機(jī)器學(xué)習(xí)中的數(shù)據(jù)不平衡解決方案大全
在機(jī)器學(xué)習(xí)任務(wù)中,我們經(jīng)常會(huì)遇到這種困擾:數(shù)據(jù)不平衡問題��。
數(shù)據(jù)不平衡問題主要存在于有監(jiān)督機(jī)器學(xué)習(xí)任務(wù)中�����。當(dāng)遇到不平衡數(shù)據(jù)時(shí),以總體分類準(zhǔn)確率為學(xué)習(xí)目標(biāo)的傳統(tǒng)分類算法會(huì)過多地關(guān)注多數(shù)類����,從而使得少數(shù)類樣本的分類性能下降。絕大多數(shù)常見的機(jī)器學(xué)習(xí)算法對(duì)于不平衡數(shù)據(jù)集都不能很好地工作����。
本文介紹幾種有效的解決數(shù)據(jù)不平衡情況下有效訓(xùn)練有監(jiān)督算法的思路:
1、重新采樣訓(xùn)練集
可以使用不同的數(shù)據(jù)集��。有兩種方法使不平衡的數(shù)據(jù)集來建立一個(gè)平衡的數(shù)據(jù)集——欠采樣和過采樣�����。
1.1. 欠采樣
欠采樣是通過減少豐富類的大小來平衡數(shù)據(jù)集�,當(dāng)數(shù)據(jù)量足夠時(shí)就該使用此方法����。通過保存所有稀有類樣本���,并在豐富類別中隨機(jī)選擇與稀有類別樣本相等數(shù)量的樣本,可以檢索平衡的新數(shù)據(jù)集以進(jìn)一步建模���。
1.2. 過采樣
相反���,當(dāng)數(shù)據(jù)量不足時(shí)就應(yīng)該使用過采樣,它嘗試通過增加稀有樣本的數(shù)量來平衡數(shù)據(jù)集��,而不是去除豐富類別的樣本的數(shù)量���。通過使用重復(fù)�����、自舉或合成少數(shù)類過采樣等方法(SMOTE)來生成新的稀有樣品�����。
注意到欠采樣和過采樣這兩種方法相比而言�,都沒有絕對(duì)的優(yōu)勢(shì)���。這兩種方法的應(yīng)用取決于它適用的用例和數(shù)據(jù)集本身����。另外將過采樣和欠采樣結(jié)合起來使用也是成功的�。
2����、使用K-fold交叉驗(yàn)證
值得注意的是�����,使用過采樣方法來解決不平衡問題時(shí)應(yīng)適當(dāng)?shù)貞?yīng)用交叉驗(yàn)證�。這是因?yàn)?a href='/map/guocaiyang/' style='color:#000;font-size:inherit;'>過采樣會(huì)觀察到罕見的樣本,并根據(jù)分布函數(shù)應(yīng)用自舉生成新的隨機(jī)數(shù)據(jù)��,如果在過采樣之后應(yīng)用交叉驗(yàn)證��,那么我們所做的就是將我們的模型過擬合于一個(gè)特定的人工引導(dǎo)結(jié)果����。這就是為什么在過度采樣數(shù)據(jù)之前應(yīng)該始終進(jìn)行交叉驗(yàn)證,就像實(shí)現(xiàn)特征選擇一樣��。只有重復(fù)采樣數(shù)據(jù)可以將隨機(jī)性引入到數(shù)據(jù)集中�����,以確保不會(huì)出現(xiàn)過擬合問題���。
K-fold交叉驗(yàn)證就是把原始數(shù)據(jù)隨機(jī)分成K個(gè)部分��,在這K個(gè)部分中選擇一個(gè)作為測(cè)試數(shù)據(jù)���,剩余的K-1個(gè)作為訓(xùn)練數(shù)據(jù)�����。交叉驗(yàn)證的過程實(shí)際上是將實(shí)驗(yàn)重復(fù)做K次�����,每次實(shí)驗(yàn)都從K個(gè)部分中選擇一個(gè)不同的部分作為測(cè)試數(shù)據(jù),剩余的數(shù)據(jù)作為訓(xùn)練數(shù)據(jù)進(jìn)行實(shí)驗(yàn)���,最后把得到的K個(gè)實(shí)驗(yàn)結(jié)果平均�����。
3���、轉(zhuǎn)化為一分類問題
對(duì)于二分類問題,如果正負(fù)樣本分布比例極不平衡�����,我們可以換一個(gè)完全不同的角度來看待問題:把它看做一分類(One Class
Learning)或異常檢測(cè)(Novelty
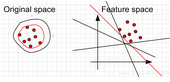
Detection)問題。這類方法的重點(diǎn)不在于捕捉類間的差別��,而是為其中一類進(jìn)行建模����,經(jīng)典的工作包括One-class SVM等,如下圖所示:
One
Class SVM 是指你的訓(xùn)練數(shù)據(jù)只有一類正(或者負(fù))樣本的數(shù)據(jù)���,
而沒有另外的一類��。在這時(shí),你需要學(xué)習(xí)的實(shí)際上你訓(xùn)練數(shù)據(jù)的邊界�����。而這時(shí)不能使用最大化軟邊緣了�����,因?yàn)槟銢]有兩類的數(shù)據(jù)���。
所以呢��,在這邊文章中����,“Estimating the support of a high-dimensional
distribution”,Sch?lkopf假設(shè)最好的邊緣要遠(yuǎn)離特征空間中的原點(diǎn)���。左邊是在原始空間中的邊界�����,可以看到有很多的邊界都符合要求�,但是比較靠譜的是找一個(gè)比較緊的邊界(紅色的)�。這個(gè)目標(biāo)轉(zhuǎn)換到特征空間就是找一個(gè)離原點(diǎn)比較遠(yuǎn)的邊界����,同樣是紅色的直線。當(dāng)然這些約束條件都是人為加上去的����,你可以按照你自己的需要采取相應(yīng)的約束條件。比如讓你data
的中心離原點(diǎn)最遠(yuǎn)����。
說明:對(duì)于正負(fù)樣本極不均勻的問題,使用異常檢測(cè),或者一分類問題��,也是一個(gè)思路�����。
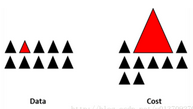
4�、組合不同的重采樣數(shù)據(jù)集
成功泛化模型的最簡(jiǎn)單方法是使用更多的數(shù)據(jù),問題是像邏輯回歸或隨機(jī)森林這樣開箱即用的分類器�,傾向于通過舍去稀有類來泛化模型。一個(gè)簡(jiǎn)單的最佳實(shí)踐是建立n個(gè)模型����,每個(gè)模型使用稀有類別的所有樣本和豐富類別的n個(gè)不同樣本。假設(shè)想要合并10個(gè)模型�,那么將保留例如1000例稀有類別,并隨機(jī)抽取10000例豐富類別����。然后,只需將10000個(gè)案例分成10塊���,并訓(xùn)練10個(gè)不同的模型����。
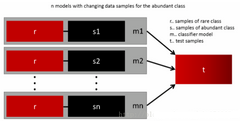
如果擁有大量數(shù)據(jù),這種方法是簡(jiǎn)單并且是可橫向擴(kuò)展的�����,這是因?yàn)榭梢栽诓煌募汗?jié)點(diǎn)上訓(xùn)練和運(yùn)行模型����。集合模型也趨于泛化,這使得該方法易于處理����。
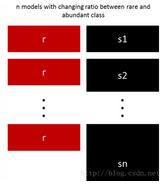
5、用不同比例重新采樣
方法4可以很好地將稀有類別和豐富類別之間的比例進(jìn)行微調(diào)���,最好的比例在很大程度上取決于所使用的數(shù)據(jù)和模型�。但是��,不是在整體中以相同的比例訓(xùn)練所有模型�����,所以值得嘗試合并不同的比例���。如果10個(gè)模型被訓(xùn)練���,有一個(gè)模型比例為1:1(稀有:豐富)和另一個(gè)1:3甚至是2:1的模型都是有意義的。一個(gè)類別獲得的權(quán)重依賴于使用的模型��。
6�、多模型Bagging
方法5雖然能夠選出最好的樣本數(shù)據(jù)比例。但是它的魯棒性不能夠保證:它的魯棒性取決于測(cè)試集樣本的選取����。
為了解決上述方法的缺陷,增加模型魯棒性����。為此,我本人在隨機(jī)森林算法思想的啟發(fā)下��,想出了在上述方法的基礎(chǔ)上����,將不同比例下訓(xùn)練出來的模型進(jìn)行多模型Bagging操作,具體的步驟如下:
-
對(duì)兩類樣本選取N組不同比例的數(shù)據(jù)進(jìn)行訓(xùn)練并測(cè)試��,得出模型預(yù)測(cè)的準(zhǔn)確率:
-
對(duì)上述各模型的準(zhǔn)確率進(jìn)行歸一化處理�����,得到新的權(quán)重分布:
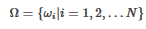
其中:
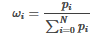
按權(quán)重分布Ω
組合多個(gè)模型,作為最終的訓(xùn)練器:
對(duì)于分類任務(wù):
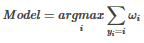
對(duì)于回歸任務(wù):
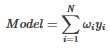
7���、集群豐富類
Sergey Quora提出了一種優(yōu)雅的方法�����,他建議不要依賴隨機(jī)樣本來覆蓋訓(xùn)練樣本的種類����,而是將r個(gè)群體中豐富類別進(jìn)行聚類�����,其中r為r中的例數(shù)�����。每個(gè)組只保留集群中心(medoid)��。然后����,基于稀有類和僅保留的類別對(duì)該模型進(jìn)行訓(xùn)練����。
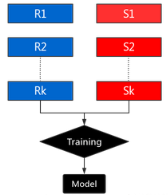
7.1. 對(duì)豐富類進(jìn)行聚類操作
首先�����,我們可以對(duì)具有大量樣本的豐富類進(jìn)行聚類操作����。假設(shè)我們使用的方法是K-Means聚類算法�。此時(shí),我們可以選擇K值為稀有類中的數(shù)據(jù)樣本的個(gè)數(shù)�����,并將聚類后的中心點(diǎn)以及相應(yīng)的聚類中心當(dāng)做富類樣本的代表樣例��,類標(biāo)與富類類標(biāo)一致���。
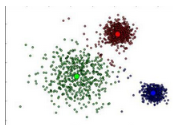
7.2. 聚類后的樣本進(jìn)行有監(jiān)督學(xué)習(xí)
經(jīng)過上述步驟的聚類操作�����,我們對(duì)富類訓(xùn)練樣本進(jìn)行了篩選����,接下來我們就可以將相等樣本數(shù)的K個(gè)正負(fù)樣本進(jìn)行有監(jiān)督訓(xùn)練。如下圖所示:
8����、設(shè)計(jì)適用于不平衡數(shù)據(jù)集的模型
所有之前的方法都集中在數(shù)據(jù)上,并將模型保持為固定的組件�����。但事實(shí)上��,如果設(shè)計(jì)的模型適用于不平衡數(shù)據(jù)���,則不需要重新采樣數(shù)據(jù)�����,著名的XGBoost已經(jīng)是一個(gè)很好的起點(diǎn)��,因此設(shè)計(jì)一個(gè)適用于不平衡數(shù)據(jù)集的模型也是很有意義的����。
通過設(shè)計(jì)一個(gè)代價(jià)函數(shù)來懲罰稀有類別的錯(cuò)誤分類而不是分類豐富類別�����,可以設(shè)計(jì)出許多自然泛化為稀有類別的模型�。例如,調(diào)整SVM以懲罰稀有類別的錯(cuò)誤分類����。
CDA數(shù)據(jù)分析師考試相關(guān)入口一覽(建議收藏):
? 想報(bào)名CDA認(rèn)證考試,點(diǎn)擊>>>
“CDA報(bào)名”
了解CDA考試詳情����;
? 想學(xué)習(xí)CDA考試教材,點(diǎn)擊>>> “CDA教材” 了解CDA考試詳情���;
? 想加入CDA考試題庫(kù)��,點(diǎn)擊>>> “CDA題庫(kù)” 了解CDA考試詳情�����;
? 想了解CDA考試含金量���,點(diǎn)擊>>> “CDA含金量” 了解CDA考試詳情;











 京公網(wǎng)安備 11010802034615號(hào)
經(jīng)營(yíng)許可證編號(hào):京B2-20210330
京公網(wǎng)安備 11010802034615號(hào)
經(jīng)營(yíng)許可證編號(hào):京B2-20210330