常用的幾種大數(shù)據(jù)架構(gòu)剖析
數(shù)據(jù)分析工作雖然隱藏在業(yè)務(wù)系統(tǒng)背后,但是具有非常重要的作用����,數(shù)據(jù)分析的結(jié)果對(duì)決策�����、業(yè)務(wù)發(fā)展有著舉足輕重的作用����。隨著大數(shù)據(jù)技術(shù)的發(fā)展,數(shù)據(jù)挖掘����、數(shù)據(jù)探索等專有名詞曝光度越來(lái)越高,但是在類似于Hadoop系列的大數(shù)據(jù)分析系統(tǒng)大行其道之前����,數(shù)據(jù)分析工作已經(jīng)經(jīng)歷了長(zhǎng)足的發(fā)展,尤其是以BI系統(tǒng)為主的數(shù)據(jù)分析���,已經(jīng)有了非常成熟和穩(wěn)定的技術(shù)方案和生態(tài)系統(tǒng)�,對(duì)于BI系統(tǒng)來(lái)說(shuō)��,大概的架構(gòu)圖如下:
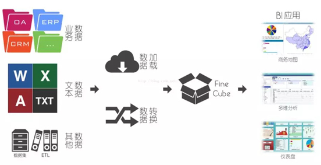
可以看到在BI系統(tǒng)里面��,核心的模塊是Cube��,Cube是一個(gè)更高層的業(yè)務(wù)模型抽象��,在Cube之上可以進(jìn)行多種操作�,例如上鉆��、下鉆�、切片等操作。大部分BI系統(tǒng)都基于關(guān)系型數(shù)據(jù)庫(kù),關(guān)系型數(shù)據(jù)庫(kù)使用SQL語(yǔ)句進(jìn)行操作���,但是SQL在多維操作和分析的表示能力上相對(duì)較弱���,所以Cube有自己獨(dú)有的查詢語(yǔ)言MDX,MDX表達(dá)式具有更強(qiáng)的多維表現(xiàn)能力�����,所以以Cube為核心的分析系統(tǒng)基本占據(jù)著數(shù)據(jù)統(tǒng)計(jì)分析的半壁江山�����,大多數(shù)的數(shù)據(jù)庫(kù)服務(wù)廠商直接提供了BI套裝軟件服務(wù)����,輕易便可搭建出一套Olap分析系統(tǒng)。不過(guò)BI的問(wèn)題也隨著時(shí)間的推移逐漸顯露出來(lái):
BI系統(tǒng)更多的以分析業(yè)務(wù)數(shù)據(jù)產(chǎn)生的密度高�、價(jià)值高的結(jié)構(gòu)化數(shù)據(jù)為主,對(duì)于非結(jié)構(gòu)化和半結(jié)構(gòu)化數(shù)據(jù)的處理非常乏力��,例如圖片����,文本����,音頻的存儲(chǔ)��,分析�����。
由于數(shù)據(jù)倉(cāng)庫(kù)為結(jié)構(gòu)化存儲(chǔ)���,在數(shù)據(jù)從其他系統(tǒng)進(jìn)入數(shù)據(jù)倉(cāng)庫(kù)這個(gè)東西�����,我們通常叫做ETL過(guò)程�����,ETL動(dòng)作和業(yè)務(wù)進(jìn)行了強(qiáng)綁定,通常需要一個(gè)專門(mén)的ETL團(tuán)隊(duì)去和業(yè)務(wù)做銜接����,決定如何進(jìn)行數(shù)據(jù)的清洗和轉(zhuǎn)換。
隨著異構(gòu)數(shù)據(jù)源的增加�����,例如如果存在視頻,文本��,圖片等數(shù)據(jù)源���,要解析數(shù)據(jù)內(nèi)容進(jìn)入數(shù)據(jù)倉(cāng)庫(kù)����,則需要非常復(fù)雜等ETL程序����,從而導(dǎo)致ETL變得過(guò)于龐大和臃腫。
當(dāng)數(shù)據(jù)量過(guò)大的時(shí)候�,性能會(huì)成為瓶頸,在TB/PB級(jí)別的數(shù)據(jù)量上表現(xiàn)出明顯的吃力�����。
數(shù)據(jù)庫(kù)的范式等約束規(guī)則���,著力于解決數(shù)據(jù)冗余的問(wèn)題�����,是為了保障數(shù)據(jù)的一致性��,但是對(duì)于數(shù)據(jù)倉(cāng)庫(kù)來(lái)說(shuō)���,我們并不需要對(duì)數(shù)據(jù)做修改和一致性的保障�����,原則上來(lái)說(shuō)數(shù)據(jù)倉(cāng)庫(kù)的原始數(shù)據(jù)都是只讀的��,所以這些約束反而會(huì)成為影響性能的因素�。
ETL動(dòng)作對(duì)數(shù)據(jù)的預(yù)先假設(shè)和處理��,導(dǎo)致機(jī)器學(xué)習(xí)部分獲取到的數(shù)據(jù)為假設(shè)后的數(shù)據(jù)��,因此效果不理想��。例如如果需要使用數(shù)據(jù)倉(cāng)庫(kù)進(jìn)行異常數(shù)據(jù)的挖掘���,則在數(shù)據(jù)入庫(kù)經(jīng)過(guò)ETL的時(shí)候就需要明確定義需要提取的特征數(shù)據(jù),否則無(wú)法結(jié)構(gòu)化入庫(kù)����,然而大多數(shù)情況是需要基于異構(gòu)數(shù)據(jù)才能提取出特征��。
在一系列的問(wèn)題下���,以Hadoop體系為首的大數(shù)據(jù)分析平臺(tái)逐漸表現(xiàn)出優(yōu)異性,圍繞Hadoop體系的生態(tài)圈也不斷的變大���,對(duì)于Hadoop系統(tǒng)來(lái)說(shuō)�����,從根本上解決了傳統(tǒng)數(shù)據(jù)倉(cāng)庫(kù)的瓶頸的問(wèn)題��,但是也帶來(lái)一系列的問(wèn)題:
從數(shù)據(jù)倉(cāng)庫(kù)升級(jí)到大數(shù)據(jù)架構(gòu)�����,是不具備平滑演進(jìn)的����,基本等于推翻重做�����。
大數(shù)據(jù)下的分布式存儲(chǔ)強(qiáng)調(diào)數(shù)據(jù)的只讀性質(zhì)��,所以類似于Hive,HDFS這些存儲(chǔ)方式都不支持update��,HDFS的write操作也不支持并行�,這些特性導(dǎo)致其具有一定的局限性。
基于大數(shù)據(jù)架構(gòu)的數(shù)據(jù)分析平臺(tái)側(cè)重于從以下幾個(gè)維度去解決傳統(tǒng)數(shù)據(jù)倉(cāng)庫(kù)做數(shù)據(jù)分析面臨的瓶頸:
分布式計(jì)算:分布式計(jì)算的思路是讓多個(gè)節(jié)點(diǎn)并行計(jì)算�����,并且強(qiáng)調(diào)數(shù)據(jù)本地性��,盡可能的減少數(shù)據(jù)的傳輸��,例如Spark通過(guò)RDD的形式來(lái)表現(xiàn)數(shù)據(jù)的計(jì)算邏輯�����,可以在RDD上做一系列的優(yōu)化�,來(lái)減少數(shù)據(jù)的傳輸。
分布式存儲(chǔ):所謂的分布式存儲(chǔ)�����,指的是將一個(gè)大文件拆成N份����,每一份獨(dú)立的放到一臺(tái)機(jī)器上,這里就涉及到文件的副本���,分片���,以及管理等操作,分布式存儲(chǔ)主要優(yōu)化的動(dòng)作都在這一塊��。
檢索和存儲(chǔ)的結(jié)合:在早期的大數(shù)據(jù)組件中����,存儲(chǔ)和計(jì)算相對(duì)比較單一,但是目前更多的方向是在存儲(chǔ)上做更多的手腳���,讓查詢和計(jì)算更加高效��,對(duì)于計(jì)算來(lái)說(shuō)高效不外乎就是查找數(shù)據(jù)快�,讀取數(shù)據(jù)快�����,所以目前的存儲(chǔ)不單單的存儲(chǔ)數(shù)據(jù)內(nèi)容���,同時(shí)會(huì)添加很多元信息����,例如索引信息。像類似于parquet和carbondata都是這樣的思想�����。
總的來(lái)說(shuō)���,目前圍繞Hadoop體系的大數(shù)據(jù)架構(gòu)大概有以下幾種:
傳統(tǒng)大數(shù)據(jù)架構(gòu)
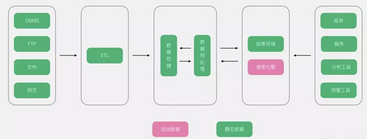
之所以叫傳統(tǒng)大數(shù)據(jù)架構(gòu)��,是因?yàn)槠涠ㄎ皇菫榱私鉀Q傳統(tǒng)BI的問(wèn)題����,簡(jiǎn)單來(lái)說(shuō)����,數(shù)據(jù)分析的業(yè)務(wù)沒(méi)有發(fā)生任何變化,但是因?yàn)閿?shù)據(jù)量�����、性能等問(wèn)題導(dǎo)致系統(tǒng)無(wú)法正常使用��,需要進(jìn)行升級(jí)改造,那么此類架構(gòu)便是為了解決這個(gè)問(wèn)題��??梢钥吹?,其依然保留了ETL的動(dòng)作,將數(shù)據(jù)經(jīng)過(guò)ETL動(dòng)作進(jìn)入數(shù)據(jù)存儲(chǔ)��。
優(yōu)點(diǎn):簡(jiǎn)單�����,易懂���,對(duì)于BI系統(tǒng)來(lái)說(shuō)��,基本思想沒(méi)有發(fā)生變化��,變化的僅僅是技術(shù)選型�����,用大數(shù)據(jù)架構(gòu)替換掉BI的組件��。
缺點(diǎn):對(duì)于大數(shù)據(jù)來(lái)說(shuō)�,沒(méi)有BI下如此完備的Cube架構(gòu),雖然目前有kylin����,但是kylin的局限性非常明顯,遠(yuǎn)遠(yuǎn)沒(méi)有BI下的Cube的靈活度和穩(wěn)定度�,因此對(duì)業(yè)務(wù)支撐的靈活度不夠,所以對(duì)于存在大量報(bào)表�����,或者復(fù)雜的鉆取的場(chǎng)景�����,需要太多的手工定制化��,同時(shí)該架構(gòu)依舊以批處理為主�,缺乏實(shí)時(shí)的支撐。
適用場(chǎng)景:數(shù)據(jù)分析需求依舊以BI場(chǎng)景為主�����,但是因?yàn)閿?shù)據(jù)量�、性能等問(wèn)題無(wú)法滿足日常使用。
流式架構(gòu)
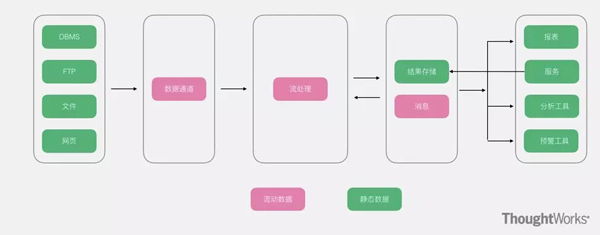
在傳統(tǒng)大數(shù)據(jù)架構(gòu)的基礎(chǔ)上��,流式架構(gòu)非常激進(jìn),直接拔掉了批處理���,數(shù)據(jù)全程以流的形式處理��,所以在數(shù)據(jù)接入端沒(méi)有了ETL����,轉(zhuǎn)而替換為數(shù)據(jù)通道��。經(jīng)過(guò)流處理加工后的數(shù)據(jù)�����,以消息的形式直接推送給了消費(fèi)者�����。雖然有一個(gè)存儲(chǔ)部分��,但是該存儲(chǔ)更多的以窗口的形式進(jìn)行存儲(chǔ)�,所以該存儲(chǔ)并非發(fā)生在數(shù)據(jù)湖����,而是在外圍系統(tǒng)�。
優(yōu)點(diǎn):沒(méi)有臃腫的ETL過(guò)程�,數(shù)據(jù)的實(shí)效性非常高。
缺點(diǎn):對(duì)于流式架構(gòu)來(lái)說(shuō)��,不存在批處理���,因此對(duì)于數(shù)據(jù)的重播和歷史統(tǒng)計(jì)無(wú)法很好的支撐�。對(duì)于離線分析僅僅支撐窗口之內(nèi)的分析�。
適用場(chǎng)景:預(yù)警,監(jiān)控���,對(duì)數(shù)據(jù)有有效期要求的情況��。
Lambda架構(gòu)
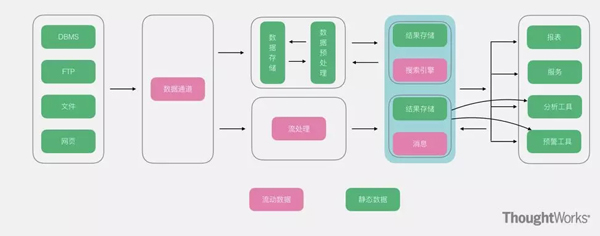
Lambda架構(gòu)算是大數(shù)據(jù)系統(tǒng)里面舉足輕重的架構(gòu)�,大多數(shù)架構(gòu)基本都是Lambda架構(gòu)或者基于其變種的架構(gòu)�。Lambda的數(shù)據(jù)通道分為兩條分支:實(shí)時(shí)流和離線。實(shí)時(shí)流依照流式架構(gòu)�����,保障了其實(shí)時(shí)性����,而離線則以批處理方式為主���,保障了最終一致性。什么意思呢?流式通道處理為保障實(shí)效性更多的以增量計(jì)算為主輔助參考���,而批處理層則對(duì)數(shù)據(jù)進(jìn)行全量運(yùn)算���,保障其最終的一致性,因此Lambda最外層有一個(gè)實(shí)時(shí)層和離線層合并的動(dòng)作�,此動(dòng)作是Lambda里非常重要的一個(gè)動(dòng)作,大概的合并思路如下:
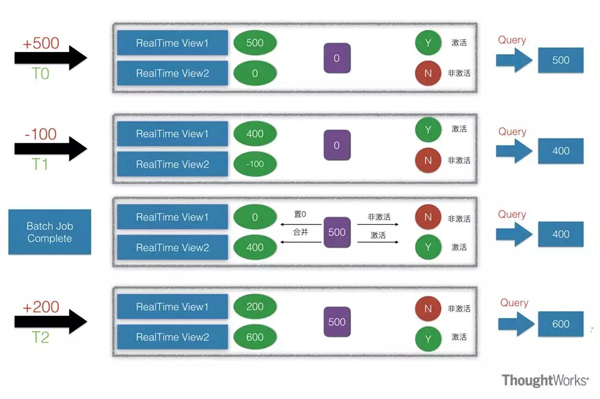
優(yōu)點(diǎn):既有實(shí)時(shí)又有離線�����,對(duì)于數(shù)據(jù)分析場(chǎng)景涵蓋的非常到位����。
缺點(diǎn):離線層和實(shí)時(shí)流雖然面臨的場(chǎng)景不相同�,但是其內(nèi)部處理的邏輯卻是相同,因此有大量榮譽(yù)和重復(fù)的模塊存在�。
適用場(chǎng)景:同時(shí)存在實(shí)時(shí)和離線需求的情況。
Kappa架構(gòu)
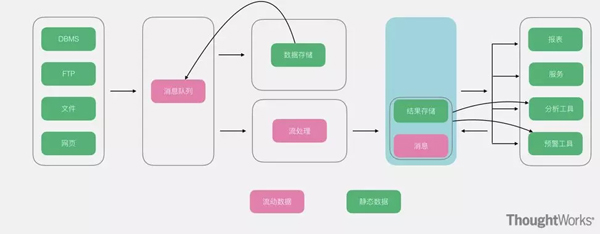
Kappa架構(gòu)在Lambda
的基礎(chǔ)上進(jìn)行了優(yōu)化����,將實(shí)時(shí)和流部分進(jìn)行了合并���,將數(shù)據(jù)通道以消息隊(duì)列進(jìn)行替代。因此對(duì)于Kappa架構(gòu)來(lái)說(shuō)�,依舊以流處理為主,但是數(shù)據(jù)卻在數(shù)據(jù)湖層面進(jìn)行了存儲(chǔ)����,當(dāng)需要進(jìn)行離線分析或者再次計(jì)算的時(shí)候,則將數(shù)據(jù)湖的數(shù)據(jù)再次經(jīng)過(guò)消息隊(duì)列重播一次則可�。
優(yōu)點(diǎn):Kappa架構(gòu)解決了Lambda架構(gòu)里面的冗余部分,以數(shù)據(jù)可重播的超凡脫俗的思想進(jìn)行了設(shè)計(jì)�,整個(gè)架構(gòu)非常簡(jiǎn)潔。
缺點(diǎn):雖然Kappa架構(gòu)看起來(lái)簡(jiǎn)潔�����,但是施難度相對(duì)較高��,尤其是對(duì)于數(shù)據(jù)重播部分�����。
適用場(chǎng)景:和Lambda類似�����,改架構(gòu)是針對(duì)Lambda的優(yōu)化。
Unifield架構(gòu)
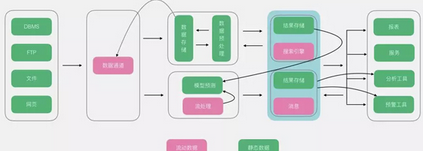
以上的種種架構(gòu)都圍繞海量數(shù)據(jù)處理為主���,Unifield架構(gòu)則更激進(jìn)�����,將機(jī)器學(xué)習(xí)和數(shù)據(jù)處理揉為一體���,從核心上來(lái)說(shuō),Unifield依舊以Lambda為主�,不過(guò)對(duì)其進(jìn)行了改造,在流處理層新增了機(jī)器學(xué)習(xí)層��?��?梢钥吹綌?shù)據(jù)在經(jīng)過(guò)數(shù)據(jù)通道進(jìn)入數(shù)據(jù)湖后,新增了模型訓(xùn)練部分����,并且將其在流式層進(jìn)行使用。同時(shí)流式層不單使用模型�,也包含著對(duì)模型的持續(xù)訓(xùn)練。
優(yōu)點(diǎn):Unifield架構(gòu)提供了一套數(shù)據(jù)分析和機(jī)器學(xué)習(xí)結(jié)合的架構(gòu)方案��,非常好的解決了機(jī)器學(xué)習(xí)如何與數(shù)據(jù)平臺(tái)進(jìn)行結(jié)合的問(wèn)題。
缺點(diǎn):Unifield架構(gòu)實(shí)施復(fù)雜度更高���,對(duì)于機(jī)器學(xué)習(xí)架構(gòu)來(lái)說(shuō)��,從軟件包到硬件部署都和數(shù)據(jù)分析平臺(tái)有著非常大的差別��,因此在實(shí)施過(guò)程中的難度系數(shù)更高����。
適用場(chǎng)景:有著大量數(shù)據(jù)需要分析��,同時(shí)對(duì)機(jī)器學(xué)習(xí)方便又有著非常大的需求或者有規(guī)劃��。
總結(jié)
以上幾種架構(gòu)為目前數(shù)據(jù)處理領(lǐng)域使用比較多的幾種架構(gòu)�,當(dāng)然還有非常多其他架構(gòu),不過(guò)其思想都會(huì)或多或少的類似��。數(shù)據(jù)領(lǐng)域和機(jī)器學(xué)習(xí)領(lǐng)域會(huì)持續(xù)發(fā)展���,以上幾種思想或許終究也會(huì)變得過(guò)時(shí)�。
CDA數(shù)據(jù)分析師考試相關(guān)入口一覽(建議收藏):
? 想報(bào)名CDA認(rèn)證考試�,點(diǎn)擊>>>
“CDA報(bào)名”
了解CDA考試詳情;
? 想學(xué)習(xí)CDA考試教材,點(diǎn)擊>>> “CDA教材” 了解CDA考試詳情�����;
? 想加入CDA考試題庫(kù)�,點(diǎn)擊>>> “CDA題庫(kù)” 了解CDA考試詳情;
? 想了解CDA考試含金量�����,點(diǎn)擊>>> “CDA含金量” 了解CDA考試詳情�;











 京公網(wǎng)安備 11010802034615號(hào)
經(jīng)營(yíng)許可證編號(hào):京B2-20210330
京公網(wǎng)安備 11010802034615號(hào)
經(jīng)營(yíng)許可證編號(hào):京B2-20210330