深入剖析Python的爬蟲框架Scrapy的結(jié)構(gòu)與運(yùn)作流程
網(wǎng)絡(luò)爬蟲(Web Crawler,
Spider)就是一個(gè)在網(wǎng)絡(luò)上亂爬的機(jī)器人�。當(dāng)然它通常并不是一個(gè)實(shí)體的機(jī)器人�,因?yàn)榫W(wǎng)絡(luò)本身也是虛擬的東西����,所以這個(gè)“機(jī)器人”其實(shí)也就是一段程序�,并且它也不是亂爬,而是有一定目的的�����,并且在爬行的時(shí)候會(huì)搜集一些信息�。例如
Google 就有一大堆爬蟲會(huì)在 Internet 上搜集網(wǎng)頁內(nèi)容以及它們之間的鏈接等信息;又比如一些別有用心的爬蟲會(huì)在 Internet
上搜集諸如 foo@bar.com 或者 foo [at] bar [dot] com
之類的東西��。除此之外,還有一些定制的爬蟲����,專門針對某一個(gè)網(wǎng)站,例如前一陣子 JavaEye 的 Robbin 就寫了幾篇專門對付惡意爬蟲的
blog (原文鏈接似乎已經(jīng)失效了��,就不給了)��,還有諸如小眾軟件或者 LinuxToy 這樣的網(wǎng)站也經(jīng)常被整個(gè)站點(diǎn) crawl
下來�,換個(gè)名字掛出來。其實(shí)爬蟲從基本原理上來講很簡單���,只要能訪問網(wǎng)絡(luò)和分析 Web 頁面即可��,現(xiàn)在大部分語言都有方便的 Http
客戶端庫可以抓取 Web 頁面�����,而 HTML
的分析最簡單的可以直接用正則表達(dá)式來做,因此要做一個(gè)最簡陋的網(wǎng)絡(luò)爬蟲實(shí)際上是一件很簡單的事情��。不過要實(shí)現(xiàn)一個(gè)高質(zhì)量的 spider
卻是非常難的���。
爬蟲的兩部分�����,一是下載 Web 頁面�����,有許多問題需要考慮�,如何最大程度地利用本地帶寬,如何調(diào)度針對不同站點(diǎn)的 Web
請求以減輕對方服務(wù)器的負(fù)擔(dān)等�。一個(gè)高性能的 Web Crawler 系統(tǒng)里,DNS
查詢也會(huì)成為急需優(yōu)化的瓶頸���,另外�,還有一些“行規(guī)”需要遵循(例如
robots.txt)��。而獲取了網(wǎng)頁之后的分析過程也是非常復(fù)雜的���,Internet 上的東西千奇百怪����,各種錯(cuò)誤百出的 HTML
頁面都有�,要想全部分析清楚幾乎是不可能的事;另外��,隨著 AJAX 的流行,如何獲取由 Javascript
動(dòng)態(tài)生成的內(nèi)容成了一大難題���;除此之外�����,Internet 上還有有各種有意或無意出現(xiàn)的 Spider Trap
���,如果盲目的跟蹤超鏈接的話,就會(huì)陷入 Trap 中萬劫不復(fù)了���,例如這個(gè)網(wǎng)站����,據(jù)說是之前 Google 宣稱 Internet 上的 Unique
URL 數(shù)目已經(jīng)達(dá)到了 1 trillion 個(gè)����,因此這個(gè)人 is proud to announce the second trillion
。 :D
不過��,其實(shí)并沒有多少人需要做像 Google 那樣通用的 Crawler ���,通常我們做一個(gè) Crawler
就是為了去爬特定的某個(gè)或者某一類網(wǎng)站�����,所謂知己知彼�,百戰(zhàn)不殆����,我們可以事先對需要爬的網(wǎng)站結(jié)構(gòu)做一些分析,事情就變得容易多了��。通過分析�,選出有價(jià)值的鏈接進(jìn)行跟蹤,就可以避免很多不必要的鏈接或者
Spider Trap ��,如果網(wǎng)站的結(jié)構(gòu)允許選擇一個(gè)合適的路徑的話����,我們可以按照一定順序把感興趣的東西爬一遍,這樣以來���,連 URL
重復(fù)的判斷也可以省去���。
舉個(gè)例子,假如我們想把 pongba 的 blog mindhacks.cn 里面的 blog 文字爬下來����,通過觀察�����,很容易發(fā)現(xiàn)我們對其中的兩種頁面感興趣:
文章列表頁面���,例如首頁,或者 URL 是 /page/\d+/ 這樣的頁面����,通過 Firebug 可以看到到每篇文章的鏈接都是在一個(gè) h1
下的 a 標(biāo)簽里的(需要注意的是,在 Firebug 的 HTML 面板里看到的 HTML 代碼和 View Source
所看到的也許會(huì)有些出入����,如果網(wǎng)頁中有 Javascript 動(dòng)態(tài)修改 DOM 樹的話,前者是被修改過的版本�,并且經(jīng)過 Firebug
規(guī)則化的,例如 attribute 都有引號擴(kuò)起來等�����,而后者通常才是你的 spider
爬到的原始內(nèi)容���。如果是使用正則表達(dá)式對頁面進(jìn)行分析或者所用的 HTML Parser 和 Firefox
的有些出入的話����,需要特別注意)��,另外��,在一個(gè) class 為 wp-pagenavi 的 div 里有到不同列表頁面的鏈接��。
文章內(nèi)容頁面��,每篇 blog 有這樣一個(gè)頁面�,例如 /2008/09/11/machine-learning-and-ai-resources/ ,包含了完整的文章內(nèi)容���,這是我們感興趣的內(nèi)容����。
因此��,我們從首頁開始��,通過 wp-pagenavi 里的鏈接來得到其他的文章列表頁面����,特別地����,我們定義一個(gè)路徑:只 follow Next
Page
的鏈接����,這樣就可以從頭到尾按順序走一遍,免去了需要判斷重復(fù)抓取的煩惱��。另外�,文章列表頁面的那些到具體文章的鏈接所對應(yīng)的頁面就是我們真正要保存的數(shù)據(jù)頁面了。
這樣以來�����,其實(shí)用腳本語言寫一個(gè) ad hoc 的 Crawler 來完成這個(gè)任務(wù)也并不難�����,不過今天的主角是 Scrapy ����,這是一個(gè)用
Python 寫的 Crawler Framework
,簡單輕巧���,并且非常方便��,并且官網(wǎng)上說已經(jīng)在實(shí)際生產(chǎn)中在使用了�,因此并不是一個(gè)玩具級別的東西�。不過現(xiàn)在還沒有 Release
版本,可以直接使用他們的 Mercurial
倉庫里抓取源碼進(jìn)行安裝��。不過�,這個(gè)東西也可以不安裝直接使用,這樣還方便隨時(shí)更新�����,文檔里說得很詳細(xì)�,我就不重復(fù)了。
Scrapy 使用 Twisted 這個(gè)異步網(wǎng)絡(luò)庫來處理網(wǎng)絡(luò)通訊�����,架構(gòu)清晰���,并且包含了各種中間件接口����,可以靈活的完成各種需求。整體架構(gòu)如下圖所示:
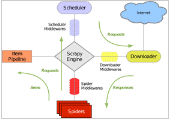
綠線是數(shù)據(jù)流向�����,首先從初始 URL 開始����,Scheduler 會(huì)將其交給 Downloader 進(jìn)行下載,下載之后會(huì)交給 Spider
進(jìn)行分析���,Spider 分析出來的結(jié)果有兩種:一種是需要進(jìn)一步抓取的鏈接����,例如之前分析的“下一頁”的鏈接��,這些東西會(huì)被傳回 Scheduler
�����;另一種是需要保存的數(shù)據(jù)�,它們則被送到 Item Pipeline
那里,那是對數(shù)據(jù)進(jìn)行后期處理(詳細(xì)分析���、過濾��、存儲(chǔ)等)的地方��。另外��,在數(shù)據(jù)流動(dòng)的通道里還可以安裝各種中間件�����,進(jìn)行必要的處理��。
具體的內(nèi)容在最后的附屬中還會(huì)介紹�。
看起來好像很復(fù)雜�,其實(shí)用起來很簡單,就如同 Rails 一樣�,首先新建一個(gè)工程:
scrapy-admin.py startproject blog_crawl
會(huì)創(chuàng)建一個(gè) blog_crawl 目錄,里面有個(gè) scrapy-ctl.py 是整個(gè)項(xiàng)目的控制腳本���,而代碼全都放在子目錄
blog_crawl 里面����。為了能抓取 mindhacks.cn �,我們在 spiders 目錄里新建一個(gè)mindhacks_spider.py
,定義我們的 Spider 如下:
from
scrapy.spiderimportBaseSpider
classMindhacksSpider(BaseSpider):
domain_name="mindhacks.cn"
start_urls=["http://mindhacks.cn/"]
defparse(self, response):
return[]
SPIDER=MindhacksSpider()
我們的 MindhacksSpider 繼承自 BaseSpider (通常直接繼承自功能更豐富的
scrapy.contrib.spiders.CrawlSpider 要方便一些���,不過為了展示數(shù)據(jù)是如何 parse 的�,這里還是使用
BaseSpider 了),變量 domain_name 和 start_urls 都很容易明白是什么意思��,而 parse
方法是我們需要定義的回調(diào)函數(shù)�,默認(rèn)的 request 得到 response
之后會(huì)調(diào)用這個(gè)回調(diào)函數(shù),我們需要在這里對頁面進(jìn)行解析����,返回兩種結(jié)果(需要進(jìn)一步 crawl
的鏈接和需要保存的數(shù)據(jù)),讓我感覺有些奇怪的是�,它的接口定義里這兩種結(jié)果竟然是混雜在一個(gè) list
里返回的,不太清楚這里為何這樣設(shè)計(jì)�,難道最后不還是要費(fèi)力把它們分開?總之這里我們先寫一個(gè)空函數(shù)��,只返回一個(gè)空列表����。另外,定義一個(gè)“全局”變量
SPIDER �,它會(huì)在 Scrapy 導(dǎo)入這個(gè) module 的時(shí)候?qū)嵗⒆詣?dòng)被 Scrapy 的引擎找到�����。這樣就可以先運(yùn)行一下
crawler 試試了:
./
scrapy-ctl.py crawl mindhacks.cn
會(huì)有一堆輸出,可以看到抓取了 http://mindhacks.cn ����,因?yàn)檫@是初始 URL ,但是由于我們在 parse
函數(shù)里沒有返回需要進(jìn)一步抓取的 URL ���,因此整個(gè) crawl 過程只抓取了主頁便結(jié)束了��。接下來便是要對頁面進(jìn)行分析��,Scrapy
提供了一個(gè)很方便的 Shell (需要 IPython )可以讓我們做實(shí)驗(yàn)����,用如下命令啟動(dòng) Shell :
./
scrapy-ctl.py shell http://mindhacks.cn
它會(huì)啟動(dòng) crawler ��,把命令行指定的這個(gè)頁面抓取下來�,然后進(jìn)入 shell ����,根據(jù)提示,我們有許多現(xiàn)成的變量可以用�����,其中一個(gè)就是
hxs ,它是一個(gè) HtmlXPathSelector �,mindhacks 的 HTML 頁面比較規(guī)范,可以很方便的直接用 XPath
進(jìn)行分析���。通過 Firebug 可以看到����,到每篇 blog 文章的鏈接都是在 h1 下的��,因此在 Shell 中使用這樣的 XPath
表達(dá)式測試:
In [1]: hxs.x('//h1/a/@href').extract()
Out[1]:
[u'http://mindhacks.cn/2009/07/06/why-you-should-do-it-yourself/',
u'http://mindhacks.cn/2009/05/17/seven-years-in-nju/',
u'http://mindhacks.cn/2009/03/28/effective-learning-and-memorization/',
u'http://mindhacks.cn/2009/03/15/preconception-explained/',
u'http://mindhacks.cn/2009/03/09/first-principles-of-programming/',
u'http://mindhacks.cn/2009/02/15/why-you-should-start-blogging-now/',
u'http://mindhacks.cn/2009/02/09/writing-is-better-thinking/',
u'http://mindhacks.cn/2009/02/07/better-explained-conflicts-in-intimate-relationship/',
u'http://mindhacks.cn/2009/02/07/independence-day/',
u'http://mindhacks.cn/2009/01/18/escape-from-your-shawshank-part1/']
這正是我們需要的 URL �,另外,還可以找到“下一頁”的鏈接所在�����,連同其他幾個(gè)頁面的鏈接一同在一個(gè) div 里���,不過“下一頁”的鏈接沒有 title 屬性���,因此 XPath 寫作
//div[@class="wp-pagenavi"]/a[not(@title)]
不過如果向后翻一頁的話,會(huì)發(fā)現(xiàn)其實(shí)“上一頁”也是這樣的�����,因此還需要判斷該鏈接上的文字是那個(gè)下一頁的箭頭 u'\xbb' ,本來也可以寫到
XPath 里面去����,但是好像這個(gè)本身是 unicode escape 字符,由于編碼原因理不清楚���,直接放到外面判斷了����,最終 parse
函數(shù)如下:
defparse(self, response):
items=[]
hxs=HtmlXPathSelector(response)
posts=hxs.x('//h1/a/@href').extract()
items.extend([self.make_
requests_from_url(url).replace(callback=self.parse_post)
forurlinposts])
page_links=hxs.x('//div[@class="wp-pagenavi"]/a[not(@title)]')
forlinkinpage_links:
iflink.x('text()').extract()[0]==u'\xbb':
url=link.x('@href').extract()[0]
items.append(self.make_
requests_from_url(url))
returnitems
前半部分是解析需要抓取的 blog 正文的鏈接���,后半部分則是給出“下一頁”的鏈接���。需要注意的是,這里返回的列表里并不是一個(gè)個(gè)的字符串格式的
URL 就完了����,Scrapy 希望得到的是 Request 對象�,這比一個(gè)字符串格式的 URL 能攜帶更多的東西����,諸如 Cookie
或者回調(diào)函數(shù)之類的��?�?梢钥吹轿覀冊趧?chuàng)建 blog 正文的 Request 的時(shí)候替換掉了回調(diào)函數(shù)�,因?yàn)槟J(rèn)的這個(gè)回調(diào)函數(shù) parse
是專門用來解析文章列表這樣的頁面的,而 parse_post 定義如下:
defparse_post(self, response):
item=BlogCrawlItem()
item.url=unicode(response.url)
item.raw=response.body_as_unicode()
return[item]
很簡單�,返回一個(gè) BlogCrawlItem ,把抓到的數(shù)據(jù)放在里面�����,本來可以在這里做一點(diǎn)解析�,例如,通過 XPath
把正文和標(biāo)題等解析出來���,但是我傾向于后面再來做這些事情��,例如 Item Pipeline 或者更后面的 Offline
階段��。BlogCrawlItem 是 Scrapy 自動(dòng)幫我們定義好的一個(gè)繼承自 ScrapedItem 的空類��,在 items.py
中����,這里我加了一點(diǎn)東西:
from
scrapy.itemimportScrapedItem
classBlogCrawlItem(ScrapedItem):
def__init__(self):
ScrapedItem.__init__(self)
self.url=''
def__str__(self):
return'BlogCrawlItem(url: %s)'%self.url
定義了 __str__ 函數(shù)�����,只給出 URL ,因?yàn)槟J(rèn)的 __str__ 函數(shù)會(huì)把所有的數(shù)據(jù)都顯示出來�����,因此會(huì)看到 crawl 的時(shí)候控制臺(tái) log 狂輸出東西��,那是把抓取到的網(wǎng)頁內(nèi)容輸出出來了�。-.-bb
這樣一來,數(shù)據(jù)就取到了����,最后只剩下存儲(chǔ)數(shù)據(jù)的功能,我們通過添加一個(gè) Pipeline 來實(shí)現(xiàn)�����,由于 Python 在標(biāo)準(zhǔn)庫里自帶了 Sqlite3 的支持�����,所以我使用 Sqlite 數(shù)據(jù)庫來存儲(chǔ)數(shù)據(jù)�����。用如下代碼替換 pipelines.py 的內(nèi)容:
importsqlite3
fromosimportpath
from
scrapy.xlib.pydispatchimportdispatcher
class
SQLiteStorePipeline(object):
filename='data.sqlite'
def__init__(self):
self.conn=None
dispatcher.connect(self.initialize, signals.engine_started)
dispatcher.connect(self.finalize, signals.engine_stopped)
defprocess_item(self, domain, item):
self.conn.execute('insert into blog values(?,?,?)',
(item.url, item.raw,unicode(domain)))
returnitem
definitialize(self):
ifpath.exists(self.filename):
self.conn=sqlite3.connect(self.filename)
else:
self.conn=self.create_table(self.filename)
deffinalize(self):
ifself.connisnotNone:
self.conn.commit()
self.conn.close()
self.conn=None
defcreate_table(self, filename):
conn=sqlite3.connect(filename)
conn.execute("""create table blog
(url text primary key, raw text, domain text)""")
conn.commit()
returnconn
在 __init__ 函數(shù)中�,使用 dispatcher 將兩個(gè)信號連接到指定的函數(shù)上,分別用于初始化和關(guān)閉數(shù)據(jù)庫連接(在 close
之前記得 commit ����,似乎是不會(huì)自動(dòng) commit 的,直接 close 的話好像所有的數(shù)據(jù)都丟失了 dd-.-)��。當(dāng)有數(shù)據(jù)經(jīng)過
pipeline 的時(shí)候��,process_item
函數(shù)會(huì)被調(diào)用�����,在這里我們直接講原始數(shù)據(jù)存儲(chǔ)到數(shù)據(jù)庫中��,不作任何處理��。如果需要的話��,可以添加額外的 pipeline
�����,對數(shù)據(jù)進(jìn)行提取、過濾等����,這里就不細(xì)說了。
最后�,在 settings.py 里列出我們的 pipeline :
ITEM_PIPELINES = ['blog_crawl.pipelines.SQLiteStorePipeline']
再跑一下 crawler ,就 OK 啦�����!
PS1:Scrapy的組件
1.Scrapy Engine(Scrapy引擎)
Scrapy引擎是用來控制整個(gè)系統(tǒng)的數(shù)據(jù)處理流程�,并進(jìn)行事務(wù)處理的觸發(fā)。更多的詳細(xì)內(nèi)容可以看下面的數(shù)據(jù)處理流程�����。
2.Scheduler(調(diào)度程序)
調(diào)度程序從Scrapy引擎接受請求并排序列入隊(duì)列�,并在Scrapy引擎發(fā)出請求后返還給它們。
3.Downloader(下載器)
下載器的主要職責(zé)是抓取網(wǎng)頁并將網(wǎng)頁內(nèi)容返還給蜘蛛(Spiders)�。
4.Spiders(蜘蛛)
蜘蛛是有Scrapy用戶自己定義用來解析網(wǎng)頁并抓取制定URL返回的內(nèi)容的類,每個(gè)蜘蛛都能處理一個(gè)域名或一組域名��。換句話說就是用來定義特定網(wǎng)站的抓取和解析規(guī)則����。
5.Item Pipeline(項(xiàng)目管道)
項(xiàng)目管道的主要責(zé)任是負(fù)責(zé)處理有蜘蛛從網(wǎng)頁中抽取的項(xiàng)目���,它的主要任務(wù)是清晰���、驗(yàn)證和存儲(chǔ)數(shù)據(jù)��。當(dāng)頁面被蜘蛛解析后����,將被發(fā)送到項(xiàng)目管道�,并經(jīng)過幾個(gè)特定的次序處理數(shù)據(jù)。每個(gè)項(xiàng)目管道的組件都是有一個(gè)簡單的方法組成的Python類�����。它們獲取了項(xiàng)目并執(zhí)行它們的方法�,同時(shí)還需要確定的是是否需要在項(xiàng)目管道中繼續(xù)執(zhí)行下一步或是直接丟棄掉不處理。
項(xiàng)目管道通常執(zhí)行的過程有:
清洗HTML數(shù)據(jù) 驗(yàn)證解析到的數(shù)據(jù)(檢查項(xiàng)目是否包含必要的字段) 檢查是否是重復(fù)數(shù)據(jù)(如果重復(fù)就刪除) 將解析到的數(shù)據(jù)存儲(chǔ)到數(shù)據(jù)庫中
6.Middlewares(中間件)
中間件是介于Scrapy引擎和其他組件之間的一個(gè)鉤子框架���,主要是為了提供一個(gè)自定義的代碼來拓展Scrapy的功能�����。
PS2:Scrapy的數(shù)據(jù)處理流程
Scrapy的整個(gè)數(shù)據(jù)處理流程有Scrapy引擎進(jìn)行控制���,其主要的運(yùn)行方式為:
引擎打開一個(gè)域名�����,時(shí)蜘蛛處理這個(gè)域名���,并讓蜘蛛獲取第一個(gè)爬取的URL。
引擎從蜘蛛那獲取第一個(gè)需要爬取的URL�����,然后作為請求在調(diào)度中進(jìn)行調(diào)度����。
引擎從調(diào)度那獲取接下來進(jìn)行爬取的頁面。
調(diào)度將下一個(gè)爬取的URL返回給引擎����,引擎將它們通過下載中間件發(fā)送到下載器。
當(dāng)網(wǎng)頁被下載器下載完成以后�,響應(yīng)內(nèi)容通過下載中間件被發(fā)送到引擎。
引擎收到下載器的響應(yīng)并將它通過蜘蛛中間件發(fā)送到蜘蛛進(jìn)行處理�。
蜘蛛處理響應(yīng)并返回爬取到的項(xiàng)目,然后給引擎發(fā)送新的請求���。
引擎將抓取到的項(xiàng)目項(xiàng)目管道�,并向調(diào)度發(fā)送請求。
系統(tǒng)重復(fù)第二部后面的操作�����,直到調(diào)度中沒有請求���,然后斷開引擎與域之間的聯(lián)系。
CDA數(shù)據(jù)分析師考試相關(guān)入口一覽(建議收藏):
? 想報(bào)名CDA認(rèn)證考試����,點(diǎn)擊>>>
“CDA報(bào)名”
了解CDA考試詳情;
? 想學(xué)習(xí)CDA考試教材��,點(diǎn)擊>>> “CDA教材” 了解CDA考試詳情��;
? 想加入CDA考試題庫����,點(diǎn)擊>>> “CDA題庫” 了解CDA考試詳情;
? 想了解CDA考試含金量��,點(diǎn)擊>>> “CDA含金量” 了解CDA考試詳情�;











 京公網(wǎng)安備 11010802034615號
經(jīng)營許可證編號:京B2-20210330
京公網(wǎng)安備 11010802034615號
經(jīng)營許可證編號:京B2-20210330