一文讀懂聚類算法
1. 聚類的基本概念
1.1 定義
聚類是數(shù)據(jù)挖掘中的概念,就是按照某個(gè)特定標(biāo)準(zhǔn)(如距離)把一個(gè)數(shù)據(jù)集分割成不同的類或簇�����,使得同一個(gè)簇內(nèi)的數(shù)據(jù)對(duì)象的相似性盡可能大�,同時(shí)不在同一個(gè)簇中的數(shù)據(jù)對(duì)象的差異性也盡可能地大。也即聚類后同一類的數(shù)據(jù)盡可能聚集到一起�����,不同類數(shù)據(jù)盡量分離�����。
1.2 聚類與分類的區(qū)別
Clustering
(聚類),簡(jiǎn)單地說就是把相似的東西分到一組�,聚類的時(shí)候,我們并不關(guān)心某一類是什么��,我們需要實(shí)現(xiàn)的目標(biāo)只是把相似的東西聚到一起��。因此�,一個(gè)聚類算法通常只需要知道如何計(jì)算相似度就可以開始工作了�,因此
clustering 通常并不需要使用訓(xùn)練數(shù)據(jù)進(jìn)行學(xué)習(xí),這在Machine Learning中被稱作unsupervised learning
(無監(jiān)督學(xué)習(xí))����。
Classification
(分類)���,對(duì)于一個(gè)classifier���,通常需要你告訴它“這個(gè)東西被分為某某類”這樣一些例子,理想情況下����,一個(gè) classifier
會(huì)從它得到的訓(xùn)練集中進(jìn)行“學(xué)習(xí)”,從而具備對(duì)未知數(shù)據(jù)進(jìn)行分類的能力�����,這種提供訓(xùn)練數(shù)據(jù)的過程通常叫做supervised learning
(監(jiān)督學(xué)習(xí))。
1.3 聚類過程
數(shù)據(jù)準(zhǔn)備:包括特征標(biāo)準(zhǔn)化和降維;
特征選擇:從最初的特征中選擇最有效的特征,并將其存儲(chǔ)于向量中;
特征提?����。和ㄟ^對(duì)所選擇的特征進(jìn)行轉(zhuǎn)換形成新的突出特征;
聚類(或分組):首先選擇合適特征類型的某種距離函數(shù)(或構(gòu)造新的距離函數(shù))進(jìn)行接近程度的度量����,而后執(zhí)行聚類或分組;
聚類結(jié)果評(píng)估:是指對(duì)聚類結(jié)果進(jìn)行評(píng)估,評(píng)估主要有3種:外部有效性評(píng)估��、內(nèi)部有效性評(píng)估和相關(guān)性測(cè)試評(píng)估���。
1.4 衡量聚類算法優(yōu)劣的標(biāo)準(zhǔn)
處理大的數(shù)據(jù)集的能力;
處理任意形狀���,包括有間隙的嵌套的數(shù)據(jù)的能力;
算法處理的結(jié)果與數(shù)據(jù)輸入的順序是否相關(guān),也就是說算法是否獨(dú)立于數(shù)據(jù)輸入順序;
處理數(shù)據(jù)噪聲的能力;
是否需要預(yù)先知道聚類個(gè)數(shù)�����,是否需要用戶給出領(lǐng)域知識(shí);
算法處理有很多屬性數(shù)據(jù)的能力����,也就是對(duì)數(shù)據(jù)維數(shù)是否敏感����。
2. 聚類方法的分類
主要分為層次化聚類算法���,劃分式聚類算法��,基于密度的聚類算法����,基于網(wǎng)格的聚類算法��,基于模型的聚類算法等����。
2.1 層次化聚類算法
又稱樹聚類算法,透過一種層次架構(gòu)方式��,反復(fù)將數(shù)據(jù)進(jìn)行分裂或聚合��。典型的有BIRCH算法�����,CURE算法����,CHAMELEON算法,Sequence
data rough clustering算法,Between groups average算法,Furthest
neighbor算法,Neares neighbor算法等���。
典型凝聚型層次聚類:
先將每個(gè)對(duì)象作為一個(gè)簇����,然后合并這些原子簇為越來越大的簇���,直到所有對(duì)象都在一個(gè)簇中�����,或者某個(gè)終結(jié)條件被滿足���。
算法流程:
將每個(gè)對(duì)象看作一類,計(jì)算兩兩之間的最小距離;
將距離最小的兩個(gè)類合并成一個(gè)新類;
重新計(jì)算新類與所有類之間的距離;
重復(fù)2�、3,直到所有類最后合并成一類��。
2.2 劃分式聚類算法
預(yù)先指定聚類數(shù)目或聚類中心���,反復(fù)迭代逐步降低目標(biāo)函數(shù)誤差值直至收斂�,得到最終結(jié)果。K-means,K-modes-Huang,K-means-CP,MDS_CLUSTER,
Feature weighted fuzzy clustering�����,CLARANS等
經(jīng)典K-means算法流程:
隨機(jī)地選擇k個(gè)對(duì)象���,每個(gè)對(duì)象初始地代表了一個(gè)簇的中心;
對(duì)剩余的每個(gè)對(duì)象�,根據(jù)其與各簇中心的距離����,將它賦給最近的簇;
重新計(jì)算每個(gè)簇的平均值,更新為新的簇中心;
不斷重復(fù)2�、3,直到準(zhǔn)則函數(shù)收斂��。
2.3 基于模型的聚類算法
為每簇假定了一個(gè)模型���,尋找數(shù)據(jù)對(duì)給定模型的最佳擬合���,同一”類“的數(shù)據(jù)屬于同一種概率分布�����,即假設(shè)數(shù)據(jù)是根據(jù)潛在的概率分布生成的。主要有基于統(tǒng)計(jì)學(xué)模型的方法和基于神經(jīng)網(wǎng)絡(luò)模型的方法���,尤其以基于概率模型的方法居多����。一個(gè)基于模型的算法可能通過構(gòu)建反應(yīng)數(shù)據(jù)點(diǎn)空間分布的密度函數(shù)來定位聚類��?;谀P偷木垲愒噲D優(yōu)化給定的數(shù)據(jù)和某些數(shù)據(jù)模型之間的適應(yīng)性。
SOM神經(jīng)網(wǎng)絡(luò)算法:
該算法假設(shè)在輸入對(duì)象中存在一些拓?fù)浣Y(jié)構(gòu)或順序���,可以實(shí)現(xiàn)從輸入空間(n維)到輸出平面(2維)的降維映射�����,其映射具有拓?fù)?a href='/map/tezheng/' style='color:#000;font-size:inherit;'>特征保持性質(zhì),與實(shí)際的大腦處理有很強(qiáng)的理論聯(lián)系����。
SOM網(wǎng)絡(luò)包含輸入層和輸出層�����。輸入層對(duì)應(yīng)一個(gè)高維的輸入向量,輸出層由一系列組織在2維網(wǎng)格上的有序節(jié)點(diǎn)構(gòu)成�,輸入節(jié)點(diǎn)與輸出節(jié)點(diǎn)通過權(quán)重向量連接。學(xué)習(xí)過程中�����,找到與之距離最短的輸出層單元�����,即獲勝單元����,對(duì)其更新。同時(shí)�����,將鄰近區(qū)域的權(quán)值更新�����,使輸出節(jié)點(diǎn)保持輸入向量的拓?fù)?a href='/map/tezheng/' style='color:#000;font-size:inherit;'>特征��。
算法流程:
網(wǎng)絡(luò)初始化���,對(duì)輸出層每個(gè)節(jié)點(diǎn)權(quán)重賦初值;
將輸入樣本中隨機(jī)選取輸入向量����,找到與輸入向量距離最小的權(quán)重向量;
定義獲勝單元����,在獲勝單元的鄰近區(qū)域調(diào)整權(quán)重使其向輸入向量靠攏;
提供新樣本、進(jìn)行訓(xùn)練;
收縮鄰域半徑�����、減小學(xué)習(xí)率��、重復(fù)���,直到小于允許值�����,輸出聚類結(jié)果�����。
2.4 基于密度聚類算法
主要思想:
只要鄰近區(qū)域的密度(對(duì)象或數(shù)據(jù)點(diǎn)的數(shù)目)超過某個(gè)閾值���,就繼續(xù)聚類
擅于解決不規(guī)則形狀的聚類問題��,廣泛應(yīng)用于空間信息處理,SGC,GCHL�����,DBSCAN算法�����、OPTICS算法�����、DENCLUE算法�����。
DBSCAN:
對(duì)于集中區(qū)域效果較好���,為了發(fā)現(xiàn)任意形狀的簇,這類方法將簇看做是數(shù)據(jù)空間中被低密度區(qū)域分割開的稠密對(duì)象區(qū)域;一種基于高密度連通區(qū)域的基于密度的聚類方法����,該算法將具有足夠高密度的區(qū)域劃分為簇��,并在具有噪聲的空間數(shù)據(jù)中發(fā)現(xiàn)任意形狀的簇���。
2.5 基于網(wǎng)格的聚類算法
基于網(wǎng)格的方法把對(duì)象空間量化為有限數(shù)目的單元,形成一個(gè)網(wǎng)格結(jié)構(gòu)�����。所有的聚類操作都在這個(gè)網(wǎng)格結(jié)構(gòu)(即量化空間)上進(jìn)行�。這種方法的主要優(yōu)點(diǎn)是它的處理
速度很快�,其處理速度獨(dú)立于數(shù)據(jù)對(duì)象的數(shù)目,只與量化空間中每一維的單元數(shù)目有關(guān)�����。但這種算法效率的提高是以聚類結(jié)果的精確性為代價(jià)的�。經(jīng)常與基于密度的算法結(jié)合使用。
代表算法有STING算法�、CLIQUE算法、WAVE-CLUSTER算法等��。
2.6 新發(fā)展的方法
基于約束的方法:
真實(shí)世界中的聚類問題往往是具備多種約束條件的 ,
然而由于在處理過程中不能準(zhǔn)確表達(dá)相應(yīng)的約束條件�、不能很好地利用約束知識(shí)進(jìn)行推理以及不能有效利用動(dòng)態(tài)的約束條件 ,
使得這一方法無法得到廣泛的推廣和應(yīng)用。這里的約束可以是對(duì)個(gè)體對(duì)象的約束 , 也可以是對(duì)聚類參數(shù)的約束 ,
它們均來自相關(guān)領(lǐng)域的經(jīng)驗(yàn)知識(shí)���。該方法的一個(gè)重要應(yīng)用在于對(duì)存在障礙數(shù)據(jù)的二維空間數(shù)據(jù)進(jìn)行聚類��。 COD (Clustering with
Ob2structed Distance) 就是處理這類問題的典型算法 ,
其主要思想是用兩點(diǎn)之間的障礙距離取代了一般的歐氏距離來計(jì)算其間的最小距離��。
基于模糊的聚類方法:
基于模糊集理論的聚類方法�,樣本以一定的概率屬于某個(gè)類。比較典型的有基于目標(biāo)函數(shù)的模糊聚類方法���、基于相似性關(guān)系和模糊關(guān)系的方法�����、基于模糊等價(jià)關(guān)系的傳遞閉包方法�、基于模 糊圖論的最小支撐樹方法�,以及基于數(shù)據(jù)集的凸分解、動(dòng)態(tài)規(guī)劃和難以辨別關(guān)系等方法����。
FCM模糊聚類算法流程:
標(biāo)準(zhǔn)化數(shù)據(jù)矩陣;
建立模糊相似矩陣,初始化隸屬矩陣;
算法開始迭代�����,直到目標(biāo)函數(shù)收斂到極小值;
根據(jù)迭代結(jié)果��,由最后的隸屬矩陣確定數(shù)據(jù)所屬的類,顯示最后的聚類結(jié)果����。
基于粒度的聚類方法:
基于粒度原理,研究還不完善��。
量子聚類:
受物理學(xué)中量子機(jī)理和特性啟發(fā)����,可以用量子理論解決聚類記過依賴于初值和需要指定類別數(shù)的問題�����。一個(gè)很好的例子就是基于相關(guān)點(diǎn)的 Pott
自旋和統(tǒng)計(jì)機(jī)理提出的量子聚類模型��。它把聚類問題看做一個(gè)物理系統(tǒng)��。并且許多算例表明�����,對(duì)于傳統(tǒng)聚類算法無能為力的幾種聚類問題���,該算法都得到了比較滿意的結(jié)果���。
核聚類:
核聚類方法增加了對(duì)樣本特征的優(yōu)化過程�,利用 Mercer 核
把輸入空間的樣本映射到高維特征空間����,并在特征空間中進(jìn)行聚類。核聚類方法是普適的����,并在性能上優(yōu)于經(jīng)典的聚類算法,它通過非線性映射能夠較好地分辨�、提
取并放大有用的特征,從而實(shí)現(xiàn)更為準(zhǔn)確的聚類;同時(shí)�,算法的收斂速度也較快。在經(jīng)典聚類算法失效的情況下����,核聚類算法仍能夠得到正確的聚類。代表算法有SVDD算法�,SVC算法。
譜聚類:
首先根據(jù)給定的樣本數(shù)據(jù)集定義一個(gè)描述成對(duì)數(shù)據(jù)點(diǎn)相似度的親合矩陣,并計(jì)算矩陣的特征值和特征向量,然后選擇合適的特征向量聚類不同的數(shù)據(jù)點(diǎn)�。譜聚類算法最初用于計(jì)算機(jī)視覺、VLSI設(shè)計(jì)等領(lǐng)域,最近才開始用于機(jī)器學(xué)習(xí)中,并迅速成為國(guó)際上機(jī)器學(xué)習(xí)領(lǐng)域的研究熱點(diǎn)���。
譜聚類算法建立在圖論中的譜圖理論基礎(chǔ)上,其本質(zhì)是將聚類問題轉(zhuǎn)化為圖的最優(yōu)劃分問題,是一種點(diǎn)對(duì)聚類算法����。
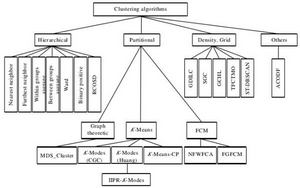
聚類算法簡(jiǎn)要分類架構(gòu)圖
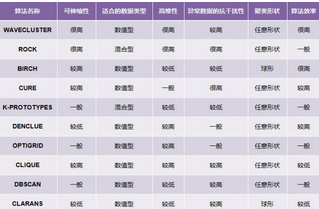
常用算法特點(diǎn)對(duì)比表
3. 簡(jiǎn)單的代碼示例

4. 學(xué)習(xí)資料
聚類算法屬于機(jī)器學(xué)習(xí)或數(shù)據(jù)挖掘領(lǐng)域內(nèi),范疇比較小���,一般都算作機(jī)器學(xué)習(xí)的一部分或數(shù)據(jù)挖掘領(lǐng)域中的一類算法����,可結(jié)合機(jī)器學(xué)習(xí)進(jìn)行學(xué)習(xí)
CDA數(shù)據(jù)分析師考試相關(guān)入口一覽(建議收藏):
? 想報(bào)名CDA認(rèn)證考試�,點(diǎn)擊>>>
“CDA報(bào)名”
了解CDA考試詳情;
? 想學(xué)習(xí)CDA考試教材�����,點(diǎn)擊>>> “CDA教材” 了解CDA考試詳情���;
? 想加入CDA考試題庫(kù),點(diǎn)擊>>> “CDA題庫(kù)” 了解CDA考試詳情����;
? 想了解CDA考試含金量,點(diǎn)擊>>> “CDA含金量” 了解CDA考試詳情�;











 京公網(wǎng)安備 11010802034615號(hào)
經(jīng)營(yíng)許可證編號(hào):京B2-20210330
京公網(wǎng)安備 11010802034615號(hào)
經(jīng)營(yíng)許可證編號(hào):京B2-20210330