邏輯回歸,決策樹����,支持向量機(jī) 選擇方案
分類是我們?cè)诠I(yè)界經(jīng)常遇到的場(chǎng)景,本文探討了3種常用的分類器�,邏輯回歸LR,決策樹DT和支持向量機(jī)SVM�����。
這三個(gè)算法都被廣泛應(yīng)用于分類(當(dāng)然LR,DT和SVR也可以用于回歸,但是本文先不討論)�����。我經(jīng)?����?吹饺藗儠?huì)問���,這個(gè)問題我該使用LR呢還是決策樹(或者GBDT)還是SVM呢�。然后你會(huì)聽到一個(gè)“經(jīng)典”而且“絕對(duì)正確”的答案:”It
depends.”這個(gè)答案簡(jiǎn)直毫無卵用�。所以本文將探討一下面臨模型選擇的時(shí)候到底depends on what。
接下來是一個(gè)簡(jiǎn)單的2-D的解釋���,至于向更高維度的擴(kuò)展延伸���,就靠你們了~
從最重要的問題入手:我們?cè)诜诸悤r(shí)想要做什么~聽起來很蠢有木有���,重新組織一下問題~為了完成分類����,我們嘗試得到一個(gè)分類邊界或者是一個(gè)你和曲線��,哪個(gè)方式能夠在我們的特征空間里更好的進(jìn)行分類呢?
特征空間聽起來很fancy�,看一個(gè)簡(jiǎn)單的例子,我有一些樣本數(shù)據(jù)�����,特征(x1,x2)和標(biāo)簽(0或1)。

可以看到我們的特征是2-D的��,不同的顏色代表著不同的類別標(biāo)簽�,我們想要使用算法來獲得一個(gè)曲線來區(qū)分這些不同類別的樣本。
其實(shí)可以很直觀的看出來����,這個(gè)場(chǎng)景下圓是一個(gè)比較理想的分類邊界。而不同的分類邊界也就是LR����,DT和SVM的區(qū)別所在。
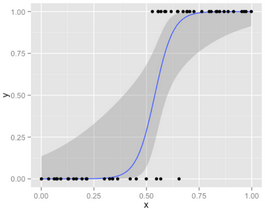
首先看一下邏輯回歸��,對(duì)于LR給出的決策邊界�,我們對(duì)于這個(gè)經(jīng)典的S型曲線會(huì)有不少困惑:

其實(shí)這個(gè)藍(lán)色的曲線并不是決策邊界,它只是把二分類的答案使用連續(xù)值輸出置信度的一個(gè)方式���,例如給出分類結(jié)果為1的置信度��。LR決策面其實(shí)是一條直線(高維情況下平面或超平面)��,為什么呢�����?
來看下邏輯回歸的公式:
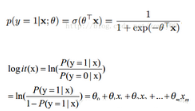
為了判定樣本屬于哪一類�����,需要設(shè)置一個(gè)截?cái)喾謹(jǐn)?shù)���,高于這個(gè)分?jǐn)?shù)就預(yù)測(cè)為正例�����,低于這個(gè)分?jǐn)?shù)就預(yù)測(cè)為負(fù)例���。例如階段分?jǐn)?shù)是c,所以我們的決策過程如下:
Y=1 當(dāng) p>c����,否則為0�。因而解決了之前的一個(gè)問題:LR的決策邊界其實(shí)是一條直線。
所以對(duì)于之前的數(shù)據(jù)集我們得到的LR的決策邊界如下:
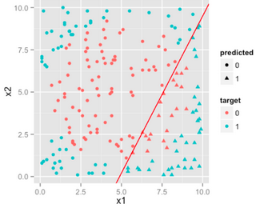
可以看出來LR的效果并不好�,因?yàn)椴还苣阍趺凑{(diào),決策邊界都是線性的�,無法擬合出來一個(gè)圓形的決策邊界,所以LR比較適合解決線性可分的問題(雖然你也可以通過對(duì)特征進(jìn)行變換從而使樣本數(shù)據(jù)線性可分����,但是目前不討論這個(gè)東西����,這個(gè)是特征工程的工作����,和模型沒關(guān)系)。
現(xiàn)在看一下決策樹的工作原理�,決策樹是按照單個(gè)變量進(jìn)行一層一層的規(guī)則過濾,例如:
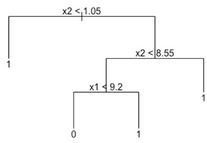
x1大于或小于const或者x2大于或小于某個(gè)const做的工作是使用直線來劃分特征空間�����,如下圖:
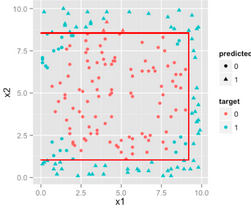
如果我們讓決策樹更復(fù)雜一點(diǎn)�,例如深度更大,則這些判斷條件能夠更細(xì)地劃分特征空間����,從而越來越逼近那個(gè)圓形的決策邊界。
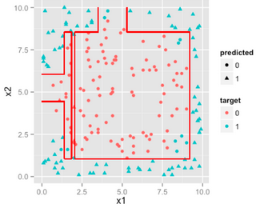
因此��,如果決策邊界是非線性的��,而且能夠通過矩形來劃分特征空間��,那么決策樹就是優(yōu)于LR的模型。
最后�,看一下SVM的工作模式,SVM通過核函數(shù)把特征空間映射到其他維度���,從而使得樣本數(shù)據(jù)線性可分����,換個(gè)說法��,SVM通過添加新的維度的特征從而使得樣本線性可分����。從下圖可以看到,當(dāng)把特征映射到另一個(gè)空間�����,那么一個(gè)決策面可以把數(shù)據(jù)區(qū)分開�����,換言之��,如果把這個(gè)決策面映射到初始特征空間��,我們就相當(dāng)于得到了一個(gè)非線性的決策邊界���。
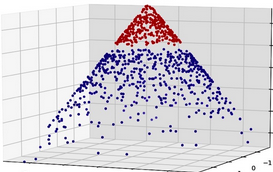
在原始的2-D的特征基礎(chǔ)上添加一個(gè)新的特征����,我們就可以通過一個(gè)平面���,使得這個(gè)3-D的樣本數(shù)據(jù)線性可分了(使用n-1維的超平面把n維的樣本分開)�����,如果把這個(gè)分類面投射到原始的2-D空間���,那么其實(shí)我們會(huì)得到一個(gè)圓哦,雖然這個(gè)分類邊界并不會(huì)像下圖這樣理想����,但是也是能夠逼近這個(gè)圓的。
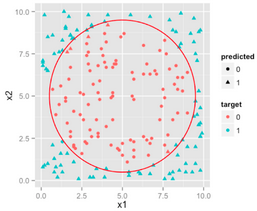
到這里我們大致明白了3個(gè)模型的工作原理�,但是一開始提出的問題并沒有解決,it depends on what? 什么情況下使用什么模型���,優(yōu)勢(shì)是什么���,劣勢(shì)又是什么����?我們下面來探討這個(gè)問題~
LR,DT,SVM都有自身的特性���,首先來看一下LR��,工業(yè)界最受青睞的機(jī)器學(xué)習(xí)算法�����,訓(xùn)練���、預(yù)測(cè)的高效性能以及算法容易實(shí)現(xiàn)使其能輕松適應(yīng)工業(yè)界的需求。LR還有個(gè)非常方便實(shí)用的額外功能就是它并不會(huì)給出離散的分類結(jié)果�,而是給出該樣本屬于各個(gè)類別的概率(多分類的LR就是softmax),可以嘗試不同的截?cái)喾绞絹碓谠u(píng)測(cè)指標(biāo)上進(jìn)行同一模型的性能評(píng)估,從而得到最好的截?cái)喾謹(jǐn)?shù)�。LR不管是實(shí)現(xiàn)還是訓(xùn)練或者預(yù)測(cè)都非常高效,很輕松的handle大規(guī)模數(shù)據(jù)的問題(同時(shí)LR也很適合online learning)���。此外��,LR對(duì)于樣本噪聲是robust的�,對(duì)于“mild”的多重共線性問題也不會(huì)受到太大影響���,在特征的多重共線性很強(qiáng)的情況下��,LR也可以通過L2正則化來應(yīng)對(duì)該問題����,雖然在有些情況下(想要稀疏特征)L2正則化并不太適用�����。
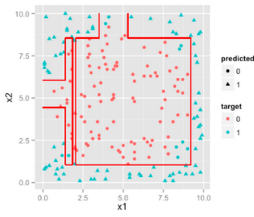
但是���,當(dāng)我們有大量的特征以及部分丟失數(shù)據(jù)時(shí)�,LR就開始費(fèi)勁了�����。太多的分類變量(變量值是定性的����,表現(xiàn)為互不相容的類別或?qū)傩裕缧詣e,年齡段(1,2,3,4,5)等)也會(huì)導(dǎo)致LR的性能較差(這個(gè)時(shí)候可以考慮做離散化��,其實(shí)肯定是要做離散化的)��。還有一種論調(diào)是LR使用所有的樣本數(shù)據(jù)用于訓(xùn)練�,這引發(fā)了一個(gè)爭(zhēng)論:明顯是正例或者負(fù)例的樣本(這種樣本離分類邊界較遠(yuǎn),不大會(huì)影響分類的curve)不太應(yīng)該被考慮太多�,模型理想情況是由分類邊界的樣本決定的(類似SVM的思想),如下圖����。還有一個(gè)情況就是當(dāng)特征是非線性時(shí),需要做特征變換�����,這可能會(huì)導(dǎo)致特征維度急劇上升�。下面是我認(rèn)為的LR的一些利弊:
LR的優(yōu)勢(shì):
對(duì)觀測(cè)樣本的概率值輸出
實(shí)現(xiàn)簡(jiǎn)單高效
多重共線性的問題可以通過L2正則化來應(yīng)對(duì)
大量的工業(yè)界解決方案
支持online learning(個(gè)人補(bǔ)充)
LR的劣勢(shì)
特征空間太大時(shí)表現(xiàn)不太好
對(duì)于大量的分類變量無能為力
對(duì)于非線性特征需要做特征變換
依賴所有的樣本數(shù)據(jù)(作者認(rèn)為這其實(shí)不是啥問題。��。)
接下來我們聊一下決策樹和SVM�����。
決策樹對(duì)于單調(diào)的特征變換是”indifferent”的����,也就是說特征的單調(diào)變換對(duì)于決策樹來說不會(huì)產(chǎn)生任何影響(我本人最早使用決策樹時(shí)沒有理解內(nèi)部的機(jī)制���,當(dāng)時(shí)還做了特征歸一化等工作�,發(fā)現(xiàn)效果沒有任何變化),因?yàn)?a href='/map/jueceshu/' style='color:#000;font-size:inherit;'>決策樹是通過簡(jiǎn)單的使用矩形切分特征空間的��,單調(diào)的特征變換只是做了特征空間的縮放而已���。由于決策樹是的分支生成是使用離散的區(qū)間或類別值的���,所以對(duì)于不管多少分類變量都能夠輕松適應(yīng),而且通過決策樹生成出來的模型很直觀而且容易解釋(隨著決策樹的分支解釋即可)����,而且決策樹也可以通過計(jì)算落到該葉子類目的標(biāo)簽平均值獲得最終類別的概率輸出。但是這就引發(fā)了決策樹的最大問題:非常容易過擬合��,我們很容易就會(huì)生成一個(gè)完美擬合訓(xùn)練集的模型�,但是該模型在測(cè)試集合上的表現(xiàn)卻很poor,所以這個(gè)時(shí)候就需要剪枝以及交叉驗(yàn)證來保證模型不要過擬合了��。
過擬合的問題還可以通過使用隨機(jī)森林的方式來解決�����,隨機(jī)森林是對(duì)決策樹的一個(gè)很smart的擴(kuò)展,即使用不同的特征集合和樣本集合生成多棵決策樹�����,讓它們來vote預(yù)測(cè)樣本的標(biāo)簽值����。但是隨機(jī)森林并沒有像單純決策樹一樣的解釋能力。
Also by decision trees have forced interactions between variables ,
which makes them rather inefficient if most of your variables have no
or very weak interactions. On the other hand this design also makes them
rather less susceptible to multicollinearity.
這段是在說決策樹也不會(huì)受到多重共線性的影響�,但是我本人不是很理解
DT的優(yōu)勢(shì):
直觀的決策過程
能夠處理非線性特征
考慮了特征相關(guān)性
DT的劣勢(shì)
極易過擬合(使用RF可以一定程度防止過擬合,但是只要是模型就會(huì)過擬合���!
無法輸出score�,只能給出直接的分類結(jié)果
最后談一下支持向量機(jī)SVM�,SVM最大的好處就是它只依賴于處于分類邊界的樣本來構(gòu)建分類面,可以處理非線性的特征����,同時(shí),只依賴于決策邊界的樣本還可以讓他們能夠應(yīng)對(duì)”obvious”樣本缺失的問題��。由于SVM能夠輕松搞定大規(guī)模的特征空間所以在文本分析等特征維度較高的領(lǐng)域是比較好的選擇�����。SVM的可解釋性并不像決策樹一樣直觀,如果使用非線性核函數(shù)�����,SVM的計(jì)算代價(jià)會(huì)高很多��。
SVM的優(yōu)勢(shì):
可以處理高維特征
使用核函數(shù)輕松應(yīng)對(duì)非線的性特征空間
分類面不依賴于所有數(shù)據(jù)
SVM的劣勢(shì)
對(duì)于大量的觀測(cè)樣本���,效率會(huì)很低找到一個(gè)“合適”的核函數(shù)還是很tricky的
我總結(jié)出了一個(gè)工作流程來讓大家參考如何決定使用哪個(gè)模型:
1. 使用LR試一把總歸不會(huì)錯(cuò)的,至少是個(gè)baseline
2. 看看決策樹相關(guān)模型例如隨機(jī)森林�,GBDT有沒有帶來顯著的效果提升,即使最終沒有用這個(gè)模型�,也可以用隨機(jī)森林的結(jié)果來去除噪聲特征
3. 如果你的特征空間和觀測(cè)樣本都很大,有足夠的計(jì)算資源和時(shí)間��,試試SVM吧�,
最后是這位老司機(jī)的一點(diǎn)人生經(jīng)驗(yàn):好的數(shù)據(jù)遠(yuǎn)比模型本身重要,記住一定要使用你在對(duì)應(yīng)領(lǐng)域的知識(shí)來進(jìn)行完備的特征工程的工作�;然后還有一個(gè)有效途徑就是多使用ensembles,就是多個(gè)模型混合�,給出結(jié)果。
個(gè)人想法:
本文加粗或者斜體字都是我自己的觀點(diǎn)和補(bǔ)充�����。本文提到了多重共線性和正則化,如果不知道這個(gè)的話�,是無法很好的理解這些內(nèi)容的,我后面會(huì)寫文章總結(jié)介紹一下多重共線性以及正則化相關(guān)的內(nèi)容~
CDA數(shù)據(jù)分析師考試相關(guān)入口一覽(建議收藏):
? 想報(bào)名CDA認(rèn)證考試��,點(diǎn)擊>>>
“CDA報(bào)名”
了解CDA考試詳情��;
? 想學(xué)習(xí)CDA考試教材��,點(diǎn)擊>>> “CDA教材” 了解CDA考試詳情���;
? 想加入CDA考試題庫(kù)�����,點(diǎn)擊>>> “CDA題庫(kù)” 了解CDA考試詳情�����;
? 想了解CDA考試含金量��,點(diǎn)擊>>> “CDA含金量” 了解CDA考試詳情���;











 京公網(wǎng)安備 11010802034615號(hào)
經(jīng)營(yíng)許可證編號(hào):京B2-20210330
京公網(wǎng)安備 11010802034615號(hào)
經(jīng)營(yíng)許可證編號(hào):京B2-20210330