用Python爬蟲獲取自己感興趣的博客文章
在CSDN上有很多精彩的技術(shù)博客文章���,我們可以把它爬取下來���,保存在本地磁盤�����,可以很方便以后閱讀和學(xué)習(xí)�,現(xiàn)在我們就用python編寫一段爬蟲代碼�����,來實現(xiàn)這個目的�。
我們想要做的事情:自動讀取博客文章,記錄標(biāo)題��,把心儀的文章保存到個人電腦硬盤里供以后學(xué)習(xí)參考�����。
過程大體分為以下幾步:
1. 找到爬取的目標(biāo)網(wǎng)址�����;
2. 分析網(wǎng)頁���,找到自已想要保存的信息,這里我們主要保存是博客的文章內(nèi)容;
3. 清洗整理爬取下來的信息���,保存在本地磁盤����。
打開csdn的網(wǎng)頁����,作為一個示例,我們隨機(jī)打開一個網(wǎng)頁:
http://blog.csdn.net/u013088062/article/list/1���。
可以看到��,博主對《C++卷積神經(jīng)網(wǎng)絡(luò)》和其它有關(guān)機(jī)計算機(jī)方面的文章都寫得不錯���。
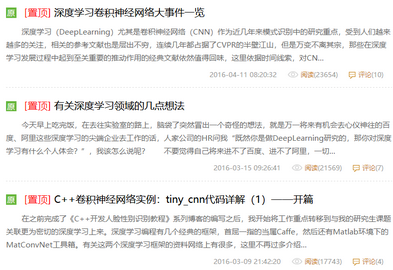
爬蟲代碼按思路分為三個類(class),下面3個帶“#”的分別給出了每一個類的開頭(具體代碼附后����,供大家實際運(yùn)行實現(xiàn)):

采用“類(class)”的方式屬于Python的面向?qū)ο缶幊蹋谀承r候比我們通常使用的面向過程的編程方便�,在大型工程中經(jīng)常使用面向?qū)ο缶幊獭τ诔鯇W(xué)者來說����,面向?qū)ο缶幊滩灰渍莆?����,但是?jīng)過學(xué)習(xí)習(xí)慣之后����,會逐步慢慢從面向過程到面向?qū)ο缶幊踢^渡����。
特別注意的是,RePage類主要用正則表達(dá)式處理從網(wǎng)頁中獲取的信息�,正則表達(dá)式設(shè)置字符串樣式如下:

用正則表達(dá)式去匹配所要爬取的內(nèi)容,用Python和其它軟件工具都可以實現(xiàn)��。正則表達(dá)式有許多規(guī)則�����,各個軟件使用起來大同小異����。用好正則表達(dá)式是爬蟲和文本挖掘的一個重要內(nèi)容���。
SaveText類則是把信息保存在本地�����,效果如下:
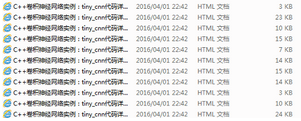
用python編寫爬蟲代碼�����,簡潔高效���。這篇文章僅從爬蟲最基本的用法做了講解���,有興趣的朋友可以下載代碼看看,希望大家從中有收獲�����。
附相關(guān)Python代碼:
1#-*-coding:UTF-8-*-
2import re
3import urllib2
4import sys
5#目的:讀取博客文章�����,記錄標(biāo)題���,用Htnl格式保存存文章內(nèi)容
6#版本:python2.7.13
7#功能:讀取網(wǎng)頁內(nèi)容
8class GetHtmlPage():
9 #注意大小寫
10 def __init__(self,strPage):
11 self.strPapge = strPage
12 #獲取網(wǎng)頁
13 def GetPage(self):
14 req = urllib2.Request(self.strPapge) # 建立頁面請求
15 rep = req.add_header("User-Agent","Mozilla/5.0
(Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko)
Chrome/38.0.2125.122 Safari/537.36 SE 2.X MetaSr 1.0")
16 try:
17 cn = urllib2.urlopen(req) #網(wǎng)頁請求
18 page = cn.read() #讀網(wǎng)頁
19 uPage = page.decode("utf-8") #網(wǎng)頁編碼
20 cn.close()
21 return uPage
22 except urllib2.URLError, e: #捕獲異常
23 print 'URLError:', e.code
24 return
25 except urllib2.HTTPError, e: #捕獲異常
26 print 'HTTP Error:' + e.reason
27 return
28 return rePage
29#正則表達(dá)式�����,獲取想要的內(nèi)容
30class RePage():
31#正則表達(dá)式提取內(nèi)容�����,返回鏈表
32 def GetReText(self,page,recode):
33 rePage = re.findall(recode,page,re.S)
34 return rePage
35#保存文本
36class SaveText():
37 def Save(self,text,tilte):
38 try:
39 t="blog\\"+tilte+".html"
40 f = file(t,"a")
41 f.write(text)
42 f.close()
43 except IOError,e:
44 print e.message
45if __name__ == "__main__":
46 s = SaveText()
47 #文件編碼
48 #字符正確解碼
49 reload(sys)
50 sys.setdefaultencoding( "utf-8" ) #獲得系統(tǒng)的默認(rèn)編碼
51 #獲取網(wǎng)頁
52 page = GetHtmlPage("http://blog.csdn.net/u013088062/article/list/1")
53 htmlPage = page.GetPage()
54 #提取內(nèi)容
55 reServer = RePage()
56 reBlog = reServer.GetReText(htmlPage,r'<span
class="link_title"><a
href="(.+?)">.*?(\s.+?)</a></span>') #獲取網(wǎng)址鏈接和標(biāo)題
57 #再向下獲取正文
58 for ref in reBlog:
59 pageHeard = "http://blog.csdn.net/" #加鏈接頭
60 strPage = pageHeard+ref[0]
61 tilte=ref[1].replace('<font color="red">[置頂]</font>', "") #用替換的功能去除雜的英文
62 tilte=tilte.replace("\r\n","").lstrip().rstrip()
63 #獲取正文
64 htmlPage = GetHtmlPage(strPage)
65 htmlPageData = htmlPage.GetPage()
66 reBlogText = reServer.GetReText(htmlPageData,'<div
id="article_content" class="article_content">(.+?)</div>')
67 #保存文件
68 for s1 in reBlogText:
69 s1='<meta charset="UTF-8">\n'+s1
70 s.Save(s1,tilte)
根據(jù)上期學(xué)員的反饋和優(yōu)化,接下來覃老師主講Python數(shù)據(jù)挖掘課程變成4天��,跟著覃老師一起領(lǐng)悟數(shù)據(jù)挖掘算法在行業(yè)應(yīng)用��。強(qiáng)化的培訓(xùn)��,應(yīng)該讓你可以學(xué)完后很自信�,學(xué)以致用,快速上手解決工作中的問題���。
4天課程內(nèi)容足夠豐富�����,想學(xué)習(xí)的朋友報名從速��,點(diǎn)擊閱讀原文��,查看課程詳情����,繳費(fèi)后獲得預(yù)習(xí)視頻和資料�。
在線咨詢:
張老師
座機(jī):010-68456523
QQ:2881989712
掃碼添加微信

CDA數(shù)據(jù)分析師考試相關(guān)入口一覽(建議收藏):
? 想報名CDA認(rèn)證考試�����,點(diǎn)擊>>>
“CDA報名”
了解CDA考試詳情����;
? 想學(xué)習(xí)CDA考試教材�����,點(diǎn)擊>>> “CDA教材” 了解CDA考試詳情;
? 想加入CDA考試題庫����,點(diǎn)擊>>> “CDA題庫” 了解CDA考試詳情��;
? 想了解CDA考試含金量����,點(diǎn)擊>>> “CDA含金量” 了解CDA考試詳情���;











 京公網(wǎng)安備 11010802034615號
經(jīng)營許可證編號:京B2-20210330
京公網(wǎng)安備 11010802034615號
經(jīng)營許可證編號:京B2-20210330