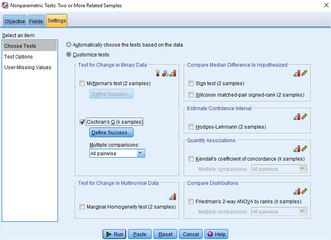
點擊Define
Success�����,在Cochran's Q: Define Success對話框中�����,點擊Combine values into success
category����,在Success框中填入1(這里是“成功”對應(yīng)的編碼,本例中即為通過體能測試�,“Passed”對應(yīng)的是1,所以這里填“1”)���。
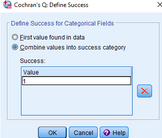
點擊OK→Run,輸出結(jié)果�。
3.4 不符合假設(shè)4的“精確”Cochran's Q檢驗
當不符合假設(shè)4時,需要使用“精確”Cochran's
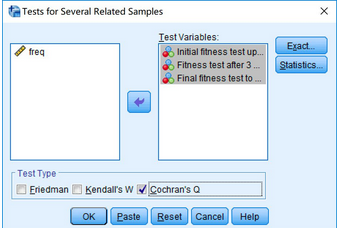
Q檢驗�����。在主界面點擊Analyze→Nonparametric Tests→Legacy Dialogs→K Related
Samples�����,出現(xiàn)Tests for Several Related Samples對話框。
將變量initial_fitness_test����、month3_fitness_test和final_fitness_test選入Test
Variables框中。在Test Type 下方去掉Friedman����,然后勾選Cochran's
Q。(如果數(shù)據(jù)符合假設(shè)4�,則此時點擊OK,結(jié)果與3.3部分的操作結(jié)果一致)
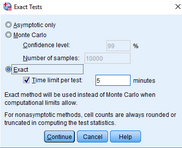
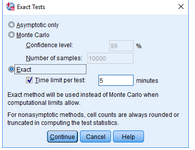
點擊Exact���,在Exact Tests對話框中�,點擊Exact��,點擊Continue→OK�。
3.5 “精確”Cochran's Q檢驗后的兩兩比較
對于符合假設(shè)4的Cochran's Q檢驗(3.3部分),事后的兩兩比較將在結(jié)果解釋部分展示(4.2部分)�。
對于不符合假設(shè)4的“精確”Cochran's Q檢驗(3.4部分)事后的兩兩比較,可采用經(jīng)Bonferroni法校正的多重McNemar檢驗�����。
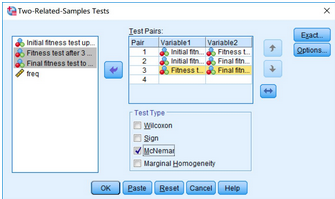
在主界面點擊Analyze→Nonparametric
Tests→Legacy Dialogs→2 Related Samples。在Two-Related-Samples
Tests對話框中�,依次選擇兩兩比較的變量,分別將變量initial_fitness_test和month3_fitness_test����、變量initial_fitness_test和final_fitness_test、變量month3_fitness_test和final_fitness_test選入右側(cè)Test
Pairs中���。 去掉Test Type下方的Wilcoxon�,勾選McNemar����。
點擊Exact,在Exact Tests對話框中����,點擊Exact,點擊Continue→OK���。
四、結(jié)果解釋
4.1 統(tǒng)計描述
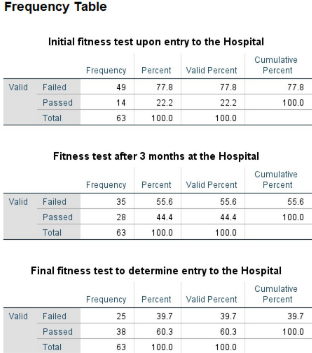
3.2部分的操作后�,得到的頻數(shù)結(jié)果見下圖?�?祻?fù)開始、康復(fù)3個月和康復(fù)6個月時培的體能測試的通過率分別為22.2%���、44.4% 和 60.3%���。
4.2 符合假設(shè)4的Cochran's Q檢驗及事后兩兩比較
3.3部分的操作后,得到Cochran's Q檢驗的結(jié)果如下圖�����。

上圖中�,第一列(Null
Hypothesis)是本研究的零假設(shè)。第二列(Test)顯示本研究的假設(shè)檢驗方法��,即Cochran's
Q檢驗�����。第三列(Sig.)是假設(shè)檢驗的統(tǒng)計結(jié)果��,即P值���。第四列(Decision)是根據(jù)假設(shè)檢驗做出的判斷�,即判斷是否拒絕零假設(shè)。
本研究Cochran's Q檢驗的P<0.001�����,拒絕零假設(shè)��。即開始康復(fù)�����、康復(fù)3個月和康復(fù)6個月時����,研究對象體能測試結(jié)果的差異具有統(tǒng)計學(xué)意義��。
雙擊該表�,SPSS會自動彈出Model Viewer界面,幫助我們進一步了解Hypothesis Test Summary表的結(jié)果��。
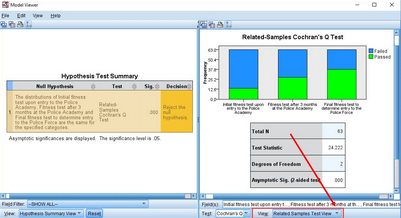
Cochran's Q檢驗統(tǒng)計量服從自由度為k-1的 χ2分布���。本研究的統(tǒng)計量為24.222���,此時統(tǒng)計量可記為 χ2 = 24.222, P<0.001。
在該視圖下方的View的下拉選項框中����,選擇“Pairwise Comparisons”,可以得到兩兩比較的結(jié)果�。兩兩比較的方法為Dunn’s檢驗(經(jīng)Bonferroni法校正)。
在Pairwise Comparisons圖中(此處略)�,連接線代表兩兩比較的結(jié)果,黑色連接線代表兩組間差異無統(tǒng)計學(xué)意義����,橘黃色連接線代表兩組差異具有統(tǒng)計學(xué)意義。
下方的表格(如下圖)給出了更多的信息:比較的組別��、統(tǒng)計量��、標準誤���、標準化的統(tǒng)計量(=統(tǒng)計量/標準誤)�����、P值和調(diào)整后的P值���。
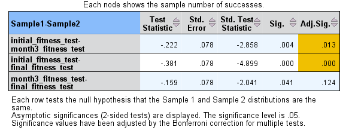
由于是事后的兩兩比較(Post
hoc
test)����,因此需要調(diào)整顯著性水平(調(diào)整α水平)���,作為判斷兩兩比較的顯著性水平�。依據(jù)Bonferroni法�����,調(diào)整α水平=原α水平÷比較次數(shù)�����。本研究共比較了3次���,調(diào)整α水平=0.05÷3=0.0167����。因此�����,最終得到的P值(上圖中Sig.一列),需要和0.0167比較��,小于0.0167則認為差異有統(tǒng)計學(xué)意義����。
另外�,SPSS也提供了調(diào)整后P值(上圖中Adj. Sig.一列),其思想還是采用Bonferroni法調(diào)整α水平�����。該列是將原始P值乘以比較次數(shù)得到��,因此可以直接和0.05比較����,小于0.05則認為差異有統(tǒng)計學(xué)意義。
以上結(jié)果可以描述為:康復(fù)開始和康復(fù)3個月時研究對象體能測試結(jié)果的差異有統(tǒng)計學(xué)意義(調(diào)整后P=0.013)��,康復(fù)開始和康復(fù)6個月時研究對象體能測試結(jié)果的差異有統(tǒng)計學(xué)意義(調(diào)整后P<0.001)�,而康復(fù)3個月和康復(fù)6個月時研究對象體能測試結(jié)果的差異無統(tǒng)計學(xué)意義。
4.3 不符合假設(shè)4的“精確”Cochran's Q檢驗
3.4部分的操作中�,既可以得到Cochran's Q檢驗的結(jié)果��,也可以得到“精確”Cochran's Q檢驗的結(jié)果(取決于是否選擇Exact選項)���。
結(jié)果如下圖。在Test Statistics表格中�����,左側(cè)是Cochran's Q檢驗結(jié)果�����,右側(cè)是“精確”Cochran's Q檢驗結(jié)果���。
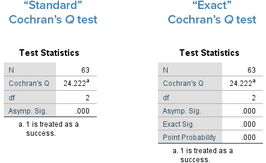
如果數(shù)據(jù)符合假設(shè)4���,則Cochran's
Q檢驗統(tǒng)計量服從自由度為k-1的 χ2分布。左側(cè)表格中的P值為“Asymp.
Sig.”所對應(yīng)的“0.000”��,即P<0.001���。本研究的統(tǒng)計量為24.222�����,此時統(tǒng)計量可記為 χ2 =
24.222���,P<0.001���。
如果數(shù)據(jù)不符合假設(shè)4,則右側(cè)表格中的P值為“Exact. Sig.”所對應(yīng)的“0.000”�����,即P<0.001��。本研究的統(tǒng)計量為24.222���,此時統(tǒng)計量可記為Cochran's Q = 24.222, P<0.001。
4.4 “精確”Cochran's Q檢驗后的兩兩比較
當不滿足假設(shè)4時�����,3.5部分的操作可得到經(jīng)Bonferroni法校正的多重McNemar檢驗的結(jié)果�。
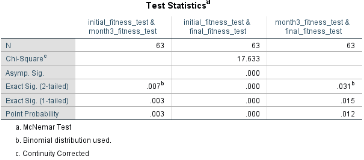
由于是事后的兩兩比較(Post
hoc
test),因此需要調(diào)整顯著性水平(調(diào)整α水平)�,作為判斷兩兩比較的顯著性水平。依據(jù)Bonferroni法����,調(diào)整α水平=原α水平÷比較次數(shù)��。本研究共比較了3次�,調(diào)整α水平=0.05÷3=0.0167����。因此,最終得到的P值(上圖中Exact
Sig. (2-tailed)一行)����,需要和0.0167比較,小于0.0167則認為差異有統(tǒng)計學(xué)意義��。
以上結(jié)果可以描述為:康復(fù)開始和康復(fù)3個月時研究對象體能測試結(jié)果的差異有統(tǒng)計學(xué)意義(P=0.007)�,康復(fù)開始和康復(fù)6個月時研究對象體能測試結(jié)果的差異有統(tǒng)計學(xué)意義(P<0.001),而康復(fù)3個月和康復(fù)6個月時研究對象體能測試結(jié)果的差異無統(tǒng)計學(xué)意義���。
五�、撰寫結(jié)論
1. 符合假設(shè)4時(即樣本量足夠)
開始康復(fù)�、康復(fù)3個月和康復(fù)6個月時,卒中后患者體能測試的通過率分別為22.2%����、44.4%和60.3%。運用Cochran's
Q 檢驗對三個時間點體能測試通過率進行檢驗�����,三個時間點通過率的差異具有統(tǒng)計學(xué)意義�����,χ2 = 24.222��, P<0.001。
采用Dunn’s檢驗(經(jīng)Bonferroni法校正)進行事后的兩兩比較�,康復(fù)開始和康復(fù)3個月時研究對象體能測試結(jié)果的差異有統(tǒng)計學(xué)意義(調(diào)整后P=0.013),康復(fù)開始和康復(fù)6個月時研究對象體能測試結(jié)果的差異有統(tǒng)計學(xué)意義(調(diào)整后P<0.001)����,而康復(fù)3個月和康復(fù)6個月時研究對象體能測試結(jié)果的差異無統(tǒng)計學(xué)意義(調(diào)整后P=0.124)。
2. 不符合假設(shè)4時
開始康復(fù)���、康復(fù)3個月和康復(fù)6個月時,卒中后患者體能測試的通過率分別為22.2%��、44.4%和60.3%��。運用Cochran's
Q 檢驗對三個時間點體能測試通過率進行檢驗���,三個時間點通過率的差異具有統(tǒng)計學(xué)意義���, Cochran's Q = 24.222,
P<0.001�。
運用“精確”McNemar’s檢驗進行事后的兩兩比較(經(jīng)Bonferroni法校正的α=0.0167)���??祻?fù)開始和康復(fù)3個月時研究對象體能測試結(jié)果的差異有統(tǒng)計學(xué)意義(P=0.007)��,康復(fù)開始和康復(fù)6個月時研究對象體能測試結(jié)果的差異有統(tǒng)計學(xué)意義(P<0.001)����,而康復(fù)3個月和康復(fù)6個月時研究對象體能測試結(jié)果的差異無統(tǒng)計學(xué)意義(P=0.031)�����。
推薦學(xué)習(xí)書籍
《CDA一級教材》適合CDA一級考生備考����,也適合業(yè)務(wù)及數(shù)據(jù)分析崗位的從業(yè)者提升自我�����。完整電子版已上線CDA網(wǎng)校�����,累計已有10萬+在讀~

免費加入閱讀:https://edu.cda.cn/goods/show/3151?targetId=5147&preview=0
CDA數(shù)據(jù)分析師考試相關(guān)入口一覽(建議收藏):
? 想報名CDA認證考試���,點擊>>>
“CDA報名”
了解CDA考試詳情�;
? 想學(xué)習(xí)CDA考試教材��,點擊>>> “CDA教材” 了解CDA考試詳情�����;
? 想加入CDA考試題庫,點擊>>> “CDA題庫” 了解CDA考試詳情����;
? 想了解CDA考試含金量,點擊>>> “CDA含金量” 了解CDA考試詳情�;











 京公網(wǎng)安備 11010802034615號
經(jīng)營許可證編號:京B2-20210330
京公網(wǎng)安備 11010802034615號
經(jīng)營許可證編號:京B2-20210330