數(shù)據(jù)預(yù)處理的一些知識
做研究時只要與數(shù)據(jù)分析相關(guān)就避免不了數(shù)據(jù)預(yù)處理��。我們常見的預(yù)處理包括:標(biāo)準(zhǔn)化(規(guī)范化)����,歸一化����,零均值(化),白化���,正則化……這些預(yù)處理的目的是什么呢�����?網(wǎng)上查的總是零零散散���,很難搞清楚����。因此我用此片博客來總結(jié)下��。借鑒其他博客的內(nèi)容��,可能未一一注明還請諒解�。
一,數(shù)據(jù)標(biāo)準(zhǔn)化
目的:為了消除量綱影響和變量自身數(shù)值大小的影響�����,方便統(tǒng)計處理(尤其是加權(quán))���,故將數(shù)據(jù)標(biāo)準(zhǔn)化�。
例如:我們對一個人提取特征時獲得:年齡20歲�,身高183cm,體重70kg���。第二個人:年齡14歲,身高160cm�,體重60kg�����。我們在計算兩個人的差距的時候如果這樣計算:20-14+183-160+70-60=39���。是不是感覺有問題,39中一個身高占了23�����,一半以上(似乎自己加了權(quán)值�,還挺大,我們需要自己設(shè)定權(quán)值)����。這就是因為沒有標(biāo)準(zhǔn)化,使得個別變量過大產(chǎn)生的問題���。
方法:
1���、Min-max 標(biāo)準(zhǔn)化
min-max標(biāo)準(zhǔn)化方法是對原始數(shù)據(jù)進(jìn)行線性變換。將某一屬性的一個原始值x通過min-max標(biāo)準(zhǔn)化映射成在區(qū)間[0,1]中的值x′�����,其公式為:
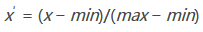
2、z-score標(biāo)準(zhǔn)化
這種方法基于原始數(shù)據(jù)的均值(mean)和標(biāo)準(zhǔn)差(standard deviation)進(jìn)行數(shù)據(jù)的標(biāo)準(zhǔn)化����。將A的原始值x使用z-score標(biāo)準(zhǔn)化到x′。z-score標(biāo)準(zhǔn)化方法適用于屬性A的最大值和最小值未知的情況�����,或有超出取值范圍的離群數(shù)據(jù)的情況�����。
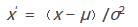
3��、其他標(biāo)準(zhǔn)化
Decimal scaling小數(shù)定標(biāo)標(biāo)準(zhǔn)化:這種方法通過移動數(shù)據(jù)的小數(shù)點位置來進(jìn)行標(biāo)準(zhǔn)化����。小數(shù)點移動多少位取決于屬性A的取值中的最大絕對值。將屬性A的原始值x使用decimal scaling標(biāo)準(zhǔn)化到x′的計算方法是:x′=x/(10?j)其中����,j是滿足條件的最小整數(shù)。例如假定A的值由-986到917���,A的最大絕對值為986�����,為使用小數(shù)定標(biāo)標(biāo)準(zhǔn)化��,我們用1000(即�,j=3)除以每個值��,這樣��,-986被規(guī)范化為-0.986����。
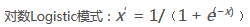
注意,標(biāo)準(zhǔn)化會對原始數(shù)據(jù)做出改變�����,因此需要保存所使用的標(biāo)準(zhǔn)化方法的參數(shù)����,以便對后續(xù)的數(shù)據(jù)進(jìn)行統(tǒng)一的標(biāo)準(zhǔn)化。以上公式中所提高的極大值�,極小值,方差等均是某一屬性的�,并非所有屬性�����。標(biāo)準(zhǔn)化之后數(shù)據(jù)均值為0方差為1��,數(shù)據(jù)可正可負(fù)�����。
二���,歸一化
目的:消除量綱和過大數(shù)據(jù)的影響,同時提高計算時的收斂速度��。
知乎上有個解釋:雖然同樣作出了歸一化���,但歸一化的目的卻各不相同��。對于不同的模型�,不同的業(yè)務(wù)����,歸一化就會有不同的意義。
我本人總結(jié)如下:
1)無量綱化:
還是上面例子:年齡20歲,身高183cm�����,體重70kg��。183cm在數(shù)值上比20歲大得多���,但實際上這兩個對于衡量一個人的特征同等重要,因此將各個屬性進(jìn)行歸一化�����,純數(shù)值對待�����。(注意和標(biāo)準(zhǔn)化時數(shù)據(jù)使用的目的不同)
2)避免數(shù)值問題:
太大的數(shù)會引發(fā)數(shù)值問題����。
3)一些模型求解的需要:
例如梯度下降法。一種情況—–不歸一化��,容易產(chǎn)生陜谷����,而學(xué)習(xí)率較大時�,以之字形下降�����。學(xué)習(xí)率較小��,則會產(chǎn)生直角形路線����,速度較快。
方法:
歸一化的映射函數(shù)并不固定��。例如matlab中的mapminmax函數(shù)
y=(ymax?ymin)?(x?xmin)/(xmax?xmin)+ymin
其中ymax��,ymin�,為自己定義的,一般默認(rèn)[-1,1]�����,也可以自己修改����。
以下方法為基礎(chǔ)方法����。
1�、線性函數(shù)轉(zhuǎn)換:
y=(x?min)/(max?min)
說明:x、y分別為轉(zhuǎn)換前��、后的值���,max�、min分別為樣本(與標(biāo)準(zhǔn)化對照下看區(qū)別)的最大值和最小值��。
2�、對數(shù)函數(shù)轉(zhuǎn)換:
y=log10(x)
說明:以10為底的對數(shù)函數(shù)轉(zhuǎn)換���。
例如:常用將數(shù)據(jù)歸一到[0,1]
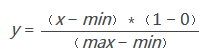
區(qū)別標(biāo)準(zhǔn)化和歸一化
標(biāo)準(zhǔn)化和歸一化的處理目的不同�。在做統(tǒng)計學(xué)時經(jīng)常用到標(biāo)準(zhǔn)化(數(shù)據(jù)可正可負(fù))��,在進(jìn)行數(shù)據(jù)挖掘的時候經(jīng)常用到歸一化(所有數(shù)據(jù)在一個具體區(qū)間內(nèi))�,SVM和BP神經(jīng)網(wǎng)絡(luò)在輸入數(shù)據(jù)前進(jìn)行歸一化可以顯著提高準(zhǔn)確率和速度。
應(yīng)用歸一化時所面臨的問題:
(1)是對每一個樣本進(jìn)行進(jìn)行歸一化(按行歸一化)還是對每一個維度進(jìn)行歸一化(按列歸一化)�?
(2)是將訓(xùn)練集和測試集分別歸一化還是放在一起形成一個大矩陣一起進(jìn)行歸一化?
三�,零均值
將數(shù)據(jù)轉(zhuǎn)化為均值為零的數(shù)據(jù)。z-score方法也可以將作為零均值化的方法。例如:23 20 40 35
34均值為:30.4�,方差:72.3;z-score標(biāo)準(zhǔn)化后的數(shù)據(jù) -0.1024 -0.1438 0.1328 0.0636
0.0498��,均值為?5.5511?10?18,注意零均值一般操作在同一樣本的不同屬性之間�����,和z-score用于標(biāo)準(zhǔn)化用作統(tǒng)計學(xué)時的目的不同��。
四�����,白化
白化:又稱漂白或者球化����;是對原始數(shù)據(jù)x實現(xiàn)一種變換,變換成x′�;使x′的協(xié)方差矩陣的為單位陣。斯坦福的一篇關(guān)于白化的教程提到:由于原始圖像相鄰像素值具有高度相關(guān)性����,所以圖像數(shù)據(jù)信息冗余,對于白化的作用的描述主要有兩個方面:1���,減少特征之間的相關(guān)性�;2,特征具有相同的方差(協(xié)方差陣為1)����;一般用在深度學(xué)習(xí)中的圖像預(yù)處理。
步驟:
隨機(jī)向量的“零均值化”和“空間解相關(guān)”是最常用的兩個預(yù)處理過程����,其中“零均值化”如上,而“空間解相關(guān)”如下矩陣處理:
若一零均值的隨機(jī)向量Z=[z1,z2,....zm]����,滿足E{Z?Z′}=I�,I為單位矩陣,我們稱這個向量為白色向量���。白化的本質(zhì)在于去相關(guān)�����,這個同PCA原理相似�;在ICA(獨立成分分析)中��,對于為零均值的獨立源信號當(dāng)i!=j時,S(t)=[s1(t),s2(t)......sn(t)]�����,有E{Si?Sj}=E{Si}?E{Sj}=0,且協(xié)方差矩陣是單位陣cov(S)=I,(零均值時相關(guān)系數(shù)矩陣和協(xié)方差矩陣相等)�����,因此�����,源信號是白色的���。對觀測信號X(t),我們應(yīng)該尋找一個線性變換�,使X(t)投影到新的子空間后變成白化向量,即:
Z(t)=W0?X(t)
其中W0為白化矩陣�����,Z為白化向量
利用主分量分析����,我們通過計算樣本向量得到一個變換:
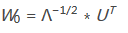
其中Λ和U分別代表協(xié)方差矩陣的特征向量矩陣和特征值矩陣�?���?梢宰C明,線性變換W0滿足白化變換的要求��。通過正交變換�����,可以保證U′?U=U?U′=I���。因此通過協(xié)方差陣:
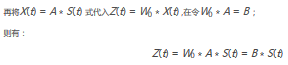
由于線性變換連接的是兩個白色隨機(jī)矢量Z(t)和S(t)�����,可以得出B一定是一個正交變換�。如果把上式中Z(t)的看作新的觀測信號�,那么可以說�����,白化使原來的混合矩陣A簡化成一個新的正交矩陣B�。
五����,正則化:
目的:對最小化經(jīng)驗誤差函數(shù)上加約束�����,解決了逆問題的不適定性���,產(chǎn)生的解是存在���,唯一,同時降低依賴于數(shù)據(jù)的噪聲對不適定的影響����,解就不會過擬合,而且如果先驗(正則化)合適�,則解就傾向于是符合真解(更不會過擬合了),即使訓(xùn)練集中彼此間不相關(guān)的樣本數(shù)很少�。
正則化在不同的領(lǐng)域又有著不同的含義,我們說的正則化一般就是數(shù)據(jù)過擬合�。這個處理過程嚴(yán)格的來說并不是
方法:正則化過程在公式中主要以正則項的方式體現(xiàn),不過正則項的一些知識本人實在難以以自己的理解寫出來�,不過知乎上有一些回答很棒。
統(tǒng)計學(xué)中的幾種類型數(shù)據(jù)
統(tǒng)計學(xué)中����,統(tǒng)計數(shù)據(jù)可分為四種類型(級別從低到高):定類數(shù)據(jù)/定序數(shù)據(jù)/定距數(shù)據(jù)/定比數(shù)據(jù)����。定類數(shù)據(jù)僅標(biāo)識不同的類別���,沒有次序關(guān)系(eg:漢族���、藏族、回族)�����;定序數(shù)據(jù)用數(shù)字表示某個有序狀態(tài)所處的位置�,可以比較大小(有次序)�����,但是不能做四則預(yù)算(eg:年齡劃分為老����、中�����、青);定距數(shù)據(jù)是具有間距的變量����,有單位,無零點�,只能加減不能乘除(eg:智商120,比智商60要高60����,但不能說前者智商是后者兩倍,因為智商為0不是絕對零點�����,不代表沒有智商)����;定比數(shù)據(jù)除了有定局?jǐn)?shù)據(jù)的特性之外,還有一個絕對零點���,所以能加減也能乘除(eg:60元比30元多30元�,且前者是后者的兩倍)。
CDA數(shù)據(jù)分析師考試相關(guān)入口一覽(建議收藏):
? 想報名CDA認(rèn)證考試����,點擊>>>
“CDA報名”
了解CDA考試詳情;
? 想學(xué)習(xí)CDA考試教材��,點擊>>> “CDA教材” 了解CDA考試詳情�;
? 想加入CDA考試題庫,點擊>>> “CDA題庫” 了解CDA考試詳情���;
? 想了解CDA考試含金量�,點擊>>> “CDA含金量” 了解CDA考試詳情���;











 京公網(wǎng)安備 11010802034615號
經(jīng)營許可證編號:京B2-20210330
京公網(wǎng)安備 11010802034615號
經(jīng)營許可證編號:京B2-20210330