幾種常見(jiàn)排序算法的分析
泡排序是最簡(jiǎn)單的排序算法��,在所有算法中平均效率是最低的�����,但便于理解����,適用于記錄個(gè)數(shù)n較小的排序中;選擇排序適用于記錄個(gè)數(shù)n較小而記錄本身信息量較大的排序中�����;插入排序適用于記錄個(gè)數(shù)n較小而原數(shù)組基本有序的排序中����;希爾排序適用于記錄個(gè)數(shù)較大而記錄本身信息量較小的排序中;快速排序是從平均時(shí)間性能而言最佳的算法,適用于記錄個(gè)數(shù)n較大而記錄無(wú)序的排序中�;歸并排序適用于記錄個(gè)數(shù)n較大而記錄信息量也較大的排序中;基數(shù)排序適合于n值很大而關(guān)鍵字較小的序列���。
排序算法概述
排序定義: 所謂計(jì)算機(jī)中的排序�,就是使一串記錄��,按照其中的某個(gè)或某些關(guān)鍵字的大小��,遞增或遞減的排列起來(lái)的操作���。而排序算法(Sortingalgorithm)則是一種能將一串?dāng)?shù)據(jù)依照特定的方式進(jìn)行排列的一種算法����。
排序方式: 利用所需重排記錄的排序碼(SortKey)的值的大小�����,按照升序或降序?qū)⒃o(jì)錄的順序重新安排��。
插入排序算法介紹
插入排序是一種簡(jiǎn)單的插入排序法���,其基本思想是:把待排序的紀(jì)錄按其關(guān)鍵碼值的大小逐個(gè)插入到一個(gè)已經(jīng)排好序的有序序列中����,直到所有的紀(jì)錄插入完為止,得到一個(gè)新的有序序列��。插入排序的算法思路:
(1) 設(shè)置監(jiān)視哨r[0]�,將待插入紀(jì)錄的值賦值給r[0];
(2) 設(shè)置開(kāi)始查找的位置j��;
(3) 在數(shù)組中進(jìn)行搜索�,搜索中將第j個(gè)紀(jì)錄后移,直至r[0].key≥r[j].key為止���;
(4) 將r[0]插入r[j+1]的位置上�。
如果目標(biāo)是把n個(gè)元素的序列升序排列�����,那么采用插入排序存在最好情況和最壞情況�����。最好情況就是�,序列已經(jīng)是升序排列了�����,在這種情況下,需要進(jìn)行的比較操作需(n-1)次即可���。最壞情況就是�,序列是降序排列����,那么此時(shí)需要進(jìn)行的比較共有n(n-1)/2次。插入排序的賦值操作是比較操作的次數(shù)加上
(n-1)次����。平均來(lái)說(shuō)插入排序算法的時(shí)間復(fù)雜度為O(n^2)。因而�����,插入排序不適合對(duì)于數(shù)據(jù)量比較大的排序應(yīng)用�����。但是����,如果需要排序的數(shù)據(jù)量很小�,例如�,量級(jí)小于千,那么插入排序還是一個(gè)不錯(cuò)的選擇�����。
希爾排序算法介紹
先取一個(gè)小于n的整數(shù)d1作為第一個(gè)增量����,把文件的全部記錄分組。所有距離為d1的倍數(shù)的記錄放在同一個(gè)組中����。先在各組內(nèi)進(jìn)行直接插入排序;然后���,取第二個(gè)增量d2
< d1重復(fù)上述的分組和排序����,直至所取的增量d_t=1(d_t < d_(t-1) < ? < d_2 <
d_1)�����,即所有記錄放在同一組中進(jìn)行直接插入排序?yàn)橹埂?
該方法實(shí)質(zhì)上是一種分組插入方法��。
比較相隔較遠(yuǎn)距離(稱為增量)的數(shù)�,使得數(shù)移動(dòng)時(shí)能跨過(guò)多個(gè)元素,則進(jìn)行一次比[2]
較就可能消除多個(gè)元素交換�����。D.L.shell于1959年在以他名字命名的排序算法中實(shí)現(xiàn)了這一思想�。算法先將要排序的一組數(shù)按某個(gè)增量d分成若干組,每組中記錄的下標(biāo)相差d.對(duì)每組中全部元素進(jìn)行排序����,然后再用一個(gè)較小的增量對(duì)它進(jìn)行,在每組中再進(jìn)行排序��。當(dāng)增量減到1時(shí)���,整個(gè)要排序的數(shù)被分成一組�����,排序完成��。
一般的初次取序列的一半為增量����,以后每次減半,直到增量為1���。
希爾排序是按照不同步長(zhǎng)對(duì)元素進(jìn)行插入排序��,當(dāng)剛開(kāi)始元素很無(wú)序的時(shí)候�����,步長(zhǎng)最大�����,所以插入排序的元素個(gè)數(shù)很少�,速度很快�����;當(dāng)元素基本有序了��,步長(zhǎng)很小�����,插入排序?qū)τ谟行虻男蛄行屎芨摺K?�,希爾排序的時(shí)間復(fù)雜度會(huì)比o(n^2)好一些�����。
冒泡排序算法介紹
假如一個(gè)數(shù)組有n個(gè)數(shù)���,那么我們可以從第一個(gè)數(shù)開(kāi)始從頭到尾兩兩比較,當(dāng)前一個(gè)數(shù)比后一個(gè)數(shù)大時(shí)����,則交換他們的位置,直到最大的一個(gè)數(shù)被排在了數(shù)組的后尾�。然后最后一個(gè)數(shù)固定,不再需要比較�����,只需要按照剛剛的方法重復(fù)比較前面的n-1個(gè)數(shù)���,知道排出順序���。
快速排序算法介紹
快速排序(Quicksort)是對(duì)冒泡排序的一種改進(jìn)。
它的基本思想是:通過(guò)一趟排序?qū)⒁判虻臄?shù)據(jù)分割成獨(dú)立的兩部分��,其中一部分的所有數(shù)據(jù)都比另外一部分的所有數(shù)據(jù)都要小,然后再按此方法對(duì)這兩部分?jǐn)?shù)據(jù)分別進(jìn)行快速排序�,整個(gè)排序過(guò)程可以遞歸進(jìn)行,以此達(dá)到整個(gè)數(shù)據(jù)變成有序序列���。
設(shè)要排序的數(shù)組是A[0]……A[N-1]�����,首先任意選取一個(gè)數(shù)據(jù)(通常選用第一個(gè)數(shù)據(jù))作為關(guān)鍵數(shù)據(jù)�,然后將所有比它小的數(shù)都放到它前面����,所有比它大的數(shù)都放到它后面,這個(gè)過(guò)程稱為一趟快速排序����。
算法是:
1)設(shè)置兩個(gè)變量I、J��,排序開(kāi)始的時(shí)候:I=0��,J=N-1���;
2)以第一個(gè)數(shù)組元素作為關(guān)鍵數(shù)據(jù)���,賦值給key���,即 key=A[0]�;
3)從J開(kāi)始向前搜索,即由后開(kāi)始向前搜索(J=J-1)�����,找到第一個(gè)小于key的值A(chǔ)[J]���,并與key交換����;
4)從I開(kāi)始向后搜索����,即由前開(kāi)始向后搜索(I=I+1),找到第一個(gè)大于key的A[I]��,與key交換����;
5)重復(fù)第3��、4����、5步�����,直到 I=J���; (3,4步是在程序中沒(méi)找到時(shí)候j=j-1�����,i=i+1���,直至找到為止。找到并交換的時(shí)候i���, j指針位置不變���。另外當(dāng)i=j這過(guò)程一定正好是i+或j-完成的最后另循環(huán)結(jié)束���。)
選擇排序算法介紹
選擇排序的基本思想:第1趟,在待排序記錄r[1]~r[n]中選出最小的記錄����,將它與r[1]交換;第2趟��,在待排序記錄r[2]~r[n]中選出最小的記錄���,將它與r[2]交換;以此類推�,第i趟在待排序記錄r[i]~r[n]中選出最小的記錄,將它與r[i]交換����,使有序序列不斷增長(zhǎng)直到全部排序完畢。
歸并排序算法介紹
歸并排序(MERGE-SORT)是建立在歸并操作上的一種有效的排序算法,該算法是采用分治法(Divide and
Conquer)的一個(gè)非常典型的應(yīng)用����。將已有序的子序列合并,得到完全有序的序列����;即先使每個(gè)子序列有序����,再使子序列段間有序��。若將兩個(gè)有序表合并成一個(gè)有序表�����,稱為二路歸并���。
歸并過(guò)程為:比較a[i]和a[j]的大小�,若a[i]≤a[j]����,則將第一個(gè)有序表中的元素a[i]復(fù)制到r[k]中,并令i和k分別加上1���;否則將第二個(gè)有序表中的元素a[j]復(fù)制到r[k]中�����,并令j和k分別加上1�����,如此循環(huán)下去�����,直到其中一個(gè)有序表取完�����,然后再將另一個(gè)有序表中剩余的元素復(fù)制到r中從下標(biāo)k到下標(biāo)t的單元����。歸并排序的算法我們通常用遞歸實(shí)現(xiàn),先把待排序區(qū)間[s,t]以中點(diǎn)二分�����,接著把左邊子區(qū)間排序�,再把右邊子區(qū)間排序���,最后把左區(qū)間和右區(qū)間用一次歸并操作合并成有序的區(qū)間[s,t]����。
基數(shù)排序算法介紹
基數(shù)排序與本系列前面講解的七種排序方法都不同����,它不需要比較關(guān)鍵字的大小�。
它是根據(jù)關(guān)鍵字中各位的值��,通過(guò)對(duì)排序的N個(gè)元素進(jìn)行若干趟“分配”與“收集”來(lái)實(shí)現(xiàn)排序的����。
不妨通過(guò)一個(gè)具體的實(shí)例來(lái)展示一下,基數(shù)排序是如何進(jìn)行的��。 設(shè)有一個(gè)初始序列為: R {50, 123, 543, 187, 49, 30,
0, 2, 11, 100}���。我們知道��,任何一個(gè)阿拉伯?dāng)?shù)���,它的各個(gè)位數(shù)上的基數(shù)都是以0~9來(lái)表示的。所以我們不妨把0~9視為10個(gè)桶�。
我們先根據(jù)序列的個(gè)位數(shù)的數(shù)字來(lái)進(jìn)行分類,將其分到指定的桶中����。例如:R[0] = 50,個(gè)位數(shù)上是0��,將這個(gè)數(shù)存入編號(hào)為0的桶中。(如圖1)
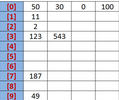
圖1 基數(shù)排序
分類后�����,我們?cè)趶母鱾€(gè)桶中����,將這些數(shù)按照從編號(hào)0到編號(hào)9的順序依次將所有數(shù)取出來(lái)。
這時(shí)���,得到的序列就是個(gè)位數(shù)上呈遞增趨勢(shì)的序列�。
按照個(gè)位數(shù)排序: {50, 30, 0, 100, 11, 2, 123, 543, 187, 49}��。
接下來(lái)��,可以對(duì)十位數(shù)���、百位數(shù)也按照這種方法進(jìn)行排序,最后就能得到排序完成的序列��。
CDA數(shù)據(jù)分析師考試相關(guān)入口一覽(建議收藏):
? 想報(bào)名CDA認(rèn)證考試��,點(diǎn)擊>>>
“CDA報(bào)名”
了解CDA考試詳情���;
? 想學(xué)習(xí)CDA考試教材�,點(diǎn)擊>>> “CDA教材” 了解CDA考試詳情;
? 想加入CDA考試題庫(kù)����,點(diǎn)擊>>> “CDA題庫(kù)” 了解CDA考試詳情;
? 想了解CDA考試含金量���,點(diǎn)擊>>> “CDA含金量” 了解CDA考試詳情���;











 京公網(wǎng)安備 11010802034615號(hào)
經(jīng)營(yíng)許可證編號(hào):京B2-20210330
京公網(wǎng)安備 11010802034615號(hào)
經(jīng)營(yíng)許可證編號(hào):京B2-20210330