機(jī)器學(xué)習(xí)故事匯-集成算法
【咱們的目標(biāo)】系列算法講解旨在用最簡單易懂的故事情節(jié)幫助大家掌握晦澀無趣的機(jī)器學(xué)習(xí),適合對數(shù)學(xué)很頭疼的同學(xué)們�,小板凳走起!

今天咱們就來討論一下傳說中的集成算法�,之前咱們講的算法都是單兵作戰(zhàn)的(單個(gè)模型得到結(jié)果),但是回過頭來想一想現(xiàn)在是不是干啥都講究個(gè)合作共贏�,所以咱們的模型也是如此。單個(gè)算法確實(shí)勢單力薄��,假如我們可以把它們組合起來會(huì)不會(huì)得到更好的效果呢��?(算法們要揭竿起義了����,今亡亦死舉大計(jì)亦死。�。。編不下去了)
在集成算法中�����,有三個(gè)核心模塊��,咱們就一一道來�,先來概述一下:
Bagging集成:并行的構(gòu)造多個(gè)基礎(chǔ)模型(隨機(jī)森林),每一個(gè)基礎(chǔ)模型都各自為政��,然后把它們的結(jié)果求一個(gè)平均就好!
Boosting集成:串行的構(gòu)造多個(gè)基礎(chǔ)模型(Xgboost)���,每一個(gè)基礎(chǔ)模型都要嚴(yán)格篩選�,在前面的基礎(chǔ)上加進(jìn)來的新模型后�����,它們整體的效果起碼得沒加這個(gè)新的基礎(chǔ)模型前要強(qiáng)吧�����!
Stacking集成:多種算法群毆一起上����!選擇多個(gè)機(jī)器學(xué)習(xí)算法做同一件事����,最后把它們的結(jié)果合并就OK啦!
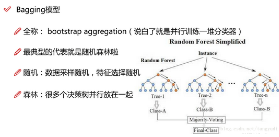
先來看看第一個(gè)家伙Bagging模型�,其典型代表就是隨機(jī)森立了,簡單來說就是并行的訓(xùn)練一堆樹模型��,然后求其平均結(jié)果���,在這里我們要討論一個(gè)問題�����,就是每個(gè)樹模型該怎么構(gòu)造呢����?如果不加入任何限制,那每個(gè)樹模型不都差不多嘛�����,那最后的平均結(jié)果又會(huì)有什么變化呢�?所以為了結(jié)果的泛化能力更強(qiáng),必須要使得每個(gè)樹模型表現(xiàn)出多樣性�,也就是盡可能的讓每個(gè)樹模型都不一樣!
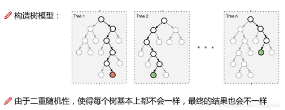
這該怎么做呢�?什么影響模型呢?數(shù)據(jù)絕對是最大的影響因子�����,這里的森林很好理解了���,就是把樹放在一起�,那么隨機(jī)又是什么呢?為了保證每個(gè)樹的多樣性�,在構(gòu)建模型時(shí),我們做了二重隨機(jī)(我自創(chuàng)的詞��。�����。����。)第一重就是對樣本的選擇,每次隨機(jī)的有放回的選擇部分樣本作為一棵樹的訓(xùn)練樣本(比如選擇百分之八十作為訓(xùn)練集)���。第二重還要考慮特征了,既然樣本數(shù)據(jù)能隨機(jī)�,那么特征也是一樣的,每棵樹選擇的特征也是不一樣的隨機(jī)選擇部分特征來建模���!
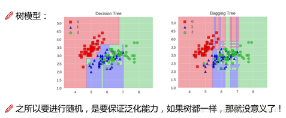
隨機(jī)的意義非常重要�����,這是隨機(jī)森林的精神所在���!
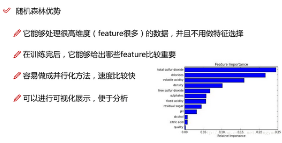
隨機(jī)森林作為灰常經(jīng)典的機(jī)器學(xué)習(xí)算法����,優(yōu)勢自然少不了�,當(dāng)我們建模完之后,還可以對特征進(jìn)行重要性評估����,其實(shí)簡單來說一個(gè)特征的重要與否可以取決于建模的時(shí)候如果把這個(gè)特征換成噪音特征再去看看結(jié)果的錯(cuò)誤率是不是顯著上升,如果顯著上升��,那么這個(gè)特征自然很重要�,如果沒變化,那這個(gè)特征就沒啥用了��,因?yàn)樗驮胍魶]啥區(qū)別�!
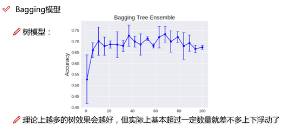
隨機(jī)森林中樹的個(gè)數(shù)是不是越多越好呢?理論上越多的樹效果應(yīng)該會(huì)更好吧���,但是實(shí)際上我們把樹的個(gè)數(shù)增加到一定的時(shí)候比如100棵了已經(jīng)����,再往上增加樹的個(gè)數(shù)結(jié)果也只會(huì)發(fā)生小范圍的浮動(dòng),基本也就穩(wěn)定了�!

Boosting集成中典型的代表就屬Xgboost啦,一個(gè)大殺器�,這個(gè)算法由于涉及的數(shù)學(xué)比較多,咱們后續(xù)來一個(gè)專題去講Xgboost���,我們先來看看簡單些的Adaboost��。

Adaboost算法概述來說就是�����,首選我有一個(gè)非常簡單的模型���,比如深度為1的樹模型,然后我去預(yù)測一下結(jié)果�����,在結(jié)果中我發(fā)現(xiàn)某些樣本預(yù)測錯(cuò)了��,這個(gè)時(shí)候第二個(gè)簡單的樹模型就來了�,還是同樣的任務(wù)只不過數(shù)據(jù)的權(quán)重發(fā)生了變換���,一開始所有的數(shù)據(jù)都是相同的權(quán)重�����,但是第二次會(huì)把前面那次預(yù)測錯(cuò)的數(shù)據(jù)的權(quán)重增大����,相對來說預(yù)測對的數(shù)據(jù)的權(quán)重就會(huì)減小。說白了就是讓后面的模型更注重我之前哪些數(shù)據(jù)分錯(cuò)了��,這回好能分對它?���。ê帽任覀冊诳荚嚽岸紩?huì)復(fù)習(xí)之前做錯(cuò)的題)

最后來看一下堆疊模型吧,社會(huì)我Stacking�����,人狠話不多����,不需要多解釋,做了一堆算法�����,然后把它們的結(jié)果堆疊起來,每個(gè)算法都有自己的預(yù)測結(jié)果�,這些結(jié)果組合在一起那不相當(dāng)于一個(gè)新的特征嘛,再把它們結(jié)果組成的特征去做一個(gè)分類或者回歸��,又得到了一個(gè)唯一的結(jié)果�。
CDA數(shù)據(jù)分析師考試相關(guān)入口一覽(建議收藏):
? 想報(bào)名CDA認(rèn)證考試,點(diǎn)擊>>>
“CDA報(bào)名”
了解CDA考試詳情����;
? 想學(xué)習(xí)CDA考試教材,點(diǎn)擊>>> “CDA教材” 了解CDA考試詳情����;
? 想加入CDA考試題庫,點(diǎn)擊>>> “CDA題庫” 了解CDA考試詳情��;
? 想了解CDA考試含金量�����,點(diǎn)擊>>> “CDA含金量” 了解CDA考試詳情��;











 京公網(wǎng)安備 11010802034615號(hào)
經(jīng)營許可證編號(hào):京B2-20210330
京公網(wǎng)安備 11010802034615號(hào)
經(jīng)營許可證編號(hào):京B2-20210330