常用排序算法比較與分析
一�����、常用排序算法簡述
下面主要從排序算法的基本概念��、原理出發(fā),分別從算法的時(shí)間復(fù)雜度�、空間復(fù)雜度、算法的穩(wěn)定性和速度等方面進(jìn)行分析比較�。依據(jù)待排序的問題大小(記錄數(shù)量 n)的不同��,排序過程中需要的存儲(chǔ)器空間也不同����,由此將排序算法分為兩大類:【內(nèi)排序】、【外排序】����。
內(nèi)排序:指排序時(shí)數(shù)據(jù)元素全部存放在計(jì)算機(jī)的隨機(jī)存儲(chǔ)器RAM中��。
外排序:待排序記錄的數(shù)量很大����,以致內(nèi)存一次不能容納全部記錄��,在排序過程中還需要對(duì)外存進(jìn)行訪問的排序過程�����。
先了解一下常見排序算法的分類關(guān)系(見圖1-1)
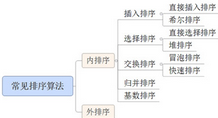
圖1-1 常見排序算法
二���、內(nèi)排序相關(guān)算法
2.1 插入排序
核心思想:將一個(gè)待排序的數(shù)據(jù)元素插入到前面已經(jīng)排好序的數(shù)列中的適當(dāng)位置��,使數(shù)據(jù)元素依然有序�����,直到待排序數(shù)據(jù)元素全部插入完為止���。
2.1.1 直接插入排序
核心思想:將欲插入的第i個(gè)數(shù)據(jù)元素的關(guān)鍵碼與前面已經(jīng)排序好的i-1、i-2 ����、i-3����、 … 數(shù)據(jù)元素的值進(jìn)行順序比較����,通過這種線性搜索的方法找到第i個(gè)數(shù)據(jù)元素的插入位置 ,并且原來位置 的數(shù)據(jù)元素順序后移��,直到全部排好順序�����。
直接插入排序中����,關(guān)鍵詞相同的數(shù)據(jù)元素將保持原有位置不變,所以該算法是穩(wěn)定的��,時(shí)間復(fù)雜度的最壞值為平方階O(n2)����,空間復(fù)雜度為常數(shù)階O(l)���。
Python源代碼:
-
#-------------------------直接插入排序--------------------------------
-
def insert_sort(data_list):
-
#遍歷數(shù)組中的所有元素�,其中0號(hào)索引元素默認(rèn)已排序,因此從1開始
-
for x in range(1, len(data_list)):
-
#將該元素與已排序好的前序數(shù)組依次比較�����,如果該元素小����,則交換
-
#range(x-1,-1,-1):從x-1倒序循環(huán)到0
-
for i in range(x-1, -1, -1):
-
#判斷:如果符合條件則交換
-
if data_list[i] > data_list[i+1]:
-
temp = data_list[i+1]
-
data_list[i+1] = data_list[i]
-
data_list[i] = temp
2.1.2 希爾排序
核心思想:是把記錄按下標(biāo)的一定增量分組,對(duì)每組使用直接插入排序算法排序;隨著增量逐漸減少�����,每組包含的關(guān)鍵詞越來越多���,當(dāng)增量減至1時(shí),整個(gè)文件恰被分成一組����,算法便終止。
希爾排序時(shí)間復(fù)雜度會(huì)比O(n2)好一些����,然而��,多次插入排序中���,第一次插入排序是穩(wěn)定的,但在不同的插入排序過程中���,相同的元素可能在各自的插入排序中移動(dòng)��,所以希爾排序是不穩(wěn)定的����。
Python源代碼:
-
#-------------------------希爾排序-------------------------------
-
def insert_shell(data_list):
-
#初始化step值�,此處利用序列長度的一半為其賦值
-
group = int(len(data_list)/2)
-
#第一層循環(huán):依次改變group值對(duì)列表進(jìn)行分組
-
while group > 0:
-
#下面:利用直接插入排序的思想對(duì)分組數(shù)據(jù)進(jìn)行排序
-
#range(group,len(data_list)):從group開始
-
for i in range(group, len(data_list)):
-
#range(x-group,-1,-group):從x-group開始與選定元素開始倒序比較,每個(gè)比較元素之間間隔group
-
for j in range(i-group, -1, -group):
-
#如果該組當(dāng)中兩個(gè)元素滿足交換條件��,則進(jìn)行交換
-
if data_list[j] > data_list[j+group]:
-
temp = data_list[j+group]
-
data_list[j+group] = data_list[j]
-
data_list[j] = temp
-
#while循環(huán)條件折半
-
group = int(group / 2)
2.2 選擇排序
核心思想:每一趟掃描時(shí)��,從待排序的數(shù)據(jù)元素中選出關(guān)鍵碼最小或最大的一個(gè)元素���,順序放在已經(jīng)排好順序序列的最后,直到全部待排序的數(shù)據(jù)元素排完為止���。
2.2.1 直接選擇排序
核心思想:給每個(gè)位置選擇關(guān)鍵碼最小的數(shù)據(jù)元素��,即:選擇最小的元素與第一個(gè)位置的元素交換����,然后在剩下的元素中再選擇最小的與第二個(gè)位置的元素交換,直到倒數(shù)第二個(gè)元素和最后一個(gè)元素比較為止��。
根據(jù)其基本思想���,每當(dāng)掃描一趟時(shí)��,如果當(dāng)前元素比一個(gè)元素小�����,而且這個(gè)小元素又出現(xiàn)在一個(gè)和當(dāng)前元素相等的元素后面����,則它們的位置發(fā)生了交換�����,所以直接選擇排序時(shí)不穩(wěn)定的,其時(shí)間復(fù)雜度為平方階O(n2)�����,空間復(fù)雜度為O(l)����。
Python源代碼:
-
#-------------------------直接選擇排序-------------------------------
-
def select_sort(data_list):
-
#依次遍歷序列中的每一個(gè)元素
-
for i in range(0, len(data_list)):
-
#將當(dāng)前位置的元素定義此輪循環(huán)當(dāng)中的最小值
-
minimum = data_list[i]
-
#將該元素與剩下的元素依次比較尋找最小元素
-
for j in range(i+1, len(data_list)):
-
if data_list[j] < minimum:
-
temp = data_list[j];
-
data_list[j] = minimum;
-
minimum = temp
-
#將比較后得到的真正的最小值賦值給當(dāng)前位置
-
data_list[i] = minimum
2.2.2 堆排序
堆排序時(shí)對(duì)直接選擇排序的一種有效改進(jìn)�����。
核心思想:將所有的數(shù)據(jù)建成一個(gè)堆�����,最大的數(shù)據(jù)在堆頂����,然后將堆頂?shù)臄?shù)據(jù)元素和序列的最后一個(gè)元素交換;接著重建堆、交換數(shù)據(jù)�,依次下去,從而實(shí)現(xiàn)對(duì)所有的數(shù)據(jù)元素的排序���。完成堆排序需要執(zhí)行兩個(gè)動(dòng)作:建堆和堆的調(diào)整��,如此反復(fù)進(jìn)行���。
堆排序有可能會(huì)使得兩個(gè)相同值的元素位置發(fā)生互換,所以是不穩(wěn)定的�����,其平均時(shí)間復(fù)雜度為0(nlog2n)��,空間復(fù)雜度為O(l)�����。
Python源代碼:
-
#-------------------------堆排序--------------------------------
-
#**********獲取左右葉子節(jié)點(diǎn)**********
-
def LEFT(i):
-
return 2*i + 1
-
-
def RIGHT(i):
-
return 2*i + 2
-
-
#********** 調(diào)整大頂堆 **********
-
#data_list:待調(diào)整序列 length: 序列長度 i:需要調(diào)整的結(jié)點(diǎn)
-
def adjust_max_heap(data_list,length,i):
-
#定義一個(gè)int值保存當(dāng)前序列最大值的下標(biāo)
-
largest = i
-
#執(zhí)行循環(huán)操作:兩個(gè)任務(wù):1 尋找最大值的下標(biāo)�����;2.最大值與父節(jié)點(diǎn)交換
-
while 1:
-
#獲得序列左右葉子節(jié)點(diǎn)的下標(biāo)
-
left, right = LEFT(i), RIGHT(i)
-
#當(dāng)左葉子節(jié)點(diǎn)的下標(biāo)小于序列長度 并且 左葉子節(jié)點(diǎn)的值大于父節(jié)點(diǎn)時(shí)��,將左葉子節(jié)點(diǎn)的下標(biāo)賦值給largest
-
if (left < length) and (data_list[left] > data_list[i]):
-
largest = left
-
#print('左葉子節(jié)點(diǎn)')
-
else:
-
largest = i
-
#當(dāng)右葉子節(jié)點(diǎn)的下標(biāo)小于序列長度 并且 右葉子節(jié)點(diǎn)的值大于父節(jié)點(diǎn)時(shí)�����,將右葉子節(jié)點(diǎn)的下標(biāo)值賦值給largest
-
if (right < length) and (data_list[right] > data_list[largest]):
-
largest = right
-
#print('右葉子節(jié)點(diǎn)')
-
#如果largest不等于i 說明當(dāng)前的父節(jié)點(diǎn)不是最大值,需要交換值
-
if (largest != i):
-
temp = data_list[i]
-
data_list[i] = data_list[largest]
-
data_list[largest] = temp
-
i = largest
-
#print(largest)
-
continue
-
else:
-
break
-
-
#********** 建立大頂堆 **********
-
def build_max_heap(data_list):
-
length = len(data_list)
-
for x in range(int((length-1)/2),-1,-1):
-
adjust_max_heap(data_list,length,x)
-
-
#********** 堆排序 **********
-
def heap_sort(data_list):
-
#先建立大頂堆����,保證最大值位于根節(jié)點(diǎn);并且父節(jié)點(diǎn)的值大于葉子結(jié)點(diǎn)
-
build_max_heap(data_list)
-
#i:當(dāng)前堆中序列的長度.初始化為序列的長度
-
i = len(data_list)
-
#執(zhí)行循環(huán):1. 每次取出堆頂元素置于序列的最后(len-1,len-2,len-3...)
-
# 2. 調(diào)整堆��,使其繼續(xù)滿足大頂堆的性質(zhì)�����,注意實(shí)時(shí)修改堆中序列的長度
-
while i > 0:
-
temp = data_list[i-1]
-
data_list[i-1] = data_list[0]
-
data_list[0] = temp
-
#堆中序列長度減1
-
i = i-1
-
#調(diào)整大頂堆
-
adjust_max_heap(data_list, i, 0)
2.3交換排序
核心思想:顧名思義���,就是一組待排序的數(shù)據(jù)元素中�,按照位置的先后順序相互比較各自的關(guān)鍵碼�����,如果是逆序��,則交換這兩個(gè)數(shù)據(jù)元素�����,直到該序列數(shù)據(jù)元素有序?yàn)橹埂?
2.3.1 冒泡排序
核心思想:對(duì)于待排序的一組數(shù)據(jù)元素����,把每個(gè)數(shù)據(jù)元素看作有重量的氣泡�,按照輕氣泡不能在重氣泡之下的原則���,將未排好順序的全部元素自上而下的對(duì)相鄰兩個(gè)元素依次進(jìn)行比較和調(diào)整��,讓較重的元素往下沉�,較輕的往上冒���。
根據(jù)基本思想,只有在兩個(gè)元素的順序與排序要求相反時(shí)才將調(diào)換它們的位置����,否則保持不變,所以冒泡排序時(shí)穩(wěn)定的���。時(shí)間復(fù)雜度為平方階O(n2)�����,空間復(fù)雜度為O(l)����。
Python源代碼:
-
#-------------------------冒泡排序--------------------------------
-
def bubble_sort(data_list):
-
length = len(data_list)
-
#序列長度為length,需要執(zhí)行l(wèi)ength-1輪交換
-
for x in range(1,length):
-
#對(duì)于每一輪交換�����,都將序列當(dāng)中的左右元素進(jìn)行比較
-
#每輪交換當(dāng)中�����,由于序列最后的元素一定是最大的��,因此每輪循環(huán)到序列未排序的位置即可
-
for i in range(0,length-x):
-
if data_list[i] > data_list[i+1]:
-
temp = data_list[i]
-
data_list[i] = data_list[i+1]
-
data_list[i+1] = temp
2.3.2 快速排序
快速排序是對(duì)冒泡排序本質(zhì)上的改進(jìn)��。
核心思想:是一個(gè)就地排序�����,分而治之�����,大規(guī)模遞歸的算法�。即:通過一趟掃描后確保基準(zhǔn)點(diǎn)的這個(gè)數(shù)據(jù)元素的左邊元素都比它小�����、右邊元素都比它大,接著又以遞歸方法處理左右兩邊的元素����,直到基準(zhǔn)點(diǎn)的左右只有一個(gè)元素為止。
快速排序時(shí)一個(gè)不穩(wěn)定的算法��,其最壞值的時(shí)間復(fù)雜度為平方階O(n2)�����,空間復(fù)雜度為O(log2n)�����。
Python源代碼:
-
#-------------------------快速排序--------------------------------
-
#data_list:待排序的序列�;start排序的開始index,end序列末尾的index
-
#對(duì)于長度為length的序列:start = 0;end = length-1
-
def quick_sort(data_list,start,end):
-
if start < end:
-
i , j , pivot = start, end, data_list[start]
-
while i < j:
-
#從右開始向左尋找第一個(gè)小于pivot的值
-
while (i < j) and (data_list[j] >= pivot):
-
j = j-1
-
#將小于pivot的值移到左邊
-
if (i < j):
-
data_list[i] = data_list[j]
-
i = i+1
-
#從左開始向右尋找第一個(gè)大于pivot的值
-
while (i < j) and (data_list[i] < pivot):
-
i = i+1
-
#將大于pivot的值移到右邊
-
if (i < j):
-
data_list[j] = data_list[i]
-
j = j-1
-
#循環(huán)結(jié)束后���,說明 i=j��,此時(shí)左邊的值全都小于pivot,右邊的值全都大于pivot
-
#pivot的位置移動(dòng)正確���,那么此時(shí)只需對(duì)左右兩側(cè)的序列調(diào)用此函數(shù)進(jìn)一步排序即可
-
#遞歸調(diào)用函數(shù):依次對(duì)左側(cè)序列:從0 ~ i-1//右側(cè)序列:從i+1 ~ end
-
data_list[i] = pivot
-
#左側(cè)序列繼續(xù)排序
-
quick_sort(data_list,start,i-1)
-
#右側(cè)序列繼續(xù)排序
-
quick_sort(data_list,i+1,end)
2.4歸并排序
核心思想:把數(shù)據(jù)序列遞歸地分成短序列,即把1分成2����、2分成4����、依次分解���,當(dāng)分解到只有1個(gè)一組的時(shí)候排序這些分組�����,然后依次合并回原來的序列�,不斷合并直到原序列全部排好順序���。
合并過程中可以確保兩個(gè)相等的當(dāng)前元素中�����,把處在前面的元素保存在結(jié)果序列的前面����,因此歸并排序是穩(wěn)定的�,其時(shí)間復(fù)雜度為O(nlog2n),空間復(fù)雜度為O(n)��。
Python源代碼:
-
#-------------------------歸并排序--------------------------------
-
#這是合并的函數(shù)
-
# 將序列data_list[first...mid]與序列data_list[mid+1...last]進(jìn)行合并
-
def mergearray(data_list,first,mid,last,temp):
-
#對(duì)i,j,k分別進(jìn)行賦值
-
i,j,k = first,mid+1,0
-
#當(dāng)左右兩邊都有數(shù)時(shí)進(jìn)行比較,取較小的數(shù)
-
while (i <= mid) and (j <= last):
-
if data_list[i] <= data_list[j]:
-
temp[k] = data_list[i]
-
i = i+1
-
k = k+1
-
else:
-
temp[k] = data_list[j]
-
j = j+1
-
k = k+1
-
#如果左邊序列還有數(shù)
-
while (i <= mid):
-
temp[k] = data_list[i]
-
i = i+1
-
k = k+1
-
#如果右邊序列還有數(shù)
-
while (j <= last):
-
temp[k] = data_list[j]
-
j = j+1
-
k = k+1
-
#將temp當(dāng)中該段有序元素賦值給data_list待排序列使之部分有序
-
for x in range(0,k):
-
data_list[first+x] = temp[x]
-
# 這是分組的函數(shù)
-
def merge_sort(data_list,first,last,temp):
-
if first < last:
-
mid = (int)((first + last) / 2)
-
#使左邊序列有序
-
merge_sort(data_list,first,mid,temp)
-
#使右邊序列有序
-
merge_sort(data_list,mid+1,last,temp)
-
#將兩個(gè)有序序列合并
-
mergearray(data_list,first,mid,last,temp)
-
# 歸并排序的函數(shù)
-
def merge_sort_array(data_list):
-
#聲明一個(gè)長度為len(data_list)的空列表
-
temp = len(data_list)*[None]
-
#調(diào)用歸并排序
-
merge_sort(data_list,0,len(data_list)-1,temp)
2.5 基數(shù)排序
核心思想:首先是低位排序��,然后收集;其次是高位排序�,然后再收集;依次類推,直到最高位��。
Python源代碼:
-
#-------------------------基數(shù)排序--------------------------------
-
#確定排序的次數(shù)
-
#排序的順序跟序列中最大數(shù)的位數(shù)相關(guān)
-
def radix_sort_nums(data_list):
-
maxNum = data_list[0]
-
#尋找序列中的最大數(shù)
-
for x in data_list:
-
if maxNum < x:
-
maxNum = x
-
#確定序列中的最大元素的位數(shù)
-
times = 0
-
while (maxNum > 0):
-
maxNum = (int)(maxNum/10)
-
times = times+1
-
return times
-
#找到num從低到高第pos位的數(shù)據(jù)
-
def get_num_pos(num,pos):
-
return ((int)(num/(10**(pos-1))))%10
-
#基數(shù)排序
-
def radix_sort(data_list):
-
count = 10*[None] #存放各個(gè)桶的數(shù)據(jù)統(tǒng)計(jì)個(gè)數(shù)
-
bucket = len(data_list)*[None] #暫時(shí)存放排序結(jié)果
-
#從低位到高位依次執(zhí)行循環(huán)
-
for pos in range(1,radix_sort_nums(data_list)+1):
-
#置空各個(gè)桶的數(shù)據(jù)統(tǒng)計(jì)
-
for x in range(0,10):
-
count[x] = 0
-
#統(tǒng)計(jì)當(dāng)前該位(個(gè)位�,十位,百位....)的元素?cái)?shù)目
-
for x in range(0,len(data_list)):
-
#統(tǒng)計(jì)各個(gè)桶將要裝進(jìn)去的元素個(gè)數(shù)
-
j = get_num_pos(int(data_list[x]),pos)
-
count[j] = count[j]+1
-
#count[i]表示第i個(gè)桶的右邊界索引
-
for x in range(1,10):
-
count[x] = count[x] + count[x-1]
-
#將數(shù)據(jù)依次裝入桶中
-
for x in range(len(data_list)-1,-1,-1):
-
#求出元素第K位的數(shù)字
-
j = get_num_pos(data_list[x],pos)
-
#放入對(duì)應(yīng)的桶中�,count[j]-1是第j個(gè)桶的右邊界索引
-
bucket[count[j]-1] = data_list[x]
-
#對(duì)應(yīng)桶的裝入數(shù)據(jù)索引-1
-
count[j] = count[j]-1
-
# 將已分配好的桶中數(shù)據(jù)再倒出來,此時(shí)已是對(duì)應(yīng)當(dāng)前位數(shù)有序的表
-
for x in range(0,len(data_list)):
-
data_list[x] = bucket[x]
三���、排序算法實(shí)測
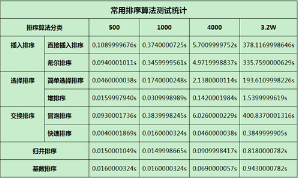
圖3-1 常用排序算法測試統(tǒng)計(jì)
四�、排序算法對(duì)比與分析
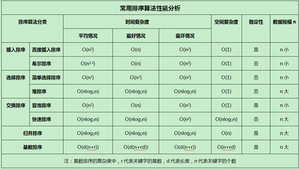
表4-1各個(gè)排序算法比較
[直接插入排序]是對(duì)冒泡排序的改進(jìn)�,比冒泡排序快,但是只適用于數(shù)據(jù)量較小(1000 ) 的排序
[希爾排序]比較簡單�,適用于小數(shù)據(jù)量(5000以下)的排序����,比直接插入排序快、冒泡排序快�,因此,希爾排序適用于小數(shù)據(jù)量的�����、排序速度要求不高的排序。
[直接選擇排序]和冒泡排序算法一樣�,適用于n值較小的場合,而且是排序算法發(fā)展的初級(jí)階段�����,在實(shí)際應(yīng)用中采用的幾率較小�。
[堆排序]比較適用于數(shù)據(jù)量達(dá)到百萬及其以上的排序,在這種情況下�,使用遞歸設(shè)計(jì)的快速排序和歸并排序可能會(huì)發(fā)生堆棧溢出的現(xiàn)象。
[冒泡排序]是最慢的排序算法��,是排序算法發(fā)展的初級(jí)階段��,實(shí)際應(yīng)用中采用該算法的幾率比較小�。
[快速排序]是遞歸的、速度最快的排序算法���,但是在內(nèi)存有限的情況下不是一個(gè)好的選擇;而且�,對(duì)于基本有序的數(shù)據(jù)序列排序���,快速排序反而變得比較慢��。
[歸并排序]比堆排序要快��,但是需要的存儲(chǔ)空間增加一倍�。
[基數(shù)排序]適用于規(guī)模n值很大的場合,但是只適用于整數(shù)的排序����,如果對(duì)浮點(diǎn)數(shù)進(jìn)行基數(shù)排序,則必須明確浮點(diǎn)數(shù)的存儲(chǔ)格式���,然后通過某種方式將其映射到整數(shù)上�,最后再映射回去�����,過程復(fù)雜�。
CDA數(shù)據(jù)分析師考試相關(guān)入口一覽(建議收藏):
? 想報(bào)名CDA認(rèn)證考試,點(diǎn)擊>>>
“CDA報(bào)名”
了解CDA考試詳情�;
? 想學(xué)習(xí)CDA考試教材,點(diǎn)擊>>> “CDA教材” 了解CDA考試詳情�;
? 想加入CDA考試題庫�����,點(diǎn)擊>>> “CDA題庫” 了解CDA考試詳情;
? 想了解CDA考試含金量���,點(diǎn)擊>>> “CDA含金量” 了解CDA考試詳情����;











 京公網(wǎng)安備 11010802034615號(hào)
經(jīng)營許可證編號(hào):京B2-20210330
京公網(wǎng)安備 11010802034615號(hào)
經(jīng)營許可證編號(hào):京B2-20210330