谷歌教你學(xué) AI -第二講機器學(xué)習(xí)的7個步驟
Google Cloud發(fā)布了名為"AI Adventures"的系列視頻,用簡單易懂的語言讓初學(xué)者了解機器學(xué)習(xí)的方方面面��。
觀看更多國外公開課����,點擊"閱讀原文"
上一期主要講了機器學(xué)習(xí)的概念(谷歌教你學(xué) AI -第一講機器學(xué)習(xí)是什么?),今天讓我們一起看到第二講:機器學(xué)習(xí)的7個步驟���。
主講人還是來自Google Cloud的開發(fā)人員,華裔小哥Yufeng Guo��。讓我們在學(xué)習(xí)AI知識的同時來提高英語吧��。
CDA字幕組目前在對該系列視頻進行漢化�����,之后將繼續(xù)連載��,歡迎關(guān)注和支持~
附有中文字幕的視頻如下:
AI Adventures-第二講機器學(xué)習(xí)的7個步驟
針對不方便打開視頻的小伙伴�����,CDA字幕組也貼心的整理了文字版本����,如下:
從檢測皮膚癌到給黃瓜分類,以及檢測需要維修的電梯�,機器學(xué)習(xí)賦予了計算機系統(tǒng)全新的能力。但它的背后到底是如何運作的呢?我們來看一個簡單的例子�,并借此來聊一聊運用機器學(xué)習(xí)從你的數(shù)據(jù)中得到信息的過程。

歡迎來到Cloud AI Adventures����,我的名字叫Yufeng Guo。在這個節(jié)目里�,我們會探索機器學(xué)習(xí)的藝術(shù)性、科學(xué)性以及相關(guān)工具����。
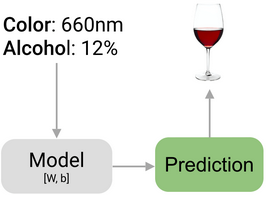
假設(shè)我們要構(gòu)建一個系統(tǒng)用來判斷酒水是紅酒還是啤酒。我們構(gòu)建的這個問答系統(tǒng)稱為模型�,構(gòu)建這個模型的過程稱為訓(xùn)練。
機器學(xué)習(xí)中訓(xùn)練的目的是建立一個準(zhǔn)確模型�����,在大多數(shù)情況下能夠地準(zhǔn)確回答問題�。但是為了訓(xùn)練這個模型,我們需要收集用于訓(xùn)練的數(shù)據(jù)����,這就是我們開始著手的地方��。
紅酒還是啤酒
我們通過裝著紅酒或啤酒的杯子來收集數(shù)據(jù)�����,酒水中包含了方方面面的數(shù)據(jù)信息�����。比如泡沫的數(shù)量、杯子的形狀等����。

但是出于我們的目的,只需要兩個簡單的信息����。顏色,記錄為光的波長���;酒精含量�����,記錄為百分比�����。希望僅僅通過這兩個因素�����,我們能夠分辨出這兩種酒�����。從現(xiàn)在開始我們把這兩點稱為特征��,顏色和酒精含量���。
第一步就是去雜貨店買各種不同的酒,以及用于測量的設(shè)備��。光譜儀用來衡量顏色�,比重計用來衡量酒精含量。

第1步:收集數(shù)據(jù)
一旦設(shè)備和酒都齊全了���,就可以開始進行機器學(xué)習(xí)真正的第一步:收集數(shù)據(jù)���。
這一步非常重要��,因為你所收集數(shù)據(jù)的質(zhì)量和數(shù)量將直接決定預(yù)測模型的效果�。這個例子里 我們收集的數(shù)據(jù)就是,每種酒水的顏色和酒精含量。
這樣我們就可以得出一個表格�����,關(guān)于每種酒的顏色和酒精含量���,是啤酒還是紅酒����。這將成為我們的訓(xùn)練數(shù)據(jù)。

第2步:數(shù)據(jù)準(zhǔn)備
經(jīng)過幾小時的測量�����,我們得到了訓(xùn)練數(shù)據(jù)��,也許還喝了幾杯��。下面是機器學(xué)習(xí)的第二步:數(shù)據(jù)準(zhǔn)備��。我們將數(shù)據(jù)加載到合適的地方����。進行處理從而用于機器學(xué)習(xí)的訓(xùn)練。
首先把所有數(shù)據(jù)放在一起�����,任意排列���。不要讓數(shù)據(jù)的順序影響到學(xué)習(xí)的效果�,排列并不是判斷酒水種類的因素。換句話說����,我們不想讓序列中酒水的前后排列順序,影響對酒水種類的判斷����。
這時也可以對數(shù)據(jù)進行相關(guān)可視化,幫助判斷不同變量之間是否存在相應(yīng)關(guān)系����,以及是否存在數(shù)據(jù)失衡。
例如���,如果我們收集的數(shù)據(jù)點中啤酒的數(shù)據(jù)要遠(yuǎn)多于紅酒���,那么訓(xùn)練出來的模型就會有嚴(yán)重的偏差����,偏向把酒水都判斷為啤酒。因為在大部分情況下這不會錯����。然而在實際情況中,模型會處理差不多數(shù)量的啤酒和紅酒�。意味著判斷為啤酒一半情況都是錯的。
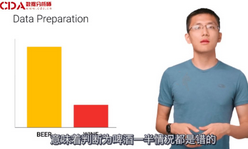
我們還需要把數(shù)據(jù)分成兩部分�����,用于訓(xùn)練模型的第一部分將是數(shù)據(jù)集的主要數(shù)據(jù)�;第二部分用于評估訓(xùn)練模型的效果。
我們不想把訓(xùn)練用的數(shù)據(jù)用于評估�����,因為模型會記住這些問題���。就像你不會把數(shù)學(xué)作業(yè)里的問題作為考試內(nèi)容一樣�。

有時我們收集的數(shù)據(jù)需要其他方式的調(diào)整和處理�����。比如去重���、標(biāo)準(zhǔn)化���、誤差修正等等��。這些都在數(shù)據(jù)準(zhǔn)備過程中進行�����。在這里我們不需要進一步的數(shù)據(jù)準(zhǔn)備�����,所以讓我們繼續(xù)�����。
第3步:選擇模型
我們工作流程的下一步是:選擇模型�。
在過去研究者和數(shù)據(jù)科學(xué)家���,已經(jīng)建立了很多模型��。有些非常適用于圖像數(shù)據(jù)����;有些適用于文字�����、音樂這種序列數(shù)據(jù)���;有的適用于數(shù)字?jǐn)?shù)據(jù)���,還有一些適用于文本數(shù)據(jù)。

這里我們只有兩個特征:顏色和酒精含量�����,我們用一個小型線性模型就足夠了�。這個模型很簡單但足以完成任務(wù)���。
第4步:訓(xùn)練
現(xiàn)在進行下一步,這通常被認(rèn)為是機器學(xué)習(xí)的主體部分:訓(xùn)練��。
這一步我們將用數(shù)據(jù)���,逐步提高模型預(yù)測酒水為紅酒或啤酒的能力。這有點類似初次學(xué)開車�,一開始初學(xué)者完全不知道踏板
把手����、開關(guān)的作用���,或者什么時候要用到����。但是經(jīng)過許多次的練習(xí)和糾錯�����,就能成為有駕照的司機了���。在開車一年之后就成為老司機了�。在現(xiàn)實中駕駛提高了駕駛水平,磨練了技術(shù)���。

針對酒水我們將從更小的范圍著手。直線方程是y=m*x+b。x是輸入,m是斜率�����,b是y軸截距���,y是直線x位置上的值�����。我們能夠調(diào)整和訓(xùn)練的值只有m和b�����,m是斜率�,b是y軸截距��。沒有其他改變直線位置的方式��,因為變量只有x輸入和y輸出���。

機器學(xué)習(xí)中可能存在很多m�����,因為有很多特征�。這些值通常構(gòu)成矩陣���,稱為w即權(quán)重矩陣���。類似的我們把b集合在一起,稱為偏差���。
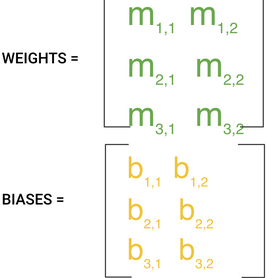
訓(xùn)練過程包含對w和b賦予一些隨機數(shù)初始化���,以及嘗試用這些值預(yù)測輸出�。可以想象一開始結(jié)果會很糟糕。但是我們可以將模型預(yù)測值與應(yīng)該得出的值進行比較,進而調(diào)整w和b的值�。這樣下一次能夠得出更準(zhǔn)確的預(yù)測�����。
然后不斷重復(fù)這個過程����。每次更新權(quán)重和變量的迭代或周期稱為一個訓(xùn)練步驟(training step)����。看看這對我們的數(shù)據(jù)集具體意味著什么�。
就像在數(shù)據(jù)中任意畫一條線。隨著訓(xùn)練的進展����,這條線一步步移動,逐步接近區(qū)分紅酒和啤酒的理想方式��。
第5步:評估
一旦訓(xùn)練完成��,就要進行評估����,查看模型的效果。
這時就要用到之前預(yù)留的數(shù)據(jù)�����。評估讓我們用訓(xùn)練中未使用的數(shù)據(jù)測試模型�����,這個指標(biāo)讓我們用新數(shù)據(jù)測試模型的性能����,這可以代表模型在現(xiàn)實情況中的效果�����。
根據(jù)經(jīng)驗法則�,我一般將訓(xùn)練和評估數(shù)據(jù)按照80/20或者70/30分配���。大多情況下取決于原始源數(shù)據(jù)集的大小�。如果數(shù)據(jù)很多可能就不需要太多的測試數(shù)據(jù)集��。

第6步:參數(shù)調(diào)整
完成評估之后你想看看是否能夠進一步提高訓(xùn)練�����?�?梢酝ㄟ^調(diào)整一部分參數(shù)��,我們隱含假設(shè)有一些參數(shù)在訓(xùn)練時已經(jīng)調(diào)整了?,F(xiàn)在可以回頭看看測試這些假設(shè),試試這些值���。
舉個例子,有一個參數(shù)我們可以調(diào)整����,即在訓(xùn)練中訓(xùn)練數(shù)據(jù)集運行了多少次��?�?梢远啻问褂眠@些數(shù)據(jù)����,從而提高精度��。
另外一個參數(shù)是學(xué)習(xí)率���,這規(guī)定了在每一步線移動的幅度�����。根據(jù)上一次訓(xùn)練步驟得到的信息�,這些值都會影響模型的準(zhǔn)確性以及訓(xùn)練時長��。

對于更復(fù)雜的模型�����,初始條件也會大大影響訓(xùn)練結(jié)果����。根據(jù)模型開始訓(xùn)練時���,初始值是為0還是其他值的分布以及分布是什么�����,得出的結(jié)果會有區(qū)別�。
可以看到訓(xùn)練的這一階段,有很多因素值得考慮��。重要的是要定義什么決定了模型的好壞��。否則將花很長的時間調(diào)整參數(shù)�。
這些參數(shù)通常被稱為超參數(shù)。調(diào)整超參數(shù)的過程比起科學(xué)更像是藝術(shù)���。這是實驗性的過程����,并很大程度上取決于具體的數(shù)據(jù)集�����、模型和訓(xùn)練過程��。
一旦滿意你的訓(xùn)練和超參數(shù)�����,通過評估步驟���,終于可以做一些有用的事情了��。
第7步:預(yù)測
機器學(xué)習(xí)用數(shù)據(jù)來解答問題��,因此預(yù)測或推斷就是解答問題的步驟����,這是所有工作的重點�����,即實現(xiàn)機器學(xué)習(xí)價值的地方。
我們終于可以用模型�����,根據(jù)顏色和酒精含量�����,預(yù)測酒水為紅酒還是啤酒��。
總結(jié)
機器學(xué)習(xí)的強大在于�,我們可以用模型來測定和區(qū)分紅酒與啤酒����,而不是通過人的主觀判斷或者經(jīng)驗。你可以把今天所講的概念�,拓展到適用這些規(guī)則的其他領(lǐng)域:
機器學(xué)習(xí)的7個步驟:
· 收集數(shù)據(jù)
· 準(zhǔn)備數(shù)據(jù)
· 選擇模型
· 訓(xùn)練
· 評估
· 超參數(shù)調(diào)整
· 預(yù)測
TensorFlow Playground
如果你想了解更多關(guān)于訓(xùn)練和參數(shù)的信息,可以訪問TensorFlow Playground����。這是完全基于瀏覽器的機器學(xué)習(xí)沙盒,你可以嘗試不同的參數(shù)���,用模擬數(shù)據(jù)進行訓(xùn)練�。不用擔(dān)心 ,你不會把網(wǎng)站崩掉��。
下期預(yù)告
當(dāng)然在之后的視頻中����,我們會遇到更多的步驟和區(qū)別��。但這作為幫我們理解問題很好的基本框架�,用通用的語言考慮每一步,并在以后更加深入��。
在下一期的AI adventures�,我們將用代碼構(gòu)建第一個真正的機器學(xué)習(xí)模型。
CDA數(shù)據(jù)分析師考試相關(guān)入口一覽(建議收藏):
? 想報名CDA認(rèn)證考試��,點擊>>>
“CDA報名”
了解CDA考試詳情�;
? 想學(xué)習(xí)CDA考試教材,點擊>>> “CDA教材” 了解CDA考試詳情����;
? 想加入CDA考試題庫,點擊>>> “CDA題庫” 了解CDA考試詳情��;
? 想了解CDA考試含金量�����,點擊>>> “CDA含金量” 了解CDA考試詳情;











 京公網(wǎng)安備 11010802034615號
經(jīng)營許可證編號:京B2-20210330
京公網(wǎng)安備 11010802034615號
經(jīng)營許可證編號:京B2-20210330