Spss中非參數(shù)檢驗的兩個獨立樣本檢驗
Spss中非參數(shù)檢驗中兩個獨立樣本檢驗中四個復選項的區(qū)別和適用范圍
可以先數(shù)據(jù)-選擇個案
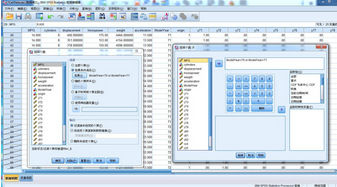
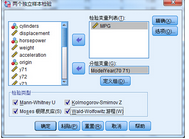
1.Mann-Whitney U: 主要用于判別兩個獨立樣本所屬的總體是否有相同的分布;
2. Kolmogorov-Smirnov Z: 推測兩個樣本是否來自具有相同分布的總體;
3. Moses extreme reactions:檢驗兩個獨立樣本之觀察值的散布范圍是否有差異存在,以檢驗兩個樣本是否來自具有同一分布的總體;
4. Wald-Wolfowitz runs: 考察兩個獨立樣本是否來自具有相同分布的總體�����。
1.Mann-Whitney U檢驗(又簡稱M-W檢驗)��,注重對分布的中心位置(平均水平)作檢驗����,實際是檢驗H0:兩樣本所對應的總體具有相同的中心位置(中位數(shù))����,屬位置參數(shù)檢驗�����,而不管兩總體分布的形狀如何�����,因此通常假定兩總體分布的形狀相同��,只有在這個前提下的中心位置相同才能說是兩總體分布相同或兩樣本來自相同總體;若不能明確兩總體分布的形狀是否相同��,則不宜單獨使用此方法作分析了事�����,應同時作K-S檢驗或W-W檢驗���,并對全部結果作綜合分析�����。因為此方法與目前國內(nèi)通用教材中的Wilcoxon
Rank Sum檢驗法完全等價��,故在結果中一并給出〔1〕��。小樣本時應讀取精確概率作結論����。
2.Kolmogorov-Smirnov Z檢驗(又簡稱K-S檢驗)是上述提到的Kolmogorov檢驗用于兩個獨立樣本的情形�����,對全貌作檢驗��。如果結論是兩總體分布不相同���,此方法尚不足以說明是位置不同����、變異程度不同還是偏度不同,這是報告結果時應注意的�。結果中的Z也是漸近統(tǒng)計量���,大樣本時α=0.05和α=0.01的界值分別是1.36和1.63����,小樣本時應讀取結果中兩個經(jīng)驗分布函數(shù)的最大差值查界值表作結論���,不可直接利用結果中的P值作結論����。
3.Wald-Wolfowitz
runs檢驗 (又簡稱W-W檢驗)與K-S檢驗相似�,也是對全貌作檢驗�����,但其功效不如后者;此方法實為Runs過程用于分析兩個獨立樣本的情形�。與K-S檢驗類似,如果結論是兩總體分布不相同����,此方法尚不足以說明是位置不同��、變異程度不同還是偏度不同����,報告結果時也應注意��。若兩樣本有相同觀察值����,結果中提供最大和最小游程個數(shù)以及相應的P值,當依此兩P值所作的結論相矛盾時���,須計算平均游程個數(shù)����,然后查表作結論或用正態(tài)近似法作檢驗�。此過程自動地根據(jù)樣本大小給出確切概率或正態(tài)近似法的結果。
4.Moses Test of Extreme Reactions 檢驗注重于對分布范圍(變異程度)作檢驗��,實際是檢驗H0:兩樣本所對應的總體具有相同的分布范圍�����。要求樣本足夠大。筆者尚未見到在醫(yī)學領域中使用此方法的例子����。











 京公網(wǎng)安備 11010802034615號
經(jīng)營許可證編號:京B2-20210330
京公網(wǎng)安備 11010802034615號
經(jīng)營許可證編號:京B2-20210330