python編寫樸素貝葉斯用于文本分類
樸素貝葉斯估計
樸素貝葉斯是基于貝葉斯定理與特征條件獨立分布假設的分類方法。首先根據(jù)特征條件獨立的假設學習輸入/輸出的聯(lián)合概率分布�,然后基于此模型,對給定的輸入x����,利用貝葉斯定理求出后驗概率最大的輸出y。
具體的�����,根據(jù)訓練數(shù)據(jù)集�����,學習先驗概率的極大似然估計分布
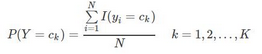
以及條件概率為
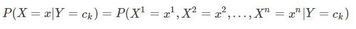
Xl表示第l個特征����,由于特征條件獨立的假設,可得
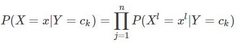
條件概率的極大似然估計為
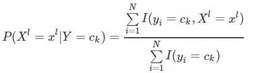
根據(jù)貝葉斯定理
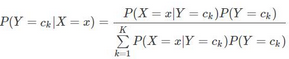
則由上式可以得到條件概率P(Y=ck|X=x)��。
貝葉斯估計
用極大似然估計可能會出現(xiàn)所估計的概率為0的情況�����。后影響到后驗概率結果的計算,使分類產生偏差��。采用如下方法解決����。
條件概率的貝葉斯改
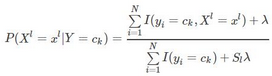
其中Sl表示第l個特征可能取值的個數(shù)�����。
同樣���,先驗概率的貝葉斯估計改為
$$
P(Y=c_k) = \frac{\sum\limits_{i=1}^NI(y_i=c_k)+\lambda}{N+K\lambda}
$K$
表示Y的所有可能取值的個數(shù)���,即類型的個數(shù)。
具體意義是���,給每種可能初始化出現(xiàn)次數(shù)為1����,保證每種可能都出現(xiàn)過一次�����,來解決估計為0的情況。
文本分類
樸素貝葉斯分類器可以給出一個最有結果的猜測值��,并給出估計概率��。通常用于文本分類���。
分類核心思想為選擇概率最大的類別����。貝葉斯公式如下:
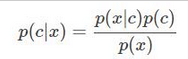
詞條:將每個詞出現(xiàn)的次數(shù)作為特征�����。
假設每個特征相互獨立���,即每個詞相互獨立���,不相關。則
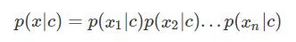
完整代碼如下;
import numpy as np
import re
import feedparser
import operator
def loadDataSet():
postingList=[['my', 'dog', 'has', 'flea', 'problems', 'help', 'please'],
['maybe', 'not', 'take', 'him', 'to', 'dog', 'park', 'stupid'],
['my', 'dalmation', 'is', 'so', 'cute', 'I', 'love', 'him'],
['stop', 'posting', 'stupid', 'worthless', 'garbage'],
['mr', 'licks', 'ate', 'my', 'steak', 'how', 'to', 'stop', 'him'],
['quit', 'buying', 'worthless', 'dog', 'food', 'stupid']]
classVec = [0,1,0,1,0,1] #1 is abusive, 0 not
return postingList,classVec
def createVocabList(data): #創(chuàng)建詞向量
returnList = set([])
for subdata in data:
returnList = returnList | set(subdata)
return list(returnList)
def setofWords2Vec(vocabList,data): #將文本轉化為詞條
returnList = [0]*len(vocabList)
for vocab in data:
if vocab in vocabList:
returnList[vocabList.index(vocab)] += 1
return returnList
def trainNB0(trainMatrix,trainCategory): #訓練���,得到分類概率
pAbusive = sum(trainCategory)/len(trainCategory)
p1num = np.ones(len(trainMatrix[0]))
p0num = np.ones(len(trainMatrix[0]))
p1Denom = 2
p0Denom = 2
for i in range(len(trainCategory)):
if trainCategory[i] == 1:
p1num = p1num + trainMatrix[i]
p1Denom = p1Denom + sum(trainMatrix[i])
else:
p0num = p0num + trainMatrix[i]
p0Denom = p0Denom + sum(trainMatrix[i])
p1Vect = np.log(p1num/p1Denom)
p0Vect = np.log(p0num/p0Denom)
return p0Vect,p1Vect,pAbusive
def classifyNB(vec2Classify,p0Vec,p1Vec,pClass1): #分類
p0 = sum(vec2Classify*p0Vec)+np.log(1-pClass1)
p1 = sum(vec2Classify*p1Vec)+np.log(pClass1)
if p1 > p0:
return 1
else:
return 0
def textParse(bigString): #文本解析
splitdata = re.split(r'\W+',bigString)
splitdata = [token.lower() for token in splitdata if len(token) > 2]
return splitdata
def spamTest():
docList = []
classList = []
for i in range(1,26):
with open('spam/%d.txt'%i) as f:
doc = f.read()
docList.append(doc)
classList.append(1)
with open('ham/%d.txt'%i) as f:
doc = f.read()
docList.append(doc)
classList.append(0)
vocalList = createVocabList(docList)
trainList = list(range(50))
testList = []
for i in range(13):
num = int(np.random.uniform(0,len(docList))-10)
testList.append(trainList[num])
del(trainList[num])
docMatrix = []
docClass = []
for i in trainList:
subVec = setofWords2Vec(vocalList,docList[i])
docMatrix.append(subVec)
docClass.append(classList[i])
p0v,p1v,pAb = trainNB0(docMatrix,docClass)
errorCount = 0
for i in testList:
subVec = setofWords2Vec(vocalList,docList[i])
if classList[i] != classifyNB(subVec,p0v,p1v,pAb):
errorCount += 1
return errorCount/len(testList)
def calcMostFreq(vocabList,fullText):
count = {}
for vocab in vocabList:
count[vocab] = fullText.count(vocab)
sortedFreq = sorted(count.items(),key=operator.itemgetter(1),reverse=True)
return sortedFreq[:30]
def localWords(feed1,feed0):
docList = []
classList = []
fullText = []
numList = min(len(feed1['entries']),len(feed0['entries']))
for i in range(numList):
doc1 = feed1['entries'][i]['summary']
docList.append(doc1)
classList.append(1)
fullText.extend(doc1)
doc0 = feed0['entries'][i]['summary']
docList.append(doc0)
classList.append(0)
fullText.extend(doc0)
vocabList = createVocabList(docList)
top30Words = calcMostFreq(vocabList,fullText)
for word in top30Words:
if word[0] in vocabList:
vocabList.remove(word[0])
trainingSet = list(range(2*numList))
testSet = []
for i in range(20):
randnum = int(np.random.uniform(0,len(trainingSet)-5))
testSet.append(trainingSet[randnum])
del(trainingSet[randnum])
trainMat = []
trainClass = []
for i in trainingSet:
trainClass.append(classList[i])
trainMat.append(setofWords2Vec(vocabList,docList[i]))
p0V,p1V,pSpam = trainNB0(trainMat,trainClass)
errCount = 0
for i in testSet:
testData = setofWords2Vec(vocabList,docList[i])
if classList[i] != classifyNB(testData,p0V,p1V,pSpam):
errCount += 1
return errCount/len(testData)
if __name__=="__main__":
ny = feedparser.parse('http://newyork.craigslist.org/stp/index.rss')
sf = feedparser.parse('http://sfbay.craigslist.org/stp/index.rss')
print(localWords(ny,sf))
編程技巧:
1.兩個集合的并集
vocab = vocab | set(document)
2.創(chuàng)建元素全為零的向量
vec = [0]*10
以上就是本文的全部內容�,希望對大家的學習有所幫助
CDA數(shù)據(jù)分析師考試相關入口一覽(建議收藏):
? 想報名CDA認證考試����,點擊>>>
“CDA報名”
了解CDA考試詳情�����;
? 想學習CDA考試教材,點擊>>> “CDA教材” 了解CDA考試詳情�����;
? 想加入CDA考試題庫����,點擊>>> “CDA題庫” 了解CDA考試詳情;
? 想了解CDA考試含金量����,點擊>>> “CDA含金量” 了解CDA考試詳情;











 京公網(wǎng)安備 11010802034615號
經營許可證編號:京B2-20210330
京公網(wǎng)安備 11010802034615號
經營許可證編號:京B2-20210330