深度學習入門課程筆記 神經(jīng)網(wǎng)絡
神經(jīng)網(wǎng)絡:

首先咱們先來回顧一下之前課程所講前向傳播和反向傳播知識點���,前往傳播就是從輸入X到最終得到LOSS值的過程,反向傳播是從最終的LOSS值經(jīng)過梯度的傳播最終計算出權重矩陣W中所有參數(shù)對于最終的LOSS值影響大小���,更新參數(shù)就是通過不同權重參數(shù)對終LOSS值的影響來調節(jié)參數(shù)����,使得咱們的參數(shù)矩陣W能夠更擬合咱們的數(shù)據(jù)���,也就是使得最終的LOSS值能夠降低�����。這一系列的過程就是相當于完成了一次迭代
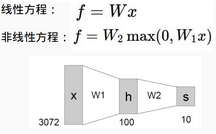
下面咱們就來看看神經(jīng)網(wǎng)絡跟傳統(tǒng)的線性分類到底有什么區(qū)別��,從公式中我們可以看出����,一個最明顯的區(qū)別就是神經(jīng)網(wǎng)絡函數(shù)多了一個MAX()計算也就是說我們咱們現(xiàn)在的函數(shù)公式變成了一個非線性的操作,也正是這種非線性的函數(shù)使得神經(jīng)網(wǎng)絡相比于傳統(tǒng)的線性分類更強大���,因為非線性可以使得咱們的函數(shù)去擬合更復雜的數(shù)據(jù)��。
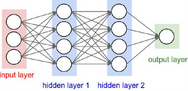
接下來咱們就來看一下神經(jīng)網(wǎng)絡的結構���,從途中可以看出,神經(jīng)網(wǎng)絡是一個層次的結構
輸入層也就是代表著數(shù)據(jù)源
隱層這個大家理解起來可能有些費勁����,咱們可以把隱層當成是中間層也就是在這里對輸入數(shù)據(jù)進行了非線性的變換
激活函數(shù)它是跟隱層在一起的,比如這個MAX()函數(shù)就是一個激活函數(shù)���,正是因為激活函數(shù)的存在才使得整個神經(jīng)網(wǎng)絡呈現(xiàn)出一種非線性的模式���。
輸出層這個就是最終得到的結果了�,比如一個分類任務��,最終的輸出就是每個類別的概率值了
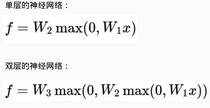
我們可以看到對應于多層的網(wǎng)絡也就是有多個隱層����,相當于咱們又加了一層非線性函數(shù)MAX()�,這個理解起來很簡單了吧,對于深層網(wǎng)絡來說��,它具有更好的非線性也就是說網(wǎng)絡的層數(shù)越深就更能夠去擬合更復雜的數(shù)據(jù)����。
生物學上的結構
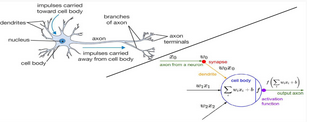
看過很多講解都提高了把神經(jīng)網(wǎng)絡和人類的腦結構相對比,我覺得這有些增加了游戲難度����,因為很多同學本身對生物學結構就不是很清楚,又搞了這多名詞出來��,理解起來好像更費勁了�,這里咱們就不說生物學結構了,直接看右半部分����,和之前的線性分類最大的區(qū)別就是我們多了一個activation
function也就是咱們剛才所說的激活函數(shù)���,可以說正是激活函數(shù)的存在使得整個神經(jīng)網(wǎng)絡變得強大起來。
神經(jīng)元
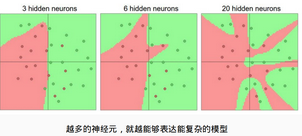
那么神經(jīng)網(wǎng)絡能表達多復雜的數(shù)據(jù)信息是由什么決定的呢��?這個例子給了咱們很好的解釋����,神經(jīng)網(wǎng)絡是表達能力是由神經(jīng)元的個數(shù),也就是每一個隱層所函數(shù)神經(jīng)元的個數(shù)來決定的�,神經(jīng)元越多,層數(shù)越深表達的能力也就越強��,理論上我們認為神經(jīng)元越多越好����!
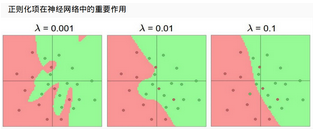
咱們剛才說了神經(jīng)網(wǎng)絡具有很強的表達能力,但是也很危險的�����,就是說神經(jīng)網(wǎng)絡很容易發(fā)成過擬合現(xiàn)象���,因為咱們有大量的神經(jīng)元也就是導致了我們需要的參數(shù)是極其多的����,那么該怎么辦呢?最直接的方法就是加上正則化項���,它可以使得咱們的神經(jīng)網(wǎng)絡不至于過擬合很嚴重也是咱們訓練神經(jīng)網(wǎng)絡必做的一項�,圖中顯示了正則化的作用��!
CDA數(shù)據(jù)分析師考試相關入口一覽(建議收藏):
? 想報名CDA認證考試�����,點擊>>>
“CDA報名”
了解CDA考試詳情��;
? 想學習CDA考試教材��,點擊>>> “CDA教材” 了解CDA考試詳情����;
? 想加入CDA考試題庫����,點擊>>> “CDA題庫” 了解CDA考試詳情;
? 想了解CDA考試含金量,點擊>>> “CDA含金量” 了解CDA考試詳情���;











 京公網(wǎng)安備 11010802034615號
經(jīng)營許可證編號:京B2-20210330
京公網(wǎng)安備 11010802034615號
經(jīng)營許可證編號:京B2-20210330