R語言使用boosting方法對數(shù)據(jù)分類與交叉驗證
數(shù)據(jù)分類說明
與bagging方法類似,boosting算法也是先獲得簡單的分類器,然后通過調(diào)整錯分樣本的權(quán)重逐步改進分類器,使得后續(xù)分類器能夠?qū)W習(xí)前一輪分類器,adabag實現(xiàn)了AdaBoost.M1和SAMME兩個算法,因此用戶能夠使用adabag包實施集成學(xué)習(xí)。
數(shù)據(jù)分類操作
導(dǎo)入包
library(rpart)
library(adabag)
調(diào)用adabag包的boosting函數(shù)分類器:
churn.boost = boosting(churn ~ .,data = trainset,mfinal = 10,coeflearn = "Freund",boos = FALSE,control = rpart.control(maxdepth = 3))
使用boosting訓(xùn)練模型對測試數(shù)據(jù)集進行分類預(yù)測:
churn.boost.pred = predict.boosting(churn.boost,newdata = testset)
基于預(yù)測結(jié)果生成分類表:
churn.boost.pred$confusion
Observed Class
Predicted Class yes no
no 41 858
yes 100 19
根據(jù)分類結(jié)果計算平均誤差:
churn.boost.pred$error
[1] 0.0589391
數(shù)據(jù)分類原理
boosting算法的思想是通過對弱分類器(單一決策樹)的“逐步優(yōu)化”,使之成為強分類器。假定當(dāng)前在訓(xùn)練集中存在n個點�����,對其權(quán)重分別賦值Wj(0<= j < n),在迭代的學(xué)習(xí)過程中(假定迭代次數(shù)為m),我們將根據(jù)每次迭代的分類結(jié)果��,不斷調(diào)整這些點的權(quán)重����,如果當(dāng)前這些點分類是正確的,則調(diào)低其權(quán)值���,否則��,增加樣例點的權(quán)值�。這樣�,當(dāng)整個迭代過程結(jié)束時���,算法將得到m個合適的模型�,最終��,通過對每棵決策樹加權(quán)平均得到最后的預(yù)測結(jié)果���,權(quán)值b由每棵決策樹的分類質(zhì)量決定����。
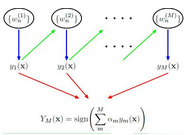
bagging和boosting都采用了集成學(xué)習(xí)的思想���,即將多個弱分類器組成強分類器�����,兩者的不同在于�����,bagging是組合獨立的模型��,而boosting則通過在迭代的過程學(xué)習(xí)的過程中盡可能用正確的分類模型來降低預(yù)測誤差�。與bagging類似,用戶也需要指定用于分類的模型的公式與分類數(shù)據(jù)集���,用戶還要自己指定諸如迭代次數(shù)(mfinal),權(quán)重更新系數(shù)(coeflearn)��、觀測值權(quán)重(boos)以及rpart的控制方法(單一決策樹)等參數(shù)�,本例中迭代次數(shù)為設(shè)置為10�,采用Freund(AdaBoost.M1算法實現(xiàn)的方法)作為系數(shù)(coeflearn),設(shè)置boos的值是“false”,最大深度為3。
交叉驗證說明
adabag包支持對boosting方法的交叉驗證�,該功能可以通過boosting.cv實現(xiàn)。
交叉驗證操作
獲得boosting方法交叉驗證后的最小估計錯誤:
調(diào)用boosting.cv對訓(xùn)練數(shù)據(jù)集實施交叉驗證:
churn.boost.cv = boosting.cv(churn ~ .,v = 10,data = trainset,mfinal = 5,control=rpart.control(cp = 0.01))
從boosting結(jié)果生成混淆矩陣
churn.boost.cv$confusion
Observed Class
Predicted Class yes no
no 103 1936
yes 239 37
得到boosting的平均誤差:
churn.boost.cv$error
[1] 0.06047516
交叉驗證原理
函數(shù)參數(shù)v值設(shè)置為10�����,mfinal的值設(shè)置為5�����,boosting算法會執(zhí)行一個5次迭代的10折交叉驗證,另外可以設(shè)置參數(shù)進行rpart的匹配控制�����。我們將復(fù)雜度參數(shù)設(shè)置為0.01���。
CDA數(shù)據(jù)分析師考試相關(guān)入口一覽(建議收藏):
? 想報名CDA認(rèn)證考試�����,點擊>>>
“CDA報名”
了解CDA考試詳情����;
? 想學(xué)習(xí)CDA考試教材��,點擊>>> “CDA教材” 了解CDA考試詳情��;
? 想加入CDA考試題庫�����,點擊>>> “CDA題庫” 了解CDA考試詳情��;
? 想了解CDA考試含金量�,點擊>>> “CDA含金量” 了解CDA考試詳情;











 京公網(wǎng)安備 11010802034615號
經(jīng)營許可證編號:京B2-20210330
京公網(wǎng)安備 11010802034615號
經(jīng)營許可證編號:京B2-20210330