房屋價格數(shù)據(jù)采集與分析
隨著互聯(lián)網(wǎng)的發(fā)展,可供分析的信息越來越多�����,利用互聯(lián)網(wǎng)上的信息來對生活中的問題做一些簡單的研究分析,變得越來越便利了�。本文就從數(shù)據(jù)采集�、數(shù)據(jù)清洗�、數(shù)據(jù)分析與可視化三部分來看看新的一年里房市的一些問題。
數(shù)據(jù)采集:
數(shù)據(jù)采集即從網(wǎng)頁上采集我們需要的指定信息��,一般使用爬蟲實現(xiàn)��。當(dāng)前開源的爬蟲非常多���,處于簡便及學(xué)習(xí)的目的,在此使用python的urllib2庫模擬http訪問網(wǎng)頁���,并BeautifulSoup解析網(wǎng)頁獲取指定的字段信息�。本人獲取的鏈家網(wǎng)上的新房和二手房數(shù)據(jù)����,先來看看原始網(wǎng)頁的結(jié)構(gòu):
首先是URL,不管是新房還是二手房���,鏈家網(wǎng)的房產(chǎn)數(shù)據(jù)都是以列表的方式存在���,比較容易獲取,如下圖:
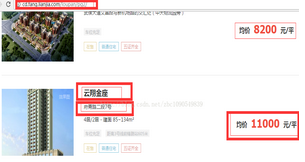
其中包含的信息有樓盤名稱�、地址��、價格等信息��,回到原始網(wǎng)頁�����,看看在html中�,這些信息都在什么地方��,如下圖:
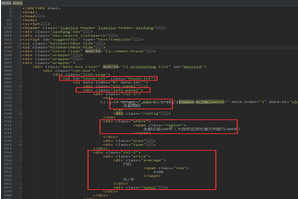
值得注意的是�����,原始的html為了節(jié)省傳輸帶寬一般是經(jīng)過壓縮的,不太方便分析��,可以借助一些html格式化工具進(jìn)行處理再分析���。知道這些信息后�����,就可以模擬http請求來拉取html網(wǎng)頁并使用BeautifulSoup提取指定的字段了。
fw = open("./chengdu.txt","a+")
index = [i+1 for i in range(32)]
for pa in index:
try:
if pa==1:
url = "http://cd.fang.lianjia.com/loupan/"
else:
url = "http://cd.fang.lianjia.com/loupan/pg%d/"%(pa)
print "request:"+url
req = urllib2.Request( url )
req.add_header("User-Agent","Mozilla/5.0 (Windows NT 6.1;
WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/45.0.2454.101
Safari/537.36")
req.add_header("Accept","*/*")
req.add_header("Accept-Language","zh-CN,zh;q=0.8")
data = urllib2.urlopen( req )
res = data.read()
#print res
#res = res.replace(" ","")
#print res
#objects = demjson.decode(res)
soup = BeautifulSoup(res)
houseLst = soup.findAll(id='house-lst')
resp = soup.findAll('div', attrs = {'class': 'info-panel'})
for i in range(len(resp)):
name = resp[i].findAll('a', attrs = {'target': '_blank'})[0].text
privice = resp[i].findAll('span', attrs = {'class': 'num'})
privice = privice[0].text
region = resp[i].findAll('span', attrs = {'class': 'region'})
address = region[0].text.split('(')[0]
##解析獲得經(jīng)緯度
location,city,district = getGdLocation(name)
if not location:
location = getBdLocation(address)#自定義函數(shù)
if not location:
continue
formatStr = "%s,%s,%s,%s,%s\n"%(city,district,name,location,privice)
print formatStr
fw.write(formatStr)
except:
pass
fw.close()
數(shù)據(jù)清洗:
數(shù)據(jù)清洗��,顧名思義就是將不合規(guī)的數(shù)據(jù)清理掉,留下可供我們能夠正確分析的數(shù)據(jù)��,至于哪些數(shù)據(jù)需要清理掉����,則和我們最終的分析目標(biāo)有一定的關(guān)系�����,可謂仁者見仁智者見智了�����。在這里�,由于是基于地理位置做的一個統(tǒng)計分析���,顯然爬取的地理位置必須是準(zhǔn)確的才行����。但由于售房者填寫的地址和樓盤名稱可能有誤���,如何將這些有誤的識別出來成為這里數(shù)據(jù)清洗成敗的關(guān)鍵�。我們清洗錯誤地理位置的邏輯是:使用高德地圖的地理位置逆編碼接口(地理位置逆編碼即將地理名稱解析成經(jīng)緯度)獲得樓盤名稱和樓盤地址��。對應(yīng)的經(jīng)緯度,計算二者對應(yīng)的經(jīng)緯度之間的距離��,如果距離值超過一定的閥值��,則認(rèn)為地址標(biāo)注有誤或者地址標(biāo)注不明確����。經(jīng)過清洗后�,獲取到的成都地區(qū)的在售樓盤及房屋數(shù)量總計在3000套的樣子���。
經(jīng)過清洗后的數(shù)據(jù)格式為:
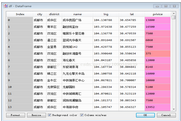
包括市、區(qū)�����、樓盤/房屋名稱�����、經(jīng)緯度����、價格四個維度。
數(shù)據(jù)分析與可視化:
首先是新推樓盤掛牌價格與銷售價格
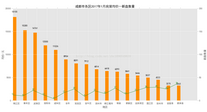
市中心依然遵循了寸獨存金的原則,銷售價格遠(yuǎn)遠(yuǎn)高于郊縣,一方面原因是位置地段����、配套的獨特性�����,一方面也是由于可供銷售的土地面積���、樓盤數(shù)量極為有限��。
二手房銷售價格和掛牌數(shù)量

二手房交易重要集中在市區(qū)及一些經(jīng)濟(jì)比較發(fā)達(dá)的郊縣�����,不同區(qū)縣的價格分化并不大��,可能原因是老城區(qū)銷售的二手房存在一部分老房子��、同時二手房的價格賣家寫的比較隨意��。
二手房數(shù)據(jù)的箱型圖

這個就更為明顯的印證了上面的結(jié)論��,主城區(qū)的二手房存在一部分價格遠(yuǎn)低于市場均價的(即老房子),也有一部分價格昂貴的(新房、豪宅)出售���,郊縣的價格均方差則會低很多��。
房屋銷售熱度的空間可視化
房屋銷售熱度以該區(qū)域的房屋銷售數(shù)量和房屋銷售價格綜合來衡量�����,計算方式以該區(qū)域銷售的房屋數(shù)量及銷售價格進(jìn)行加權(quán)���。
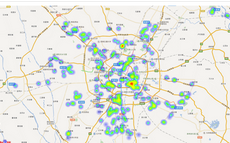
新房銷售熱度
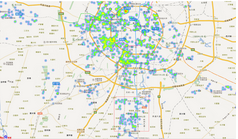
二手房銷售熱度
主城區(qū)沒什么好說的了,人口密度大�����、買房售房的都多。在南邊有一塊遠(yuǎn)離市區(qū)的地方�、新房和二手房的交易熱度都很高��,即成都市天府新區(qū)��,目前配套和各項設(shè)施都不太完善����,去這里花高價買房安家的老百姓想必不會太多����,猜測是去年炒房熱過年,這些人現(xiàn)在開始出售房屋了。
CDA數(shù)據(jù)分析師考試相關(guān)入口一覽(建議收藏):
? 想報名CDA認(rèn)證考試,點擊>>>
“CDA報名”
了解CDA考試詳情���;
? 想學(xué)習(xí)CDA考試教材,點擊>>> “CDA教材” 了解CDA考試詳情�����;
? 想加入CDA考試題庫,點擊>>> “CDA題庫” 了解CDA考試詳情;
? 想了解CDA考試含金量,點擊>>> “CDA含金量” 了解CDA考試詳情;











 京公網(wǎng)安備 11010802034615號
經(jīng)營許可證編號:京B2-20210330
京公網(wǎng)安備 11010802034615號
經(jīng)營許可證編號:京B2-20210330