機(jī)器學(xué)習(xí)中防止過擬合方法
過擬合
在進(jìn)行數(shù)據(jù)挖掘或者機(jī)器學(xué)習(xí)模型建立的時(shí)候���,因?yàn)樵诮y(tǒng)計(jì)學(xué)習(xí)中����,假設(shè)數(shù)據(jù)滿足獨(dú)立同分布���,即當(dāng)前已產(chǎn)生的數(shù)據(jù)可以對未來的數(shù)據(jù)進(jìn)行推測與模擬���,因此都是使用歷史數(shù)據(jù)建立模型,即使用已經(jīng)產(chǎn)生的數(shù)據(jù)去訓(xùn)練�,然后使用該模型去擬合未來的數(shù)據(jù)�。但是一般獨(dú)立同分布的假設(shè)往往不成立��,即數(shù)據(jù)的分布可能會發(fā)生變化(distribution
drift)��,并且可能當(dāng)前的數(shù)據(jù)量過少��,不足以對整個(gè)數(shù)據(jù)集進(jìn)行分布估計(jì)���,因此往往需要防止模型過擬合,提高模型泛化能力����。而為了達(dá)到該目的的最常見方法便是:正則化,即在對模型的目標(biāo)函數(shù)(objective
function)或代價(jià)函數(shù)(cost function)加上正則項(xiàng)���。
在對模型進(jìn)行訓(xùn)練時(shí)����,有可能遇到訓(xùn)練數(shù)據(jù)不夠���,即訓(xùn)練數(shù)據(jù)無法對整個(gè)數(shù)據(jù)的分布進(jìn)行估計(jì)的時(shí)候����,或者在對模型進(jìn)行過度訓(xùn)練(overtraining)時(shí),常常會導(dǎo)致模型的過擬合(overfitting)���。如下圖所示:
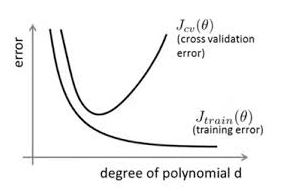
通過上圖可以看出���,隨著模型訓(xùn)練的進(jìn)行,模型的復(fù)雜度會增加���,此時(shí)模型在訓(xùn)練數(shù)據(jù)集上的訓(xùn)練誤差會逐漸減小�,但是在模型的復(fù)雜度達(dá)到一定程度時(shí)����,模型在驗(yàn)證集上的誤差反而隨著模型的復(fù)雜度增加而增大。此時(shí)便發(fā)生了過擬合��,即模型的復(fù)雜度升高�,但是該模型在除訓(xùn)練集之外的數(shù)據(jù)集上卻不work。
方法
提前終止(當(dāng)驗(yàn)證集上的效果變差的時(shí)候)
正則化(Regularization)
L1正則化
L2正則化
數(shù)據(jù)集擴(kuò)增(Data augmentation)
Dropout
1��、提前終止
對模型進(jìn)行訓(xùn)練的過程即是對模型的參數(shù)進(jìn)行學(xué)習(xí)更新的過程���,這個(gè)參數(shù)學(xué)習(xí)的過程往往會用到一些迭代方法��,如梯度下降(Gradient descent)學(xué)習(xí)算法���。Early stopping便是一種迭代次數(shù)截?cái)嗟姆椒▉矸乐?a href='/map/guonihe/' style='color:#000;font-size:inherit;'>過擬合的方法����,即在模型對訓(xùn)練數(shù)據(jù)集迭代收斂之前停止迭代來防止過擬合�����。
Early stopping方法的具體做法是���,在每一個(gè)Epoch結(jié)束時(shí)(一個(gè)Epoch集為對所有的訓(xùn)練數(shù)據(jù)的一輪遍歷)計(jì)算validation
data的accuracy��,當(dāng)accuracy不再提高時(shí),就停止訓(xùn)練�。這種做法很符合直觀感受,因?yàn)閍ccurary都不再提高了�,在繼續(xù)訓(xùn)練也是無益的,只會提高訓(xùn)練的時(shí)間���。那么該做法的一個(gè)重點(diǎn)便是怎樣才認(rèn)為validation
accurary不再提高了呢��?并不是說validation
accuracy一降下來便認(rèn)為不再提高了��,因?yàn)榭赡芙?jīng)過這個(gè)Epoch后�,accuracy降低了,但是隨后的Epoch又讓accuracy又上去了����,所以不能根據(jù)一兩次的連續(xù)降低就判斷不再提高。一般的做法是���,在訓(xùn)練的過程中�,記錄到目前為止最好的validation accuracy�,當(dāng)連續(xù)10次Epoch(或者更多次)沒達(dá)到最佳a(bǔ)ccuracy時(shí),則可以認(rèn)為accuracy不再提高了�����。此時(shí)便可以停止迭代了(Early Stopping)��。這種策略也稱為“No-improvement-in-n”�,n即Epoch的次數(shù),可以根據(jù)實(shí)際情況取��,如10���、20���、30……
2�����、數(shù)據(jù)集擴(kuò)增
在數(shù)據(jù)挖掘領(lǐng)域流行著這樣的一句話��,“有時(shí)候往往擁有更多的數(shù)據(jù)勝過一個(gè)好的模型”���。因?yàn)槲覀冊谑褂糜?xùn)練數(shù)據(jù)訓(xùn)練模型,通過這個(gè)模型對將來的數(shù)據(jù)進(jìn)行擬合��,而在這之間又一個(gè)假設(shè)便是����,訓(xùn)練數(shù)據(jù)與將來的數(shù)據(jù)是獨(dú)立同分布的。即使用當(dāng)前的訓(xùn)練數(shù)據(jù)來對將來的數(shù)據(jù)進(jìn)行估計(jì)與模擬��,而更多的數(shù)據(jù)往往估計(jì)與模擬地更準(zhǔn)確��。因此�����,更多的數(shù)據(jù)有時(shí)候更優(yōu)秀���。但是往往條件有限����,如人力物力財(cái)力的不足����,而不能收集到更多的數(shù)據(jù),如在進(jìn)行分類的任務(wù)中��,需要對數(shù)據(jù)進(jìn)行打標(biāo)��,并且很多情況下都是人工得進(jìn)行打標(biāo)���,因此一旦需要打標(biāo)的數(shù)據(jù)量過多�,就會導(dǎo)致效率低下以及可能出錯(cuò)的情況���。所以��,往往在這時(shí)候����,需要采取一些計(jì)算的方式與策略在已有的數(shù)據(jù)集上進(jìn)行手腳���,以得到更多的數(shù)據(jù)���。
通俗得講�,數(shù)據(jù)機(jī)擴(kuò)增即需要得到更多的符合要求的數(shù)據(jù)���,即和已有的數(shù)據(jù)是獨(dú)立同分布的��,或者近似獨(dú)立同分布的���。一般有以下方法:
從數(shù)據(jù)源頭采集更多數(shù)據(jù)
復(fù)制原有數(shù)據(jù)并加上隨機(jī)噪聲
重采樣
根據(jù)當(dāng)前數(shù)據(jù)集估計(jì)數(shù)據(jù)分布參數(shù),使用該分布產(chǎn)生更多數(shù)據(jù)等
如圖像處理:
圖像平移�����。這種方法可以使得網(wǎng)絡(luò)學(xué)習(xí)到平移不變的特征��。
圖像旋轉(zhuǎn)���。學(xué)習(xí)旋轉(zhuǎn)不變的特征��。有些任務(wù)里,目標(biāo)可能有多種不同的姿態(tài)��,旋轉(zhuǎn)正好可以彌補(bǔ)樣本中姿態(tài)較少的問題。
圖像鏡像���。和旋轉(zhuǎn)的功能類似��。
圖像亮度變化�����。甚至可以用直方圖均衡化����。
裁剪�����。
縮放���。
圖像模糊�����。用不同的模板卷積產(chǎn)生模糊圖像。
3��、正則化
正則化方法是指在進(jìn)行目標(biāo)函數(shù)或代價(jià)函數(shù)優(yōu)化時(shí)�,在目標(biāo)函數(shù)或代價(jià)函數(shù)后面加上一個(gè)正則項(xiàng),一般有L1正則與L2正則等�。
3.1���、L1正則
在原始的代價(jià)函數(shù)后面加上一個(gè)L1正則化項(xiàng)���,即所有權(quán)重w的絕對值的和,乘以λ/n(這里不像L2正則化項(xiàng)那樣�,需要再乘以1/2。)
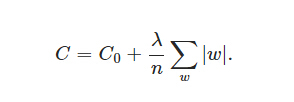
同樣先計(jì)算導(dǎo)數(shù):
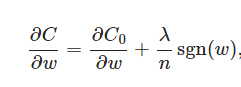
上式中sgn(w)表示w的符號。那么權(quán)重w的更新規(guī)則為:
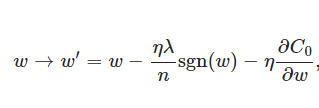
比原始的更新規(guī)則多出了η * λ * sgn(w)/n這一項(xiàng)��。當(dāng)w為正時(shí)�����,更新后的w變小。當(dāng)w為負(fù)時(shí)���,更新后的w變大——因此它的效果就是讓w往0靠���,使網(wǎng)絡(luò)中的權(quán)重盡可能為0�,也就相當(dāng)于減小了網(wǎng)絡(luò)復(fù)雜度���,防止過擬合�。
另外��,上面沒有提到一個(gè)問題�,當(dāng)w為0時(shí)怎么辦?當(dāng)w等于0時(shí)��,|W|是不可導(dǎo)的,所以我們只能按照原始的未經(jīng)正則化的方法去更新w��,這就相當(dāng)于去掉η*λ*sgn(w)/n這一項(xiàng)��,所以我們可以規(guī)定sgn(0)=0�,這樣就把w=0的情況也統(tǒng)一進(jìn)來了。(在編程的時(shí)候��,令sgn(0)=0,sgn(w>0)=1,sgn(w<0)=-1)
3.2��、L2正則化
L2正則化就是在代價(jià)函數(shù)后面再加上一個(gè)正則化項(xiàng):
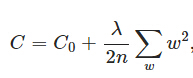
C0代表原始的代價(jià)函數(shù)����,后面那一項(xiàng)就是L2正則化項(xiàng),它是這樣來的:所有參數(shù)w的平方的和,除以訓(xùn)練集的樣本大小n����。λ就是正則項(xiàng)系數(shù),權(quán)衡正則項(xiàng)與C0項(xiàng)的比重����。另外還有一個(gè)系數(shù)1/2�,1/2經(jīng)常會看到,主要是為了后面求導(dǎo)的結(jié)果方便�,后面那一項(xiàng)求導(dǎo)會產(chǎn)生一個(gè)2,與1/2相乘剛好湊整��。
L2正則化項(xiàng)是怎么避免overfitting的呢�?我們推導(dǎo)一下看看,先求導(dǎo):
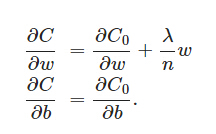
可以發(fā)現(xiàn)L2正則化項(xiàng)對b的更新沒有影響����,但是對于w的更新有影響:

在不使用L2正則化時(shí),求導(dǎo)結(jié)果中w前系數(shù)為1�����,現(xiàn)在w前面系數(shù)為 1?ηλ/n ���,因?yàn)棣?���、λ、n都是正的����,所以 1?ηλ/n小于1,它的效果是減小w���,這也就是權(quán)重衰減(weight decay)的由來����。當(dāng)然考慮到后面的導(dǎo)數(shù)項(xiàng)����,w最終的值可能增大也可能減小。
另外�,需要提一下,對于基于mini-batch的隨機(jī)梯度下降�,w和b更新的公式跟上面給出的有點(diǎn)不同:
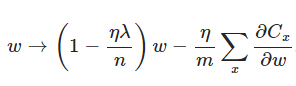

對比上面w的更新公式,可以發(fā)現(xiàn)后面那一項(xiàng)變了��,變成所有導(dǎo)數(shù)加和�,乘以η再除以m�����,m是一個(gè)mini-batch中樣本的個(gè)數(shù)�����。
到目前為止�,我們只是解釋了L2正則化項(xiàng)有讓w“變小”的效果��,但是還沒解釋為什么w“變小”可以防止overfitting����?一個(gè)所謂“顯而易見”的解釋就是:更小的權(quán)值w�,從某種意義上說,表示網(wǎng)絡(luò)的復(fù)雜度更低����,對數(shù)據(jù)的擬合剛剛好(這個(gè)法則也叫做奧卡姆剃刀),而在實(shí)際應(yīng)用中���,也驗(yàn)證了這一點(diǎn)��,L2正則化的效果往往好于未經(jīng)正則化的效果�����。當(dāng)然�,對于很多人(包括我)來說,這個(gè)解釋似乎不那么顯而易見��,所以這里添加一個(gè)稍微數(shù)學(xué)一點(diǎn)的解釋(引自知乎):
過擬合的時(shí)候�,擬合函數(shù)的系數(shù)往往非常大,為什么����?如下圖所示,過擬合�,就是擬合函數(shù)需要顧忌每一個(gè)點(diǎn),最終形成的擬合函數(shù)波動(dòng)很大����。在某些很小的區(qū)間里,函數(shù)值的變化很劇烈�。這就意味著函數(shù)在某些小區(qū)間里的導(dǎo)數(shù)值(絕對值)非常大,由于自變量值可大可小�����,所以只有系數(shù)足夠大����,才能保證導(dǎo)數(shù)值很大���。
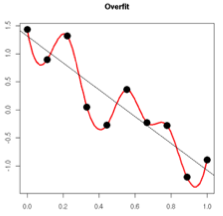
而正則化是通過約束參數(shù)的范數(shù)使其不要太大,所以可以在一定程度上減少過擬合情況�����。
4�����、Dropout
L1�����、L2正則化是通過修改代價(jià)函數(shù)來實(shí)現(xiàn)的����,而Dropout則是通過修改神經(jīng)網(wǎng)絡(luò)本身來實(shí)現(xiàn)的��,它是在訓(xùn)練網(wǎng)絡(luò)時(shí)用的一種技巧(trike)�。它的流程如下:
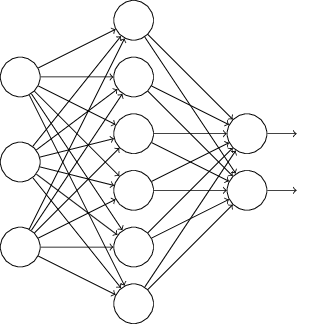
假設(shè)我們要訓(xùn)練上圖這個(gè)網(wǎng)絡(luò),在訓(xùn)練開始時(shí)�����,我們隨機(jī)地“刪除”一半的隱層單元,視它們?yōu)椴淮嬖?����,得到如下的網(wǎng)絡(luò):

保持輸入輸出層不變�����,按照BP算法更新上圖神經(jīng)網(wǎng)絡(luò)中的權(quán)值(虛線連接的單元不更新�����,因?yàn)樗鼈儽弧芭R時(shí)刪除”了)��。
以上就是一次迭代的過程����,在第二次迭代中,也用同樣的方法�����,只不過這次刪除的那一半隱層單元����,跟上一次刪除掉的肯定是不一樣的�����,因?yàn)槲覀兠恳淮蔚际恰半S機(jī)”地去刪掉一半�����。第三次��、第四次……都是這樣����,直至訓(xùn)練結(jié)束�����。
以上就是Dropout��,它為什么有助于防止過擬合呢��?可以簡單地這樣解釋��,運(yùn)用了dropout的訓(xùn)練過程�����,相當(dāng)于訓(xùn)練了很多個(gè)只有半數(shù)隱層單元的神經(jīng)網(wǎng)絡(luò)(后面簡稱為“半數(shù)網(wǎng)絡(luò)”),每一個(gè)這樣的半數(shù)網(wǎng)絡(luò)��,都可以給出一個(gè)分類結(jié)果���,這些結(jié)果有的是正確的���,有的是錯(cuò)誤的���。隨著訓(xùn)練的進(jìn)行����,大部分半數(shù)網(wǎng)絡(luò)都可以給出正確的分類結(jié)果�����,那么少數(shù)的錯(cuò)誤分類結(jié)果就不會對最終結(jié)果造成大的影響��。
CDA數(shù)據(jù)分析師考試相關(guān)入口一覽(建議收藏):
? 想報(bào)名CDA認(rèn)證考試��,點(diǎn)擊>>>
“CDA報(bào)名”
了解CDA考試詳情;
? 想學(xué)習(xí)CDA考試教材����,點(diǎn)擊>>> “CDA教材” 了解CDA考試詳情;
? 想加入CDA考試題庫���,點(diǎn)擊>>> “CDA題庫” 了解CDA考試詳情���;
? 想了解CDA考試含金量��,點(diǎn)擊>>> “CDA含金量” 了解CDA考試詳情�;











 京公網(wǎng)安備 11010802034615號
經(jīng)營許可證編號:京B2-20210330
京公網(wǎng)安備 11010802034615號
經(jīng)營許可證編號:京B2-20210330