從分類問題的提出至今,已經(jīng)衍生出了很多具體的分類技術�����。下面主要簡單介紹四種最常用的分類技術,不過因為原理和具體的算法實現(xiàn)及優(yōu)化不是本書的重點�����,所以我們盡量用應用人員能夠理解的語言來表述這些技術�。
在我們學習這些算法之前必須要清楚一點����,分類算法不會百分百準確。每個算法在測試集上的運行都會有一個準確率的指標���。用不同的算法做成的分類器(Classifier)在不同的數(shù)據(jù)集上也會有不同的表現(xiàn)�。
KNN��,K最近鄰算法
K最近鄰(K-Nearest Neighbor����,KNN)分類算法可以說是整個數(shù)據(jù)挖掘分類技術中最簡單的方法。所謂K最近鄰���,就是K個最近的鄰居�����,說的是每個樣本都可以用它最接近的K個鄰居來代表�。
我們用一個簡單的例子來說明KNN算法的概念���。如果您住在一個市中心的住宅內(nèi)����,周圍若干個小區(qū)的同類大小房子售價都在280萬到300萬之間�,那么我們可以把你的房子和它的近鄰們歸類到一起,估計也可以售280萬到300萬之間�����。同樣����,您的朋友住在郊區(qū),他周圍的同類房子售價都在110萬到120萬之間����,那么他的房子和近鄰的同類房子歸類之后,售價也在110 萬到120萬之間���。
KNN算法的核心思想是如果一個樣本在特征空間中的K個最相似的樣本中的大多數(shù)屬于某一個類別��,則該樣本也屬于這個類別��,并具有這個類別上樣本的特性����。該方法在確定分類決策上只依據(jù)最鄰近的一個或者幾個樣本的類別來決定待分樣本所屬的類別。
KNN方法在類別決策時����,只與極少量的相鄰樣本有關。由于KNN方法主要靠周圍有限的鄰近樣本�����,而不是靠判別類域的方法來確定所屬類別�,因此對于類域的交叉或重疊較多的待分樣本集來說,KNN方法較其他方法更為適合�����。
決策樹(Decision Tree)
如果說KNN是最簡單的方法��,那決策樹應該是最直觀最容易理解的分類算法��。最簡單的決策樹的形式是If-Then(如果-就)式的決策方式的樹形分叉。比如下面這樣一棵決策樹��,根據(jù)樣本的相貌和財富兩個屬性把所有樣本分成“高富帥”����、“帥哥”�、“高富”和“屌絲”四類。

決策樹上的每個節(jié)點要么是一個新的決策節(jié)點��,要么就是一個代表分類的葉子�����,而每一個分支則代表一個測試的輸出�。決策節(jié)點上做的是對屬性的判斷,而所有的葉子節(jié)點就是一個類別�����。決策樹要解決的問題就是用哪些屬性充當這棵樹的各個節(jié)點的問題����,而其中最關鍵的是根節(jié)點(Root Node),在它的上面沒有其他節(jié)點�,其他所有的屬性都是它的后續(xù)節(jié)點����。在上面的例子中�����,(obj.相貌==“帥”)就是根節(jié)點����,兩個(obj.財富>=1000000000)是根節(jié)點下一層的兩個決策節(jié)點,四個print標志著四個葉子節(jié)點�,各自對應一個類別。
所有的對象在進入決策樹之后根據(jù)各自的“相貌”和“財富”屬性都會被歸到四個分類中的某一類�����。
大多數(shù)分類算法(如下面要提的神經(jīng)網(wǎng)絡�、支持向量機等)都是一種類似于黑盒子式的輸出結果,你無法搞清楚具體的分類方式�����,而決策樹讓人一目了然�,十分方便。決策樹按分裂準則的不同可分為基于信息論的方法和最小GINI指標 (Gini Index)方法等。
神經(jīng)網(wǎng)絡(Neural Net)
在KNN算法和決策樹算法之后����,我們來看一下神經(jīng)網(wǎng)絡。神經(jīng)網(wǎng)絡就像是一個愛學習的孩子�,你教他的知識他不會忘記,而且會學以致用�。我們把學習集(Learning Set)中的每個輸入加到神經(jīng)網(wǎng)絡中,并告訴神經(jīng)網(wǎng)絡輸出應該是什么分類���。在全部學習集都運行完成之后,神經(jīng)網(wǎng)絡就根據(jù)這些例子總結出他自己的想法���,到底他是怎么歸納的就是一個黑盒了��。之后我們就可以把測試集(Testing Set)中的測試例子用神經(jīng)網(wǎng)絡來分別作測試�����,如果測試通過(比如80%或90%的正確率)�,那么神經(jīng)網(wǎng)絡就構建成功了���。我們之后就可以用這個神經(jīng)網(wǎng)絡來判斷事務的分類��。
神經(jīng)網(wǎng)絡是通過對人腦的基本單元——神經(jīng)元的建模和連接����,探索模擬人腦神經(jīng)系統(tǒng)功能的模型,并研制一種具有學習���、聯(lián)想�、記憶和模式識別等智能信息處理功能的人工系統(tǒng)�。神經(jīng)網(wǎng)絡的一個重要特性是它能夠從環(huán)境中學習,并把學習的結果分別存儲于網(wǎng)絡的突觸連接中�。神經(jīng)網(wǎng)絡的學習是一個過程,在其所處環(huán)境的激勵下�,相繼給網(wǎng)絡輸入一些樣本模式,并按照一定的規(guī)則(學習算法)調(diào)整網(wǎng)絡各層的權值矩陣��,待網(wǎng)絡各層權值都收斂到一定值�����,學習過程結束�。然后我們就可以用生成的神經(jīng)網(wǎng)絡來對真實數(shù)據(jù)做分類。
支持向量機SVM(Support Vector Machine)
和上面三種算法相比�����,支持向量機的說法可能會有一些抽象。我們可以這樣理解�����,盡量把樣本中的從更高的維度看起來在一起的樣本合在一起���,比如在一維(直線)空間里的樣本從二維平面上可以把它們分成不同類別���,而在二維平面上分散的樣本如果我們從第三維空間上來看就可以對它們做分類。支持向量機算法的目的是找到一個最優(yōu)超平面���,使分類間隔最大�。最優(yōu)超平面就是要求分類面不但能將兩類正確分開�,而且使分類間隔最大��。在兩類樣本中離分類面最近且位于平行于最優(yōu)超平面的超平面上的點就是支持向量��,為找到最優(yōu)超平面����,只要找到所有的支持向量即可。對于非線性支持向量機�,通常做法是把線性不可分轉(zhuǎn)化成線性可分,通過一個非線性映射將低維輸入空間中的數(shù)據(jù)特征映射到高維線性特征空間中,在高維空間中求線性最優(yōu)分類超平面����。
支持向量機算法是我們在做數(shù)據(jù)挖掘應用時很看重的一個算法,而原因是該算法自問世以來就被認為是效果最好的分類算法之一�。
分類算法的評估
在整個分類數(shù)據(jù)挖掘工作的最后階段,分類器(Classifier)的效果評價所占據(jù)的地位不容小視����,正如前文所述,沒有任何分類器能夠百分百的正確�����,任何分類算法都會發(fā)生一定的誤差��,而在大數(shù)據(jù)的情況下�����,有些數(shù)據(jù)的分類本身就是比較模糊的�����。因此在實際應用之前對分類器的效果進行評估顯得很重要���。
對分類器的效果評價方法有很多��,由于圖形化的展示方式更能為大家所接受�����,這里介紹兩種最常用的方式��,ROC曲線和Lift曲線來做分類器的評估��。
在介紹兩種曲線之前��,為了方便說明����,假設一個用于二分類的分類器最終得出的結果如表所示。
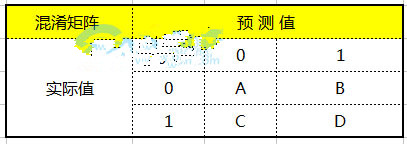
這張表通常被稱為混淆矩陣(Confusion Matrix)���。在實際應用中,常常把二分類中的具體類別用0和1表示�,其中1又常常代表我們關注的類別,比如直郵營銷中的最終消費客戶可以設定為1���,沒有轉(zhuǎn)化成功的客戶設為0�。通信行業(yè)客戶流失模型中的流失客戶可設置為1,沒有流失的客戶設置為0�。矩陣中的各個數(shù)字的具體含義為,A表示實際是0預測也是0的個數(shù)��,B表示實際是0卻預測成1的個數(shù)��,C表示實際是1預測是0的個數(shù)�,D表示實際是1預測也是1的個數(shù)。
下圖是一張ROC曲線圖�����,ROC曲線(Receiver Operating Characteristic Curve)是受試者工作特征曲線的縮寫��,該曲線常用于醫(yī)療臨床診斷�����,數(shù)據(jù)挖掘興起后也被用于分類器的效果評價���。
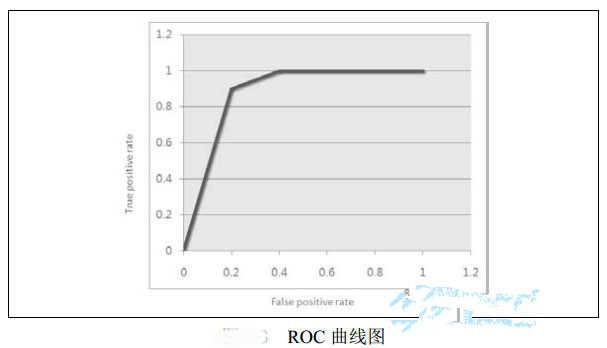
如上圖所示為一張很典型的ROC曲線圖���,從圖中可以看出該曲線的橫軸是FPR(False Positive Rate), 縱 軸是 TPR(True Positive Rate)�����。首先解釋一下這兩個指標的含義:TPR指的是實際為1預測也是1的概率,也就是混淆矩陣的D/(C+D)���,即正類(1)的查全率����。FPR指的是實際為0預測為1的概率即B/(A+B)����。
前面說過,分類中比較關心的都是正類的預測情況�,而且分類結果常常是以概率的形式出現(xiàn)的,設定一個閾值�,如果概率大于這個閾值那么結果就會是1。而ROC曲線的繪制過程就是根據(jù)這個閾值的變化而來的���,當閾值為0時��,所有的分類結果都是1�����,此時混淆矩陣中的C和A是0��,那 么TPR=1����,而FPR也是1��,這樣曲線達到終點���。隨著閾值的不斷增大����,被預測為1的個數(shù)會減少�����,TPR和FPR同時減少�����,當閾值增大到1時����,沒有樣本被預測為1,此時TPR和FPR都為0���。由此可知��,TPR和FPR是
同方向變化的�����,這點在上圖中可以得到體現(xiàn)���。
由于我們常常要求一個分類器的TPR盡量高����,F(xiàn)PR盡量小�����,表現(xiàn)在圖中就是曲線離縱軸越近��,預測效果就越好���。為了更具體化���,人們也通過計算AUC(ROC曲線下方的面積)來評判分類器效果,一般AUC超過0.7就說明分類器有一定效果。在上圖中的ROC曲線中�,曲線下方的面積AUC數(shù)值超過了0.7�����,所以分類器是有一定效果的��。
下面我們再來看Lift曲線的繪制�����。Lift曲線的繪制方法與ROC曲線是一樣的����,不同的是Lift曲線考慮的是分類器的準確性,也就是使用分類器獲得的正類數(shù)量和不使用分類器隨機獲取正類數(shù)量的比例�。以直郵營銷為例,分類器的好壞就在于與直接隨機抽取郵寄相比��,采用分類器的結果會給公司帶來多少響應客戶(即產(chǎn)生多少最終消費)���,所以Lift分類器在直郵營銷領域的應用是相對比較廣泛的��。
由下圖可以發(fā)現(xiàn)�,Lift曲線的縱軸是Lift值,它的計算公式是 ��,其中
��,其中
 �����,這個參數(shù)的含義是如果采用了分類器��,正類的識別比例�����;而
�����,這個參數(shù)的含義是如果采用了分類器��,正類的識別比例�����;而

���,表示如果不用分類器����,用隨機的方式抽取出正類的比例����。這二者相比自然就解決了如果使用者用分類器分類會使得正類產(chǎn)生的比例會增加多少的問題。Lift曲線的橫軸RPP(正類預測比例���,Rate of Positive Predictions)的計算公式是
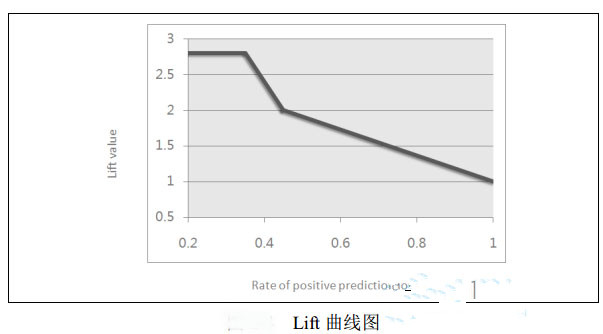
Lift曲線的繪制過程與ROC曲線類似���,不同的是Lift值和RPP是反方向變化的��,這才形成Lift 曲線與ROC曲線相反的形式��。
CDA數(shù)據(jù)分析師培訓官網(wǎng)
CDA數(shù)據(jù)分析師考試相關入口一覽(建議收藏):
? 想報名CDA認證考試���,點擊>>>
“CDA報名”
了解CDA考試詳情��;
? 想學習CDA考試教材�����,點擊>>> “CDA教材” 了解CDA考試詳情���;
? 想加入CDA考試題庫�,點擊>>> “CDA題庫” 了解CDA考試詳情�;
? 想了解CDA考試含金量,點擊>>> “CDA含金量” 了解CDA考試詳情���;











 京公網(wǎng)安備 11010802034615號
經(jīng)營許可證編號:京B2-20210330
京公網(wǎng)安備 11010802034615號
經(jīng)營許可證編號:京B2-20210330