Python語(yǔ)言描述隨機(jī)梯度下降法
1.梯度下降
1)什么是梯度下降�?
因?yàn)樘荻认陆凳且环N思想,沒(méi)有嚴(yán)格的定義��,所以用一個(gè)比喻來(lái)解釋什么是梯度下降���。

簡(jiǎn)單來(lái)說(shuō)��,梯度下降就是從山頂找一條最短的路走到山腳最低的地方���。但是因?yàn)檫x擇方向的原因�����,我們找到的的最低點(diǎn)可能不是真正的最低點(diǎn)���。如圖所示,黑線標(biāo)注的路線所指的方向并不是真正的地方�。
既然是選擇一個(gè)方向下山,那么這個(gè)方向怎么選����?每次該怎么走?
先說(shuō)選方向���,在算法中是以隨機(jī)方式給出的����,這也是造成有時(shí)候走不到真正最低點(diǎn)的原因����。
如果選定了方向�����,以后每走一步,都是選擇最陡的方向�,直到最低點(diǎn)。
總結(jié)起來(lái)就一句話:隨機(jī)選擇一個(gè)方向����,然后每次邁步都選擇最陡的方向,直到這個(gè)方向上能達(dá)到的最低點(diǎn)���。
2)梯度下降是用來(lái)做什么的?
在機(jī)器學(xué)習(xí)算法中,有時(shí)候需要對(duì)原始的模型構(gòu)建損失函數(shù),然后通過(guò)優(yōu)化算法對(duì)損失函數(shù)進(jìn)行優(yōu)化���,以便尋找到最優(yōu)的參數(shù),使得損失函數(shù)的值最小�。而在求解機(jī)器學(xué)習(xí)參數(shù)的優(yōu)化算法中,使用較多的就是基于梯度下降的優(yōu)化算法(GradientDescent,GD)��。
3)優(yōu)缺點(diǎn)
優(yōu)點(diǎn):效率���。在梯度下降法的求解過(guò)程中����,只需求解損失函數(shù)的一階導(dǎo)數(shù)���,計(jì)算的代價(jià)比較小���,可以在很多大規(guī)模數(shù)據(jù)集上應(yīng)用
缺點(diǎn):求解的是局部最優(yōu)值�����,即由于方向選擇的問(wèn)題�����,得到的結(jié)果不一定是全局最優(yōu)
步長(zhǎng)選擇�����,過(guò)小使得函數(shù)收斂速度慢��,過(guò)大又容易找不到最優(yōu)解��。
2.梯度下降的變形形式
根據(jù)處理的訓(xùn)練數(shù)據(jù)的不同���,主要有以下三種形式:
1)批量梯度下降法BGD(BatchGradientDescent):
針對(duì)的是整個(gè)數(shù)據(jù)集,通過(guò)對(duì)所有的樣本的計(jì)算來(lái)求解梯度的方向���。
優(yōu)點(diǎn):全局最優(yōu)解���;易于并行實(shí)現(xiàn);
缺點(diǎn):當(dāng)樣本數(shù)據(jù)很多時(shí)����,計(jì)算量開銷大,計(jì)算速度慢
2)小批量梯度下降法MBGD(mini-batchGradientDescent)
把數(shù)據(jù)分為若干個(gè)批����,按批來(lái)更新參數(shù),這樣�����,一個(gè)批中的一組數(shù)據(jù)共同決定了本次梯度的方向�,下降起來(lái)就不容易跑偏,減少了隨機(jī)性
優(yōu)點(diǎn):減少了計(jì)算的開銷量����,降低了隨機(jī)性
3)隨機(jī)梯度下降法SGD(stochasticgradientdescent)
每個(gè)數(shù)據(jù)都計(jì)算算一下損失函數(shù),然后求梯度更新參數(shù)����。
優(yōu)點(diǎn):計(jì)算速度快
缺點(diǎn):收斂性能不好
總結(jié):SGD可以看作是MBGD的一個(gè)特例,及batch_size=1的情況����。在深度學(xué)習(xí)及機(jī)器學(xué)習(xí)中�,基本上都是使用的MBGD算法���。
3.隨機(jī)梯度下降
隨機(jī)梯度下降(SGD)是一種簡(jiǎn)單但非常有效的方法�����,多用用于支持向量機(jī)�����、邏輯回歸等凸損失函數(shù)下的線性分類器的學(xué)習(xí)���。并且SGD已成功應(yīng)用于文本分類和自然語(yǔ)言處理中經(jīng)常遇到的大規(guī)模和稀疏機(jī)器學(xué)習(xí)問(wèn)題。
SGD既可以用于分類計(jì)算���,也可以用于回歸計(jì)算��。
1)分類
a)核心函數(shù)
sklearn.linear_model.SGDClassifier
b)主要參數(shù)(詳細(xì)參數(shù))
loss:指定損失函數(shù)��?���?蛇x值:‘hinge'(默認(rèn)),‘log',‘modified_huber',‘squared_hinge',‘perceptron',
"hinge":線性SVM
"log":邏輯回歸
"modified_huber":平滑損失,基于異常值容忍和概率估計(jì)
"squared_hinge":帶有二次懲罰的線性SVM
"perceptron":帶有線性損失的感知器
alpha:懲罰系數(shù)
c)示例代碼及詳細(xì)解釋
fromsklearn.linear_modelimportSGDClassifier
fromsklearn.datasets.samples_generatorimportmake_blobs
##生產(chǎn)數(shù)據(jù)
X, Y=make_blobs(n_samples=50, centers=2, random_state=0, cluster_std=0.60)
##訓(xùn)練數(shù)據(jù)
clf=SGDClassifier(loss="hinge", alpha=0.01)
clf.fit(X, Y)
## 繪圖
xx=np.linspace(-1,5,10)
yy=np.linspace(-1,5,10)
##生成二維矩陣
X1, X2=np.meshgrid(xx, yy)
##生產(chǎn)一個(gè)與X1相同形狀的矩陣
Z=np.empty(X1.shape)
##np.ndenumerate 返回矩陣中每個(gè)數(shù)的值及其索引
for(i, j), valinnp.ndenumerate(X1):
x1=val
x2=X2[i, j]
p=clf.decision_function([[x1, x2]])##樣本到超平面的距離
Z[i, j]=p[0]
levels=[-1.0,0.0,1.0]
linestyles=['dashed','solid','dashed']
colors='k'
##繪制等高線:Z分別等于levels
plt.contour(X1, X2, Z, levels, colors=colors, linestyles=linestyles)
##畫數(shù)據(jù)點(diǎn)
plt.scatter(X[:,0], X[:,1], c=Y, cmap=plt.cm.Paired,
edgecolor='black', s=20)
plt.axis('tight')
plt.show()
d)結(jié)果圖
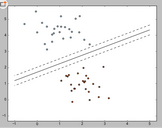
2)回歸
SGDRegressor非常適合回歸問(wèn)題具有大量訓(xùn)練樣本(>10000)�,對(duì)于其他的問(wèn)題,建議使用的Ridge���,Lasso或ElasticNet。
a)核心函數(shù)
sklearn.linear_model.SGDRegressor
b)主要參數(shù)(詳細(xì)參數(shù))
loss:指定損失函數(shù)�����?��?蛇x值‘squared_loss'(默認(rèn)),‘huber',‘epsilon_insensitive',‘squared_epsilon_insensitive'
說(shuō)明:此參數(shù)的翻譯不是特別準(zhǔn)確���,請(qǐng)參考官方文檔。
"squared_loss":采用普通最小二乘法
"huber":使用改進(jìn)的普通最小二乘法���,修正異常值
"epsilon_insensitive":忽略小于epsilon的錯(cuò)誤
"squared_epsilon_insensitive":
alpha:懲罰系數(shù)
c)示例代碼
因?yàn)槭褂梅绞脚c其他線性回歸方式類似�����,所以這里只舉個(gè)簡(jiǎn)單的例子:
fromsklearnimportlinear_model
n_samples, n_features=10,5
np.random.seed(0)
y=np.random.randn(n_samples)
X=np.random.randn(n_samples, n_features)
clf=linear_model.SGDRegressor()
clf.fit(X, y)
總結(jié)
以上就是本文關(guān)于Python語(yǔ)言描述隨機(jī)梯度下降法的全部?jī)?nèi)容�,希望對(duì)大家有所幫助�����。
CDA數(shù)據(jù)分析師考試相關(guān)入口一覽(建議收藏):
? 想報(bào)名CDA認(rèn)證考試,點(diǎn)擊>>>
“CDA報(bào)名”
了解CDA考試詳情��;
? 想學(xué)習(xí)CDA考試教材�,點(diǎn)擊>>> “CDA教材” 了解CDA考試詳情;
? 想加入CDA考試題庫(kù)���,點(diǎn)擊>>> “CDA題庫(kù)” 了解CDA考試詳情����;
? 想了解CDA考試含金量���,點(diǎn)擊>>> “CDA含金量” 了解CDA考試詳情�����;











 京公網(wǎng)安備 11010802034615號(hào)
經(jīng)營(yíng)許可證編號(hào):京B2-20210330
京公網(wǎng)安備 11010802034615號(hào)
經(jīng)營(yíng)許可證編號(hào):京B2-20210330