簡(jiǎn)單易學(xué)的機(jī)器學(xué)習(xí)算法——K-Means++算法
一����、K-Means算法存在的問題
由于K-Means算法的簡(jiǎn)單且易于實(shí)現(xiàn)��,因此K-Means算法得到了很多的應(yīng)用����,但是從K-Means算法的過程中發(fā)現(xiàn)��,K-Means算法中的聚類中心的個(gè)數(shù)k需要事先指定����,這一點(diǎn)對(duì)于一些未知數(shù)據(jù)存在很大的局限性。其次,在利用K-Means算法進(jìn)行聚類之前�����,需要初始化k個(gè)聚類中心�����,在上述的K-Means算法的過程中���,使用的是在數(shù)據(jù)集中隨機(jī)選擇最大值和最小值之間的數(shù)作為其初始的聚類中心��,但是聚類中心選擇不好�,對(duì)于K-Means算法有很大的影響����。對(duì)于如下的數(shù)據(jù)集:
如選取的個(gè)聚類中心為:

最終的聚類結(jié)果為:
為了解決因?yàn)槌跏蓟膯栴}帶來K-Means算法的問題,改進(jìn)的K-Means算法�,即K-Means++算法被提出,K-Means++算法主要是為了能夠在聚類中心的選擇過程中選擇較優(yōu)的聚類中心�。
二、K-Means++算法的思路
K-Means++算法在聚類中心的初始化過程中的基本原則是使得初始的聚類中心之間的相互距離盡可能遠(yuǎn)�,這樣可以避免出現(xiàn)上述的問題。K-Means++算法的初始化過程如下所示:
在數(shù)據(jù)集中隨機(jī)選擇一個(gè)樣本點(diǎn)作為第一個(gè)初始化的聚類中心
選擇出其余的聚類中心:
計(jì)算樣本中的每一個(gè)樣本點(diǎn)與已經(jīng)初始化的聚類中心之間的距離��,并選擇其中最短的距離,記為d_i
以概率選擇距離最大的樣本作為新的聚類中心����,重復(fù)上述過程,直到k個(gè)聚類中心都被確定
對(duì)k個(gè)初始化的聚類中心�����,利用K-Means算法計(jì)算最終的聚類中心����。
在上述的K-Means++算法中可知K-Means++算法與K-Means算法最本質(zhì)的區(qū)別是在k個(gè)聚類中心的初始化過程。
Python實(shí)現(xiàn):
一�、K-Means算法存在的問題
由于K-Means算法的簡(jiǎn)單且易于實(shí)現(xiàn),因此K-Means算法得到了很多的應(yīng)用��,但是從K-Means算法的過程中發(fā)現(xiàn)���,K-Means算法中的聚類中心的個(gè)數(shù)k需要事先指定���,這一點(diǎn)對(duì)于一些未知數(shù)據(jù)存在很大的局限性�。其次,在利用K-Means算法進(jìn)行聚類之前��,需要初始化k個(gè)聚類中心,在上述的K-Means算法的過程中�,使用的是在數(shù)據(jù)集中隨機(jī)選擇最大值和最小值之間的數(shù)作為其初始的聚類中心,但是聚類中心選擇不好��,對(duì)于K-Means算法有很大的影響���。對(duì)于如下的數(shù)據(jù)集:
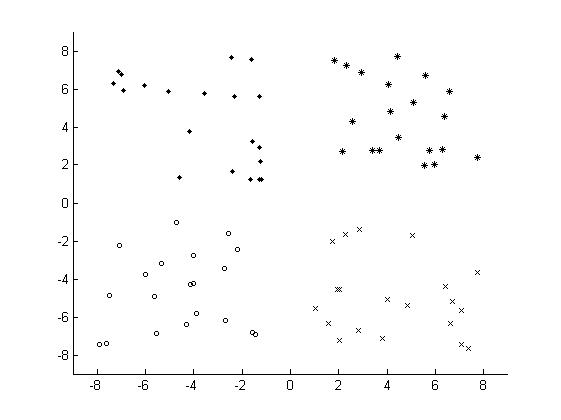
如選取的個(gè)聚類中心為:
最終的聚類結(jié)果為:
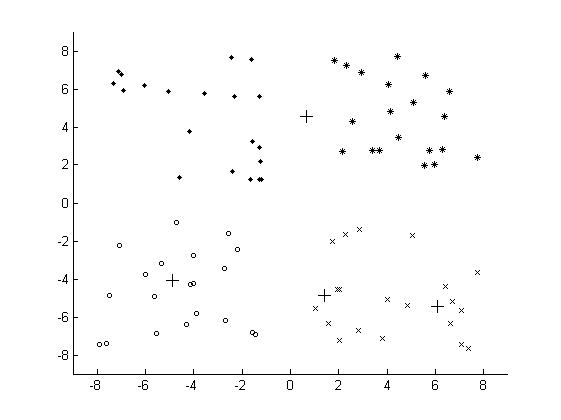
為了解決因?yàn)槌跏蓟膯栴}帶來K-Means算法的問題����,改進(jìn)的K-Means算法,即K-Means++算法被提出����,K-Means++算法主要是為了能夠在聚類中心的選擇過程中選擇較優(yōu)的聚類中心。
二����、K-Means++算法的思路
K-Means++算法在聚類中心的初始化過程中的基本原則是使得初始的聚類中心之間的相互距離盡可能遠(yuǎn),這樣可以避免出現(xiàn)上述的問題�����。K-Means++算法的初始化過程如下所示:
在數(shù)據(jù)集中隨機(jī)選擇一個(gè)樣本點(diǎn)作為第一個(gè)初始化的聚類中心
選擇出其余的聚類中心:
計(jì)算樣本中的每一個(gè)樣本點(diǎn)與已經(jīng)初始化的聚類中心之間的距離�,并選擇其中最短的距離,記為d_i
以概率選擇距離最大的樣本作為新的聚類中心���,重復(fù)上述過程��,直到k個(gè)聚類中心都被確定
對(duì)k個(gè)初始化的聚類中心����,利用K-Means算法計(jì)算最終的聚類中心。
在上述的K-Means++算法中可知K-Means++算法與K-Means算法最本質(zhì)的區(qū)別是在k個(gè)聚類中心的初始化過程����。
Python實(shí)現(xiàn):
# coding:UTF-8
'''
Date:20160923
@author: zhaozhiyong
'''
import numpy as np
from random import random
from KMeans import load_data, kmeans, distance, save_result
FLOAT_MAX = 1e100 # 設(shè)置一個(gè)較大的值作為初始化的最小的距離
def nearest(point, cluster_centers):
min_dist = FLOAT_MAX
m = np.shape(cluster_centers)[0] # 當(dāng)前已經(jīng)初始化的聚類中心的個(gè)數(shù)
for i in xrange(m):
# 計(jì)算point與每個(gè)聚類中心之間的距離
d = distance(point, cluster_centers[i, ])
# 選擇最短距離
if min_dist > d:
min_dist = d
return min_dist
def get_centroids(points, k):
m, n = np.shape(points)
cluster_centers = np.mat(np.zeros((k , n)))
# 1、隨機(jī)選擇一個(gè)樣本點(diǎn)為第一個(gè)聚類中心
index = np.random.randint(0, m)
cluster_centers[0, ] = np.copy(points[index, ])
# 2�、初始化一個(gè)距離的序列
d = [0.0 for _ in xrange(m)]
for i in xrange(1, k):
sum_all = 0
for j in xrange(m):
# 3、對(duì)每一個(gè)樣本找到最近的聚類中心點(diǎn)
d[j] = nearest(points[j, ], cluster_centers[0:i, ])
# 4���、將所有的最短距離相加
sum_all += d[j]
# 5��、取得sum_all之間的隨機(jī)值
sum_all *= random()
# 6�、獲得距離最遠(yuǎn)的樣本點(diǎn)作為聚類中心點(diǎn)
for j, di in enumerate(d):
sum_all -= di
if sum_all > 0:
continue
cluster_centers[i] = np.copy(points[j, ])
break
return cluster_centers
if __name__ == "__main__":
k = 4#聚類中心的個(gè)數(shù)
file_path = "data.txt"
# 1�、導(dǎo)入數(shù)據(jù)
print "---------- 1.load data ------------"
data = load_data(file_path)
# 2、KMeans++的聚類中心初始化方法
print "---------- 2.K-Means++ generate centers ------------"
centroids = get_centroids(data, k)
# 3�����、聚類計(jì)算
print "---------- 3.kmeans ------------"
subCenter = kmeans(data, k, centroids)
# 4�����、保存所屬的類別文件
print "---------- 4.save subCenter ------------"
save_result("sub_pp", subCenter)
# 5�、保存聚類中心
print "---------- 5.save centroids ------------"
save_result("center_pp", centroids)
其中,KMeans所在的文件為:
# coding:UTF-8
'''
Date:20160923
@author: zhaozhiyong
'''
import numpy as np
def load_data(file_path):
f = open(file_path)
data = []
for line in f.readlines():
row = [] # 記錄每一行
lines = line.strip().split("\t")
for x in lines:
row.append(float(x)) # 將文本中的特征轉(zhuǎn)換成浮點(diǎn)數(shù)
data.append(row)
f.close()
return np.mat(data)
def distance(vecA, vecB):
dist = (vecA - vecB) * (vecA - vecB).T
return dist[0, 0]
def randCent(data, k):
n = np.shape(data)[1] # 屬性的個(gè)數(shù)
centroids = np.mat(np.zeros((k, n))) # 初始化k個(gè)聚類中心
for j in xrange(n): # 初始化聚類中心每一維的坐標(biāo)
minJ = np.min(data[:, j])
rangeJ = np.max(data[:, j]) - minJ
# 在最大值和最小值之間隨機(jī)初始化
centroids[:, j] = minJ * np.mat(np.ones((k , 1))) + np.random.rand(k, 1) * rangeJ
return centroids
def kmeans(data, k, centroids):
m, n = np.shape(data) # m:樣本的個(gè)數(shù)���,n:特征的維度
subCenter = np.mat(np.zeros((m, 2))) # 初始化每一個(gè)樣本所屬的類別
change = True # 判斷是否需要重新計(jì)算聚類中心
while change == True:
change = False # 重置
for i in xrange(m):
minDist = np.inf # 設(shè)置樣本與聚類中心之間的最小的距離���,初始值為爭(zhēng)取窮
minIndex = 0 # 所屬的類別
for j in xrange(k):
# 計(jì)算i和每個(gè)聚類中心之間的距離
dist = distance(data[i, ], centroids[j, ])
if dist < minDist:
minDist = dist
minIndex = j
# 判斷是否需要改變
if subCenter[i, 0] <> minIndex: # 需要改變
change = True
subCenter[i, ] = np.mat([minIndex, minDist])
# 重新計(jì)算聚類中心
for j in xrange(k):
sum_all = np.mat(np.zeros((1, n)))
r = 0 # 每個(gè)類別中的樣本的個(gè)數(shù)
for i in xrange(m):
if subCenter[i, 0] == j: # 計(jì)算第j個(gè)類別
sum_all += data[i, ]
r += 1
for z in xrange(n):
try:
centroids[j, z] = sum_all[0, z] / r
except:
print " r is zero"
return subCenter
def save_result(file_name, source):
m, n = np.shape(source)
f = open(file_name, "w")
for i in xrange(m):
tmp = []
for j in xrange(n):
tmp.append(str(source[i, j]))
f.write("\t".join(tmp) + "\n")
f.close()
最終的結(jié)果為:
CDA數(shù)據(jù)分析師考試相關(guān)入口一覽(建議收藏):
? 想報(bào)名CDA認(rèn)證考試�����,點(diǎn)擊>>>
“CDA報(bào)名”
了解CDA考試詳情;
? 想學(xué)習(xí)CDA考試教材,點(diǎn)擊>>> “CDA教材” 了解CDA考試詳情��;
? 想加入CDA考試題庫,點(diǎn)擊>>> “CDA題庫” 了解CDA考試詳情�����;
? 想了解CDA考試含金量,點(diǎn)擊>>> “CDA含金量” 了解CDA考試詳情����;











 京公網(wǎng)安備 11010802034615號(hào)
經(jīng)營(yíng)許可證編號(hào):京B2-20210330
京公網(wǎng)安備 11010802034615號(hào)
經(jīng)營(yíng)許可證編號(hào):京B2-20210330