python中實現(xiàn)k-means聚類算法詳解
這篇文章主要介紹了python中實現(xiàn)k-means聚類算法詳解,具有一定參考價值���,需要的朋友可以了解下���。
算法優(yōu)缺點:
優(yōu)點:容易實現(xiàn)
缺點:可能收斂到局部最小值,在大規(guī)模數(shù)據(jù)集上收斂較慢
使用數(shù)據(jù)類型:數(shù)值型數(shù)據(jù)
算法思想
k-means算法實際上就是通過計算不同樣本間的距離來判斷他們的相近關(guān)系的�,相近的就會放到同一個類別中去。
1.首先我們需要選擇一個k值�,也就是我們希望把數(shù)據(jù)分成多少類,這里k值的選擇對結(jié)果的影響很大,Ng的課說的選擇方法有兩種一種是elbow
method��,簡單的說就是根據(jù)聚類的結(jié)果和k的函數(shù)關(guān)系判斷k為多少的時候效果最好��。另一種則是根據(jù)具體的需求確定����,比如說進行襯衫尺寸的聚類你可能就會考慮分成三類(L,M,S)等
2.然后我們需要選擇最初的聚類點(或者叫質(zhì)心),這里的選擇一般是隨機選擇的���,代碼中的是在數(shù)據(jù)范圍內(nèi)隨機選擇����,另一種是隨機選擇數(shù)據(jù)中的點�。這些點的選擇會很大程度上影響到最終的結(jié)果,也就是說運氣不好的話就到局部最小值去了�。這里有兩種處理方法,一種是多次取均值����,另一種則是后面的改進算法(bisecting
K-means)
3.終于我們開始進入正題了,接下來我們會把數(shù)據(jù)集中所有的點都計算下與這些質(zhì)心的距離����,把它們分到離它們質(zhì)心最近的那一類中去��。完成后我們則需要將每個簇算出平均值�����,用這個點作為新的質(zhì)心����。反復(fù)重復(fù)這兩步�,直到收斂我們就得到了最終的結(jié)果�����。
函數(shù)
loadDataSet(fileName)
從文件中讀取數(shù)據(jù)集
distEclud(vecA, vecB)
計算距離�,這里用的是歐氏距離,當(dāng)然其他合理的距離都是可以的
randCent(dataSet, k)
隨機生成初始的質(zhì)心���,這里是雖具選取數(shù)據(jù)范圍內(nèi)的點
kMeans(dataSet, k, distMeas=distEclud, createCent=randCent)
kmeans算法����,輸入數(shù)據(jù)和k值�。后面兩個事可選的距離計算方式和初始質(zhì)心的選擇方式
show(dataSet, k, centroids, clusterAssment)
可視化結(jié)果
#coding=utf-8
from numpy import *
def loadDataSet(fileName):
dataMat = []
fr = open(fileName)
for line in fr.readlines():
curLine = line.strip().split('\t')
fltLine = map(float, curLine)
dataMat.append(fltLine)
return dataMat
#計算兩個向量的距離,用的是歐幾里得距離
def distEclud(vecA, vecB):
return sqrt(sum(power(vecA - vecB, 2)))
#隨機生成初始的質(zhì)心(ng的課說的初始方式是隨機選K個點)
def randCent(dataSet, k):
n = shape(dataSet)[1]
centroids = mat(zeros((k,n)))
for j in range(n):
minJ = min(dataSet[:,j])
rangeJ = float(max(array(dataSet)[:,j]) - minJ)
centroids[:,j] = minJ + rangeJ * random.rand(k,1)
return centroids
def kMeans(dataSet, k, distMeas=distEclud, createCent=randCent):
m = shape(dataSet)[0]
clusterAssment = mat(zeros((m,2)))#create mat to assign data points
#to a centroid, also holds SE of each point
centroids = createCent(dataSet, k)
clusterChanged = True
while clusterChanged:
clusterChanged = False
for i in range(m):#for each data point assign it to the closest centroid
minDist = inf
minIndex = -1
for j in range(k):
distJI = distMeas(centroids[j,:],dataSet[i,:])
if distJI < minDist:
minDist = distJI; minIndex = j
if clusterAssment[i,0] != minIndex:
clusterChanged = True
clusterAssment[i,:] = minIndex,minDist**2
print centroids
for cent in range(k):#recalculate centroids
ptsInClust = dataSet[nonzero(clusterAssment[:,0].A==cent)[0]]#get all the point in this cluster
centroids[cent,:] = mean(ptsInClust, axis=0) #assign centroid to mean
return centroids, clusterAssment
def show(dataSet, k, centroids, clusterAssment):
from matplotlib import pyplot as plt
numSamples, dim = dataSet.shape
mark = ['or', 'ob', 'og', 'ok', '^r', '+r', 'sr', 'dr', ' for i in xrange(numSamples):
markIndex = int(clusterAssment[i, 0])
plt.plot(dataSet[i, 0], dataSet[i, 1], mark[markIndex])
mark = ['Dr', 'Db', 'Dg', 'Dk', '^b', '+b', 'sb', 'db', ' for i in range(k):
plt.plot(centroids[i, 0], centroids[i, 1], mark[i], markersize = 12)
plt.show()
def main():
dataMat = mat(loadDataSet('testSet.txt'))
myCentroids, clustAssing= kMeans(dataMat,4)
print myCentroids
show(dataMat, 4, myCentroids, clustAssing)
if __name__ == '__main__':
main()
這里是聚類結(jié)果,還是很不錯的啦

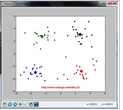
但是有時候也會收斂到局部最小值�,就像下面這樣�,就是不幸收斂到局部最優(yōu)了
總結(jié)
以上就是本文關(guān)于python中實現(xiàn)k-means聚類算法詳解的全部內(nèi)容���,希望對大家有所幫助
CDA數(shù)據(jù)分析師考試相關(guān)入口一覽(建議收藏):
? 想報名CDA認(rèn)證考試���,點擊>>>
“CDA報名”
了解CDA考試詳情;
? 想學(xué)習(xí)CDA考試教材���,點擊>>> “CDA教材” 了解CDA考試詳情��;
? 想加入CDA考試題庫����,點擊>>> “CDA題庫” 了解CDA考試詳情�����;
? 想了解CDA考試含金量�,點擊>>> “CDA含金量” 了解CDA考試詳情;











 京公網(wǎng)安備 11010802034615號
經(jīng)營許可證編號:京B2-20210330
京公網(wǎng)安備 11010802034615號
經(jīng)營許可證編號:京B2-20210330